
1.定型書式から必要な情報を自動で抽出(2/2)まとめ
・モデルはほとんどの項目でうまく機能したがdelivery_date(配達日)には改善の余地があった
・これは今回使用した学習データにはdelivery_dateが余り含まれていなかったためであった
・Document AI製品に含まれる請求書解析サービスに今回の手法は取り込まれている
2.Google CloudのDocument AIの実装
以下、ai.googleblog.comより「Extracting Structured Data from Templatic Documents」の意訳です。元記事の投稿は2020年6月12日、Sandeep Tataさんによる投稿です。
アイキャッチ画像はのクレジットはPhoto by Serafima Lazarenko on Unsplash
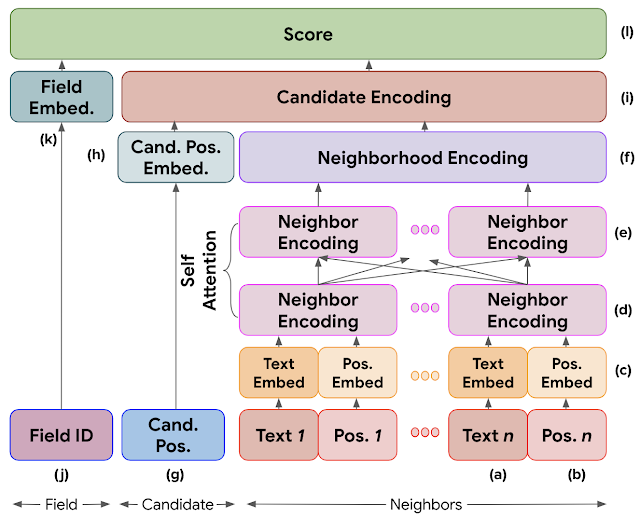
モデルのアーキテクチャ
以下の図は、ネットワークの全般的な構造を示しています。
候補エンコーディング(i)を構築するために、近傍の各トークンは、単語embeddingテーブル(a)を使用してベクトル化されます。
近傍のトークンの相対位置(b)は、きめ細かい非線形性を捉えるために2つの完全接続ReLU層を使用してベクトル化されます。
各トークンの文と位置を表現するembeddingは、近傍embedding(d)を形成するために連結されます。
自己注意メカニズム(self attention mechanism)を使用して、各近傍embeddingの文脈(e)を近隣エンコーディング(f)に結合します。
ページ上の候補の絶対位置(g)を、近傍の位置embeddingと同様の方法でベクトル化し、近隣エンコーディングと連結し、候補エンコーディング(i)となります。
最後のスコアリングレイヤーは、項目のembedding(k)と候補エンコーディング(i)の間のコサイン類似度を計算し、それを0~1の間の数値で表します。
結果
トレーニングと検証には、様々なレイアウトの請求書データセットを内製して使用しました。
トレーニングデータセット内に存在しないレイアウトにモデルが対応できているか機能をテストするために、トレーニングデータと検証データから切り出した請求書をテストセットとして使用しました。
このシステムで抽出したいくつかの重要な項目とそのF1スコア(高いほど良い)を、以下に示します。
| 項目名 | F1 Score |
| amount_due | 0.801 |
| delivery_date | 0.667 |
| due_date | 0.861 |
| invoice_date | 0.94 |
| invoice_id | 0.949 |
| purchase_order | 0.896 |
| total_amount | 0.858 |
| total_tax_amount | 0.839 |
上の表からわかるように、モデルはほとんどの項目でうまく機能します。ただし、delivery_date(配達日)などの項目には改善の余地があります。追加の調査により、この項目は今回使用した学習データの内の非常に小さなサブセット内に存在することが判明しました。追加の学習用データを収集することで、パフォーマンスが改善する事を期待しています。
次にやる事は何ですか?
Google Cloudは最近、Document AI製品の一部として請求書解析サービスを発表しました。 このサービスは、BERTなどの他の最近の研究の進歩と、上で説明した手法を使用して、請求書から12を超える主要な項目を抽出します。デモページで請求書をアップロードして、この技術の動作を確認できます!
任意のタイプの定型文書について、適度なサイズのラベル付きデータ指定する事で、抽出システムを自動構築できるようになる事を期待しています。データ効率の向上、入れ子構造の項目や繰り返される項目などの正確な処理、適切な候補ジェネレーターを定義するのが難しい項目など、現在私たちが追求しているいくつかの後続課題があります。
謝辞
この作業は、Google ResearchとGoogle Cloudの複数のエンジニアとのコラボレーションでした。Google ResearchのNavneet Potti, James Wendt, Marc Najork, Qi Zhao, Ivan Kuznetsov、およびCloud AIチームのLauro Costa, Evan Huang, Will Lu, Lukas Rutishauser, Mu Wang, and Yang Xuのサポートに感謝します。
そして最後に、私達のリサーチインターンであるBodhisattwa MajumderとBeliz Gunelの数十のアイデアと精力的な実験に対して感謝します。
3.定型書式から必要な情報を自動で抽出(2/2)関連リンク
1)ai.googleblog.com
Extracting Structured Data from Templatic Documents
2)research.google
Representation Learning for Information Extraction from Form-like Documents

