
1.ScaNN:効率的なベクトル類似性検索(2/2)まとめ
・重要なアイデアは距離が長くなるエンコーディングを使うと精度が高くなる可能性がある事
・最終的に異方性ベクトル量子化で優れた精度を最先端のパフォーマンスを実現
・ScaNNはオープンソースソフトウェアとして公開されておりGitHubで自分で試す事が可能
2.anisotropic vector quantizationとは?
以下、ai.googleblog.comより「Announcing ScaNN: Efficient Vector Similarity Search」の意訳です。元記事は2020年7月28日、Philip Sunさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Rebekah Blocker on Unsplash
MIPSに新しい量子化アプローチを適用
MIPSの最先端の実装のいくつかは、データベース内の項目を圧縮する事で行われており、これにより内積の概算は、総当たり方式に必要な時間の何分の1かで計算できます。この圧縮は通常、「学習した量子化(learned quantization)」を使用して行われます。ここでいう学習した量子化とは、データベースからベクトルを圧縮するためのコードブック(訳注:例えばAAAと言う並びが頻出しているのであったらそれをaで表現する等のルールを学習してやれば1/3に圧縮できる。これらのルールをまとめたものがcodebookのイメージ)をトレーニングする事で、これによりデータベース内の要素をほぼ近似して表すために使用できます。
従来のベクトル量子化は、各ベクトルxとその量子化された形式x̃との間の平均距離を最小化することを目的として、データベース内の要素を量子化しました。
これは有用な基準ですが、これを最適化することは、最近傍検索精度を最適化することと同じ意味ではありません。私達の論文の背後にある重要なアイデアは、平均距離が長くなるようなエンコーディングを使うと実際にはMIPSの精度が高くなる可能性があるということです。
私達の研究結果を以下で直感的に説明します。
データベース内に2つのembedding、x1とx2があり、それぞれを2つの中心点c1またはc2のいずれかに量子化する必要があるとします。
私達の目標は、内積<q、x̃i>が元の内積<q、xi>にできるだけ類似するように、各xiをx̃iに量子化することです。
これは、x̃iのqへの射影の大きさを、xiのqへの射影と可能な限り同じにする事として視覚化できます。
量子化への従来のアプローチ(左図)では、各xiに最も近い中心点を選択するため、2つの点の相対順位が正しくなくなります。<q、x̃1>は<q、x̃2>よりも大きいですが、<q 、x1>は<q、x2>より小さいです! 代わりにx1をc1に、x2をc2に割り当てると、正しい順序が得られます。 これを下の図に示します。
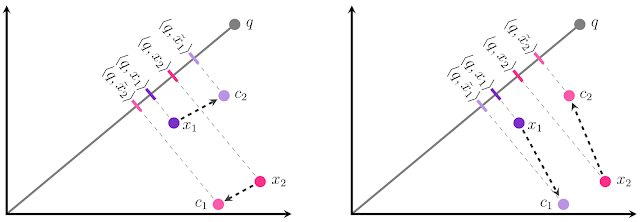
目標は、各xiをx̃i = c1またはx̃i = c2に量子化することです。従来の量子化(左)では、この検索ではx1とx2の順序が正しくありません。私達のアプローチ(右)はデータポイントからより離れた中心を選択していますが、これは実際には内積誤差の低下と精度の向上につながります。
方向だけでなく大きさも重要であることがわかります。
c1がx1からc2よりも離れている場合でも、c1はx1からx1にほぼ完全に直交する方向にズレていますが、c2のズレは平行になっています。(x2も、同じく反転しています)
平行方向のエラーは、MIPSが正確に推定しようとしている結果である内積に不釣り合いな影響を与えるため、MIPS問題でははるかに有害です。
この直感に基づいて、元のベクトルの平行な量子化誤差に更に大きなペナルティを課します。損失関数の方向依存性のため、私達はこの新しい量子化手法を異方性ベクトル量子化(anisotropic vector quantization)と呼んでいます。高い内積での優れた精度と、より低い内積での量子化誤差の増加を交換するこの手法の能力は、今回の主要な技術革新とそのパフォーマンス向上の源です。
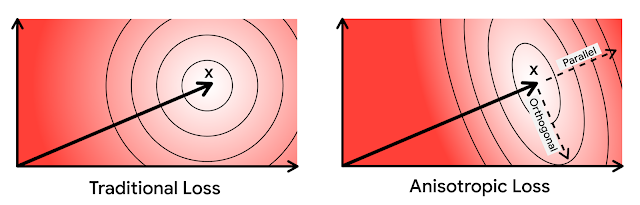
上の図で、楕円は等損失の等高線を示しています。
異方性ベクトル量子化では、元のデータポイントxに平行なエラーはさらにペナルティが課されます。
ScaNNにおける異方性ベクトル量子化
異方性ベクトル量子化により、ScaNNはtop-k(上位k番目までの意) MIPS結果に含まれる可能性が高い内積をより正確に推定できるため、より高い精度を実現できます。ann-benchmarks.comのglove-100-angularベンチマークでは、ScaNNは他の11の慎重に調整されたベクトル類似性検索ライブラリよりも優れており、精度を固定した状態では二位のライブラリより1秒あたり約2倍の検索を処理できました。
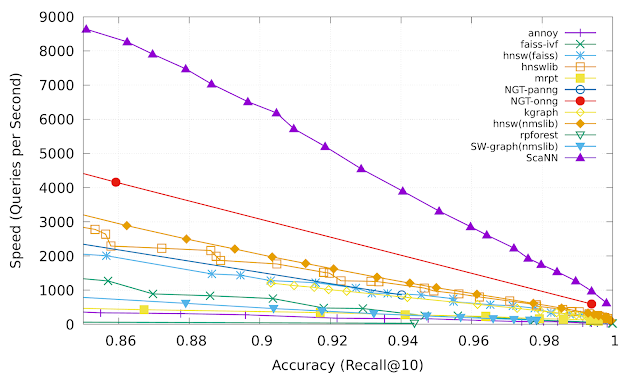
Recall@kとは、最近傍探索の精度に一般的に使用される基準です。これは、アルゴリズムが返すk個の近傍内に存在する真の最も近いk個の近傍の比率を測定します。ScaNN(上の紫色の線)は、速度と精度のトレードオフが発生する様々なポイントで優れたパフォーマンスを一貫して達成します。
ScaNNはオープンソースソフトウェアとして公開されており、GitHubで自分で試すことができます。ライブラリはPipを介して直接インストールでき、TensorFlowとNumpyの両方の入力用のインターフェースを備えています。ScaNNのインストールと構成の詳細については、GitHubのリポジトリを参照してください。
結論
MIPSの目標に合わせてベクトル量子化目標を変更することにより、embeddingベースの検索パフォーマンスの主要な指標である最近傍検索ベンチマークで最先端のパフォーマンスを実現しました。異方性ベクトル量子化は重要な手法ですが、圧縮時の歪みの是正する事は中間的な目標です。今回の研究は検索精度を向上させるという最終目標に向けてアルゴリズムを最適化する事で達成できるパフォーマンス向上の一例にすぎないと考えています。
謝辞
この投稿は、ScaNNチーム全体の作業を反映したものです。David Simcha, Erik Lindgren, Felix Chern, Nathan Cordeiro, Ruiqi Guo, Sanjiv Kumar, および Zonglin Li。また、Dan Holtmann-Rice, Dave Dopson, 及び Felix Yuにも感謝します。
3.ScaNN:効率的なベクトル類似性検索(2/2)関連リンク
1)ai.googleblog.com
Announcing ScaNN: Efficient Vector Similarity Search
2)arxiv.org
Accelerating Large-Scale Inference with Anisotropic Vector Quantization
3)github.com
google-research/scann/

