
1.Chemome initiative:機械学習を使って有用なタンパク質を探る試み(2/2)まとめ
・従来のRFを使った手法と比べて今回のGCNNモデルは大幅な性能向上を達成していた
・有望分子を選択するプロセスは簡単に自動化できるため人間によるレビューを省略できた
・規模の拡大も可能であり3つのターゲット全体で過去最大規模の約2000分子のテストを実施できた
2.Chemome initiativeとは?
以下、ai.googleblog.comより「Unlocking the “Chemome” with DNA-Encoded Chemistry and Machine Learning」の意訳です。元記事の投稿は2020年6月11日、Patrick Rileyさんによる投稿です。
アイキャッチ画像のクレジットはアメリカ国立がん研究所
DELデータを機械学習
特定のタンパク質について物理的に調べた結果である物理スクリーニングデータを使って、任意に選択された小分子がそのタンパク質に結合するかどうかを予測するMLモデルを構築します。
DELによる物理スクリーニングは、ML分類器にポジティブな例とネガティブな例を提供します。
少し簡単に言えば、スクリーニングプロセスの最後に残る小さな分子がポジティブな例であり、その他はすべてネガティブな例です。
ここで、グラフ畳み込みニューラルネットワーク(GCNN:Graph Convolutional Neural Network)を使用します。GCNNは、今回の分類対象となる小分子のような、小さくグラフに似た入力を取り扱うように特別に設計されたタイプのニューラルネットワークです。
結果
DELライブラリを使用して3つのタンパク質、sEH(加水分解酵素)、ERα(核内受容体)、c-KIT(キナーゼ)を物理スクリーニングしました。
DELトレーニング済みモデルを使用して、Mculeの大規模なオンデマンドライブラリとX-Chemの内部分子ライブラリをバーチャルスクリーニングし、各ターゲットに親和性を示すと予測される分子の多様なセットを特定しました。
更にGCNNモデルの結果をランダムフォレスト(RF)モデルと比較しました。RFは、特定の分子の存在を示す際に使われる標準的なバーチャルスクリーニング法です。 GCNNモデルは、RFモデルを大幅に上回っており、より強力な候補を発見する事ができます。
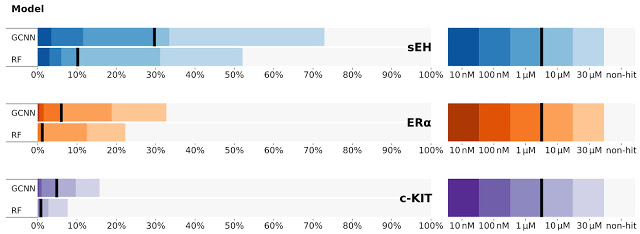
さまざまなレベルの活性を示す、小さな化学フラグメントの割合(ヒット率)
3つの異なるタンパク質をターゲットにした、2つの異なる機械学習モデル(GCNNとRF)の予測を比較しています。
右側のカラースケールは、分子の効力を表すために一般的な基準IC50を使用しています。
nMは「ナノモル」を意味し、µMは「マイクロモル」を意味します。 一般的に値が小さいほど、色が暗いほど、分子が優れている事を意味します。DELデータを使用せずに構築された一般的なバーチャルススクリーニングアプローチは、通常、数パーセントにしか達しないことに注意してください。
重要な事は、他の多くの仮想スクリーニングとは異なり、テストする分子を選択するプロセスは自動化されているか、モデルの出力結果を考慮して簡単に自動化できた事です。従来は必要であった熟練した化学者が最も有望な分子をレビューし、選択する作業に依存しませんでした。
更に、3つのターゲット全体で約2000の分子をテストしました。これは、私たちが知る限りバーチャルススクリーニングで最大規模の研究です。
前述の通り高い信頼性を持つヒット率を提供する一方で、ヒットの多様性により、トレーニングセットに近い分子と遠い分子のモデルの有用性を注意深く調べることもできます。
The Chemome Initiative
ZebiAI Therapeuticsがこの研究成果に基づいて設立され、私達のチームとX-Chem Pharmaceuticalsが提携して、これらの技術を適用して、、人のタンパク質を研究するコミュニティに新しい効率的な化学的探査装置を提供します。これがChemome Initiativeと呼ばれる取り組みです。
Chembi Initiativeの一環として、ZebiAIは研究者と協力して目標タンパク質の特定とスクリーニングデータに関する作業を行います。私達のチームはこれらのデータを使用して、機械学習モデルを構築し、商業利用可能な低分子ライブラリーの予測を行います。
ZebiAIは、予測された分子を活性テストのために研究者に提供し、研究者と協力して、発見を通じていくつかのプログラムを前進させます。
プログラムに参加するためには、コミュニティ全体が利益を得ることができるように、妥当性の確認されたヒットを妥当な時間内に公開する必要があります。
ヒット分子を化学的探査装置として使用するためには、更に検証を行う必要があります。
しかし、目的のタンパク質をターゲットにして、一般的な分析で正しく機能する能力を得た事は、ヒットを効果的に発見するプロセスの大きな前進です。
ここで説明した効果的なML技術を可能とするChemome Initiativeの一員であることに興奮しており、多くの新しい化学プローブの発見を楽しみにしています。Chemomeが重要な新しい生物学的発見を促進し、最終的には世界で新しい治療法の発見を加速することを期待しています。
謝辞
この研究は、多くの人々が関与するAccelerated Science TeamとX-Chem Pharmaceuticals間の複数年にわたる取り組みを表しています。このプロジェクトは、生物学者、化学者、およびML研究者の多様なスキルを組み合わせない限り機能しませんでした。特に、X-ChemのEric Sigel(現在はZebiAI)と、この論文の最初の著者であるKevin McCloskey(Google)と、コアモデリングのアイデアと技術的作業についてのSteve Kearnes(Google)に感謝します。
3.Chemome initiative:機械学習を使って有用なタンパク質を探る試み(2/2)関連リンク
1)ai.googleblog.com
Unlocking the “Chemome” with DNA-Encoded Chemistry and Machine Learning
2)pubs.acs.org
Machine Learning on DNA-Encoded Libraries: A New Paradigm for Hit Finding

