
1.WaveNetEQでGoogle Duoの通話品質を向上(2/2)まとめ
・コンディショニングネットワークは抑揚を意識して自己回帰ネットワークをあるべき波形に修正できる
・WaveNetEQの学習時は実際のデータを次のステップの入力に使うteacher forcingを使っている
・48言語の100人以上の音声で学習した結果、WaveNetEQは人間の発声の一般的な特性を学習できた
2.WaveNetEQの性能評価
以下、ai.googleblog.comより「Improving Audio Quality in Duo with WaveNetEQ」の意訳です。元記事は2020年4月1日、Pablo BarreraさんとFlorian Stimbergさんによる投稿です。アイキャッチ画像のクレジットはPhoto by Dias on Unsplash
WaveRNNは、その前身のWaveNetと同様に、音声合成(TTS:text-to-speech)アプリケーションで使用する事を念頭に置いて開発されました。そのため、WaveRNNには「何を言うか」及び「どのように言うか」に関しての情報が提供されます。
コンディショニングネットワークは、単語と追加の韻律特徴(つまり、イントネーションや声の高さなどの全ての非文書情報)を音素の形式で入力として受け取ります。
ある意味で、コンディショニングネットワークは「未来を見通す」ことができ、そのため自己回帰ネットワークをあるべき波形に合わせる事が出来ます。
単純なPLC(Packet Loss Concealment:パケット損失隠蔽)システムを使ったリアルタイム通話では、これは実現できません。PLCシステムで自然な音声を提供するためには、現在の音声から韻律情報を抽出し、その調子を継続するためにもっともらしい音程を生成する必要があります。
私達のWaveNetEQは、「自動回帰ネットワークを使用してパケット損失が発生した際に音声を途切れさせない事」と同時に「コンディショニングネットワークを使用して音声特性などの長期的な特徴をモデル化する事」を同時に行います。
過去の音声信号のスペクトログラムがコンディショニングネットワークの入力として使用され、韻律と文に関する限定的な情報が抽出されます。この圧縮された情報は、自己回帰ネットワークに送られます。自己回帰ネットワークは、これを直近の音声情報と組み合わせて、次の音声波形を予測します。
これは、WaveNetEQモデルのトレーニング中に実際に使われた手順とは少し異なります。WaveNetEQモデルは、自己回帰ネットワークが生成したデータではなく、トレーニングデータに存在する実際のデータを次のステップの入力として受け取ります。このプロセスは「教師の強制(teacher forcing)」と呼ばれ、予測の品質がまだ低いトレーニングの初期段階でも、モデルが貴重な情報を確実に学習するようにします。
モデルが完全にトレーニングされ、音声または映像通話で使用できるようになレベルに達すると、教師の強制は最初のデータでモデルを「ウォーミングアップ」するためにのみ使用され、その後は独自の出力が次のステップの入力として使われます。
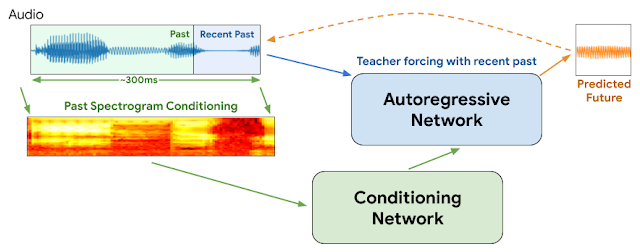
WaveNetEQのアーキテクチャ
推論中、教師は最新の実音声で強制的に自己回帰ネットワークを「ウォームアップ」します。その後、モデルは次のステップの入力として自己回帰ネットワーク自身が生成したデータを使用します。より長い音声パーツからのMELスペクトログラムは、コンディショニングネットワークの入力として使用されます。
モデルはDuoの音声データ用のバッファ内で動きます。パケット損失が発生した後に実際の音声データが到着すると、合成音声と実際の音声を途切れないように繋ぎます。
2つのデータ間で最適な繋ぎ位置を見つけるために、モデルはわずかに大目にデータを生成し、一方から他方へクロスフェードさせます。これにより、データ間の移行がスムーズになり、顕著なノイズが回避されます。
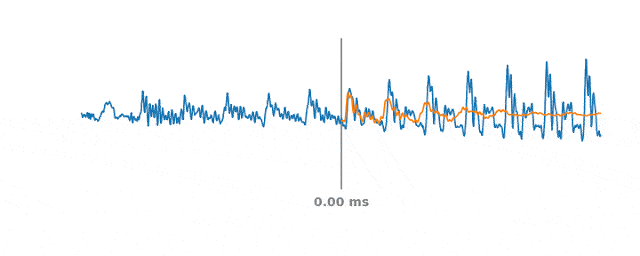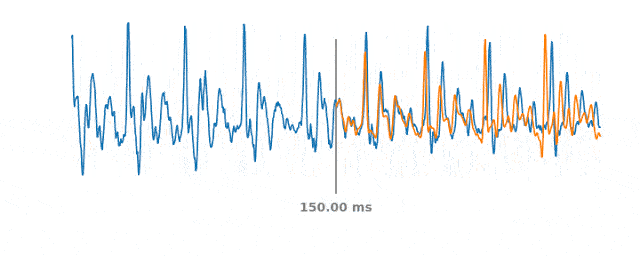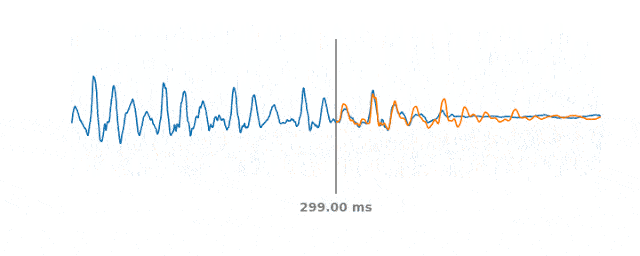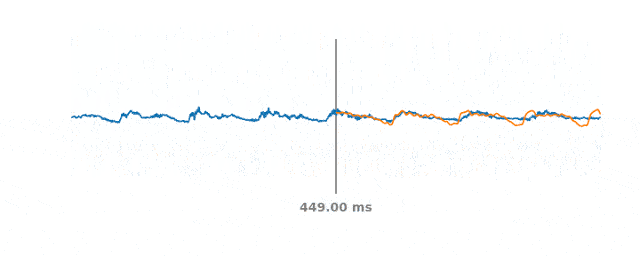
60ms間隔での音声のPLCイベントシミュレーション
青い線は、PLCイベント発生前後の実際の音声信号を表します。オレンジ色の線は合成音声を表し、WaveNetEQは中央の灰色の垂直線部分で音声をどのように切り取るかを予測します。
60msのPacket Loss発生時
| NetEQ No1 upfront |
| WaveNetEQ No1 upfront |
| NetEQ No2 wow |
| WaveNetEQ No2 wow |
120msのPacket Loss発生時
| NetEQ No1 next |
| WaveNetEQ No1 next |
| NetEQ No2 they |
| WaveNetEQ No2 they |
WebRTCのデフォルトのPLCシステムであるNetEQとGoogleの最新モデルであるWaveNetEQのオーディオクリップによる比較
オーディオクリップはLibriTTSのものを使用しており、全音声の10%が60または120ms長で削除されており、PLCシステムによって補完されました。
堅牢性の確保
PLCの1つの重要な機能は、様々な話者やバックグラウンドノイズなど、環境によって変化する入力信号にネットワークが適応できることです。幅広いユーザーに対してモデルが堅牢性を発揮できるようにするために、48の異なる言語で100人を超える話者による音声データセットでWaveNetEQをトレーニングしました。
これにより、モデルは特定の言語の特性ではなく、人間の発声の一般的な特性を学習できます。WaveNetEQが駅やカフェテリアでの電話応答などのノイズの多い環境に確実に対応できるように、様々なバックグラウンドノイズと混合して学習データを増強する事も行っています。
WaveNetEQはもっともらしい通話を続ける方法を学習しますが、これは短い間隔でのみ当てはまります。音節は補完しますが単語自体を予測する事はしません。パケット損失により失われた音声が長いと、モデルは120ミリ秒後に無音になるように徐々にフェードアウトします。
モデルが偽の音節を生成しないことをさらに確実にするために、Google Cloud Speech-to-Text APIを使用して、WaveNetEQおよびNetEQが補完した音声を評価しました。その結果、単語の誤り率、つまり、発話されたテキストを転記した際の誤りの数に有意な差はありませんでした。
私たちはGoogle DuoでWaveNetEQを実験しており、これは通話品質とユーザー体験にプラスの影響を示しています。WaveNetEQは、Pixel 4スマートフォンの全てのDuo通話で既に利用可能で、現在、他のモデルにも追加で展開されています。
謝辞
コアチームには、GoogleのAlessio Bazzica, Niklas Blum, Lennart Kolmodin, Henrik Lundin, Alex Narest, Olga Sharonova、DeepMindのTom Waltersが含まれます。また、Martin Bruse(Google)、Norman Casagrande、Ray Smith、Chenjie Gu、およびErich Elsen(DeepMind)の貢献にも感謝します。
3.WaveNetEQでGoogle Duoの通話品質を向上(2/2)関連リンク
1)ai.googleblog.com
Improving Audio Quality in Duo with WaveNetEQ
2)duo.google.com
Try Google Duo
3)webrtc.org
Real-time communication for the web

