
1.REALM:言語特徴表現モデルに検索機能を持たせる(2/2)まとめ
・REALMでは、最適なドキュメントの選択は、最大内積検索を使っている
・REALMはOpen-QAタスクで30倍以上のパラメータを持つT5を約4ポイント上回った
・画像や他言語テキストなど他の形式の知識から検索する事などが今後の研究課題
2.REALMの性能
以下、ai.googleblog.comより「REALM: Integrating Retrieval into Language Representation Models」の意訳です。元記事の投稿は2020年8月12日、Ming-Wei ChangさんとKelvin Guuさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Dorian Mongel on Unsplash
REALMの計算上の課題
モデルが数百万のドキュメントから知識を取得できるようにREALMの事前トレーニングの規模を拡大する事は困難です。REALMでは、最適なドキュメントの選択は、最大内積検索(MIPS:Maximum Inner Product Search)として定式化されます。
検索を実行するには、MIPSモデルは最初に全てのドキュメントをエンコードして、各ドキュメントが対応するドキュメントベクトルを持つようにする必要があります。 検索文が到着すると、それは検索文ベクトルとしてエンコードされます。MIPSでは、検索文を指定すると、次の図に示すように、ドキュメントベクトルと検索文ベクトルの間の最大内積値を持つドキュメントがもっとも近い意味を持つドキュメントとして取得されます。
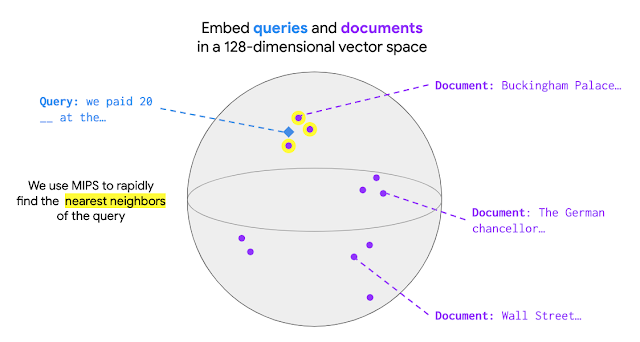
REALMをオープンドメインの質問回答に適用する
自然言語処理で最も知識集約的なタスクの1つである「オープンドメインの質問回答(Open-QA)」に適用する事により、REALMの有効性を評価します。このタスクの目標は「正三角形の角度は幾つですか?」などのジャンルを固定しない様々な質問に答えることです。
標準的な質問回答タスク(SQuADやNatural Questionsなど)では、サポートドキュメント(本文)が提供されるため、モデルはサポートドキュメントの文脈を紐解いて回答を捜するだけで済みます。
Open-QAでは参照元となるドキュメントが存在しないため、Open-QAモデルは自分で知識を検索する必要があります。この違いにより、Open-QAはREALMの有効性を調べる優れたタスクになります。
次の図は、Natural QuestionのOpen-QAバージョンの結果を示しています。 主に結果をT5と比較しました。これは、注釈付きのサポートドキュメントなしでモデルをトレーニングする別のアプローチです。 この図から、REALMの事前トレーニングが非常に強力なOpen-QAモデルを生成し、少ないパラメータ(3億)で、はるかに大きなパラメータ(110億)を持つT5モデルよりも約4ポイント優れた結果を出している事が明確に見てとれます。
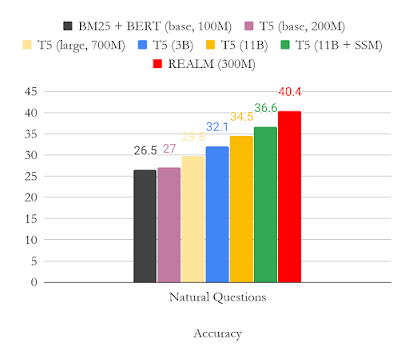
結論
REALMのリリースは、最近の検索拡張生成モデル(retrieval-augmented generative model)を含む、エンドツーエンドの検索拡張モデル(retrieval-augmented models)の開発への関心を高めるのに役立ちました。この一連の研究をいくつかの方法で拡張できないか期待しています。
(1)REALMに似た手法を「知識集約的な推論(knowledge-intensive reasoning)」と「由来が解釈可能である事(interpretable provenance)」を必要とする新しいアプリケーションに適用する事(オープンドメインの質問回答を超える)
(2)画像、ナレッジグラフ構造、または他言語のテキストなど、他の形式の知識から検索することの利点を探ります。
また、オープンソースとして公開したREALMを使用して研究コミュニティが何をするかを見て興奮します!
謝辞
この研究は、Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat そして Ming-Wei Changとの共同作業です。
3.REALM:言語特徴表現モデルに検索機能を持たせる(2/2)関連リンク
1)ai.googleblog.com
REALM: Integrating Retrieval into Language Representation Models
2)arxiv.org
REALM: Retrieval-Augmented Language Model Pre-Training
3)github.com
language/language/realm/


コメント