
1.Data Echoing:バッチデータを再利用する事でアクセラレータを最大限に活用(2/2)まとめ
・画像分類、言語モデリング、物体検出でデータエコーがディスクI/Oを削減できる事が検証された
・場合によっては、データエコーによる再利用データが新鮮なデータと同等に有用なケースもあった
・データの再利用がモデルの最終的なパフォーマンスに悪影響を与える事もなかった
2.データの再利用とパフォーマンスの関係
以下、ai.googleblog.comより「Speeding Up Neural Network Training with Data Echoing」の意訳です。元記事の投稿は2020年5月12日、Dami ChoiさんとGeorge Dahlさんによる投稿です。
データの再利用と聞くと、過学習等、モデルの最終パフォーマンスへの悪影響を予想してしまいますが、良く考えると人間の脳も反復学習を必要とするケースがあるので、実はニューラルネットワークにとっても自然な事なのかもしれませんね。
アイキャッチ画像のクレジットはPhoto by Jessica F on Unsplash
様々なモデルと学習手法におけるデータエコー
それでは、データを再利用することはどれほど有用なのでしょうか?
3つの異なるタスク(画像分類、言語モデリング、物体検出)にまたがる5つのニューラルネットワークトレーニングパイプラインでデータエコーを試し、特定のパフォーマンスに到達するために必要な新しいデータ(再利用ではないデータ)の数を測定しました。
比較対象としたモデル(Baseline)がハイパーパラメータの調整で確実に達成できる最良のスコアを目標スコアにしました。その結果、データエコーにより、新しいデータを少なくして目標のパフォーマンスに到達できる事がわかりました。これは、データの再利用がさまざまなタスクでディスクI/Oを削減するのに役立つことを示しています。
場合によっては、再利用データが新鮮なデータとほぼ同じくらい役立つこともありました。下図は、拡張前エコーの例です。設定した反復係数(repetition factor)にほぼ比例して新しいデータの数を削減できています。
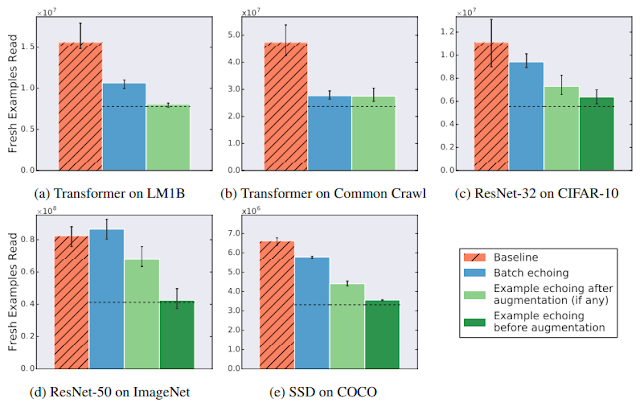
様々なデータとモデルでデータエコーを使わなかった場合(Baseline)と使った場合の比較
各データエコーではデータを2回利用しています。
目標パフォーマンスに到達するために必要な新しいデータの数は減少、または変わりません。
破線は、再利用されたデータが新しいデータと同じくらい有用であった場合に予想される値を示しています。
トレーニング時間の短縮
データエコーは、アクセラレータで実行できない上流の処理がトレーニング時間の大半を占める場合はいつでも、トレーニングをスピードアップできます。
トレーニングデータの入力をクラウドストレージからネットワーク経由で行い、そのネットワーク遅延がボトルネックとなっているトレーニングパイプラインを使ってトレーニングのスピードアップを測定しました。
これは、現在の大規模機械学習環境の多く、またはリモートストレージシステムからネットワークを介してトレーニングデータをストリーミングする人々にとって現実的な想定です。
ImageNetデータセットでResNet-50モデルをトレーニングする際にデータエコーを使用すると、トレーニング速度が大幅に向上し、この場合は3倍以上高速になることがわかりました。
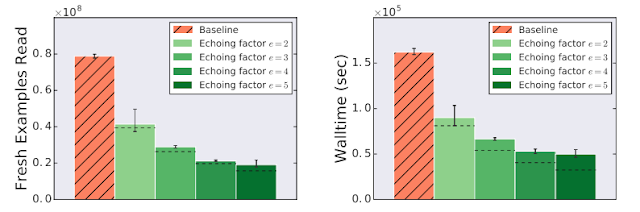
データエコーにより、ImageNetを使ったResNet-50のトレーニング時間を短縮できます。
この実験では、トレーニングデータのバッチをクラウドストレージから読み取るために必要な時間は、データの各バッチを使用してトレーニングを実行するコードの実行時間の6倍です。凡例のエコー係数(Echoing factor)は、各データアイテムが再利用された回数を示します。破線は、再利用されたデータが新しいデータと同じくらい有用で、エコーによるオーバーヘッドがない場合の期待値を示しています。
データエコーがモデルの予測パフォーマンスに与える影響
データの再利用がモデルの最終的なパフォーマンスに悪影響を与える事を懸念するかもしれませんが、今回テストしたケースのいずれについても、データのエコーによって最終モデルの品質が低下することはありませんでした。
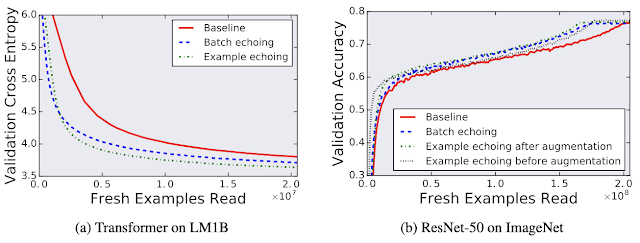
データエコーを使用した場合と使用しない場合の比較
検証用データを使って最高のパフォーマンスを達成した時点の性能を比較すると、データの再利用が最終的なモデルの品質に影響を与えていない事がわかります。ここで検証クロスエントロピー(validation cross entropy)は、log perplexityに相当します。
GPUやTPUなどの特殊なアクセラレータの改善スピードが汎用プロセッサを上回り続けているため、データエコーと同様な戦略がニューラルネットワークトレーニングにおいてますます重要になると予想しています。
謝辞
Data Echoingプロジェクトは、Dami ChoiがGoogle AIのレジデントであったときに、Dami Choi、Alexandre Passos、Christopher J. Shallue、およびGeorge E. Dahlによって実施されました。
有益な議論をしてくれたRoy Frostig、 Luke Metz、 Yiding Jiang、及びTing Chenにも感謝します。
3.Data Echoing:バッチデータを再利用する事でアクセラレータを最大限に活用(2/2)関連リンク
1)ai.googleblog.com
Speeding Up Neural Network Training with Data Echoing
2)arxiv.org
Faster Neural Network Training with Data Echoing

