
1.PEGASUS:文章要約を行う最先端の人工知能(2/3)まとめ
・PEGASUSは1000程度の微調整用のサンプルで教師有りモデルを性能を発揮する事が出来た
・人間による品質評価を行ったところモデルの要約は人間の要約よりを一貫して好まれた
・初歩的ではあるが文章中の船の数を数えて要約する事が出来ており概念を関係づける能力を示した
2.PEGASUSによる要約の品質
以下、ai.googleblog.comより「PEGASUS: A State-of-the-Art Model for Abstractive Text Summarization」の意訳です。元記事の投稿は2020年6月9日、Peter J. LiuさんとYao Zhaoさんによる投稿です。
アイキャッチ画像はピエール・ピュヴィス・ド・シャヴァンヌの『幻想』。岡山県倉敷市の大原美術館所蔵です。
少数のサンプルのみを使った微調整
PEGASUSは大規模なデータセットで驚くべきパフォーマンスを示しましたが、このモデルが最新のパフォーマンスに近づくために微調整用のサンプルを多数必要としないことを知って驚きました。
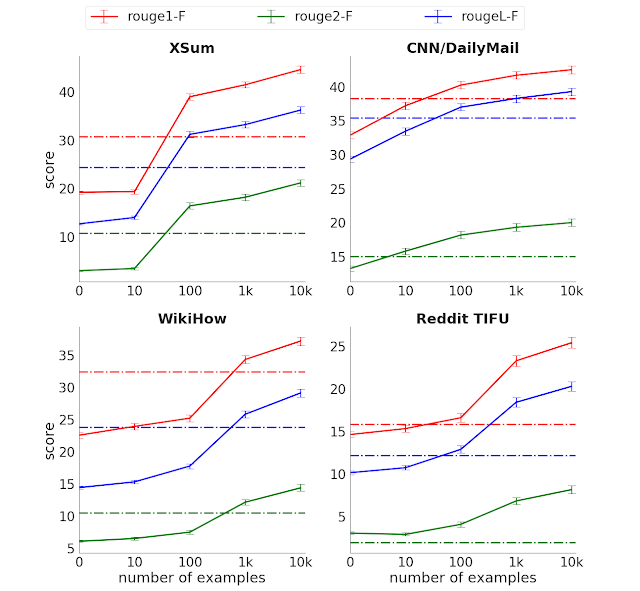
ROUGEスコア(3バージョン、スコアが高い方が良い)と、選択した4つの要約データセットで教師付き版との比較。点線は、事前訓練なしの完全教師型のTransformerエンコーダー/デコーダーモデルのパフォーマンスを示しています。
わずか1000事例を使った微調整で、比較対象である教師あり学習モデル(Transformer エンコーダー/デコーダー)よりも多くのタスクで優れたパフォーマンスを発揮できました。教師あり学習モデルは場合によっては教師用の完全なデータを数桁違う規模で大量に使用しています。
PEGASUSの「サンプル効率」の高さは、要約タスクにおいて非常に費用がかかる教師データ収集の規模とコストを大幅に削減するため、テキスト要約モデルの有用性を大幅に向上させます。
人間品質の要約
ROUGEなどの自動でパフォーマンスを評価できる指標はモデル開発中の進捗状況を逐次測定するために役立ちますが、これら自動評価指標は限られた情報しか提供せず、流暢さや人間のパフォーマンスとの比較などの全体像を伝えません。
全体像を把握する目的のために、人間による評価を行いました。評価者は、モデルの要約を人間の要約と比較するように求められました(どちらが機械による要約かわからない状態で評価します)。この評価は、チューリングテストといくつかの類似点があります。
訳注:チューリングテストは、機械と人間がどちらがどちらかわからない状態で評価者と対話し、評価者が機械と人間の区別が確実にできなかった場合に合格とするテストで、機械の知性を判定する際に用いられます。

人間の評価者は、どちらが機械でどちらが人間かを知らされず、モデルと人間が作成した要約を評価するように求められました。上図では文章が一部省略されていますが、評価者には全文を表示しています。
3つの異なるデータセットを使用して評価実験を実行したところ、人間の評価者は、私達のモデルの要約よりも人間の要約を一貫して好まないことがわかりました。
更に、1000事例のみを使ってトレーニングした私達のモデルもほぼ同様に機能しました。
特に、よく研究されているXSumとCNN/Dailymailデータセットにおいて、モデルは1000事例のみを使用して人間同等のパフォーマンスを実現しています。
これは、教師あり学習用の大規模なデータセットは要約タスクにもはや必要ではなく、多くの低コストな使い方が出来るようになるだろう事を示唆しています。
理解度テスト:船を数える
本投稿の末尾に、XSumデータセットに含まれる記事と、その記事からモデルが生成した要約文を付記します。モデルは、記事中で名称を上げられた四隻の駆逐艦(HMS Cumberland, HMS Campbeltown, HMS Chatham, HMS Cornwall)を「four Royal Navy frigates(4隻のイギリス海軍駆逐艦)」として正しく要約し、言い換えます。
4隻の4(four)は、記事中で一度も現れていない単語であるため、文章要約ではなく文章抽出を行った場合はこのような結果にはなりません。
これはまぐれなのでしょうか?またはモデルは実際に船の数を数えているのでしょうか?確認する1つの方法は、船を追加および削除して、数が変化するかどうかを確認することです。
末尾に示すように、モデルは2隻から5隻までの船であれば正常に「カウント」します。しかし、6番目の船「HMS Alphabet」を追加すると、「7」と誤って数えます。
そのため、モデルはリスト内の少数のアイテムを数える事を学習したようですが、期待どおりに流暢な一般化が行われたわけではありません。
それでも、この初歩的なカウント機能は、モデルが明示的にプログラムされているわけではなかったので印象的であり、モデルによる限定的な「象徴的な推論(symbolic reasoning)」、つまり概念を関係づける認知能力を示しています。
PEGASUSのコードとモデルのリリース
この分野で進行中の研究をサポートし、再現性を確保するために、GitHubでPEGASUSコードとモデルチェックポイントをリリースしています。これには、PEGASUSを他の集計データセットに適合させるために使用できる微調整用のコードが含まれます。
謝辞
この作品は、Jingqing Zhang, Yao Zhao, Mohammad Saleh 及び Peter J. Liuの共同研究です。PEGASUSの事前トレーニング用のデータセットを提供してくれたT5チームとGoogle News teamsに感謝します。
3.PEGASUS:文章要約を行う最先端の人工知能(2/3)関連リンク
1)ai.googleblog.com
PEGASUS: A State-of-the-Art Model for Abstractive Text Summarization
2)arxiv.org
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
3)github.com
google-research/pegasus
4)www.aclweb.org
ROUGE: A Package for Automatic Evaluation of Summaries
