
1.Neural Tangents:高速に手軽にニューラルネットワークの幅を無限に拡張(2/2)まとめ
・無限幅のアンサンブルは単純な閉形式であるが有限幅のアンサンブルと顕著に一致している
・無限幅のニューラルネットワークは有限幅のネットワークの学習過程の変遷を捕捉する能力を持つ
・Neural Tangentsを使用して構築されたネットワークは通常のネットワークと同様に問題に適用可
2.無限幅のアンサンブル
以下、ai.googleblog.comより「Fast and Easy Infinitely Wide Networks with Neural Tangents」の意訳です。元記事の投稿は2020年3月13日、Samuel S. SchoenholzさんとRoman Novakさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Aaron Burden on Unsplash
Neural Tangentsの有用性の例として、完全接続(fully-connected)ニューラルネットワークのトレーニングを想像してください。
通常、ニューラルネットワークはランダムに初期化され、勾配降下法を使用してトレーニングされます。これらのニューラルネットワークを何パターンか作成し、初期化およびトレーニングすると、アンサンブル、すなわち各ニューラルネットワークの出力を平均化したニューラルネットワークを得る事が出来ます。
多くの場合、研究者や実践者は、ニューラルネットワークのパフォーマンスを向上させるために、異なるモデルから得られたアンサンブルを求めて予測を平均化します。更に、アンサンブルに含めたモデルの予測の分散を使用して、モデルの不確実性も推定できます。
欠点は、ネットワークのアンサンブルのトレーニングにはかなりの計算が必要になる事で、そのため、しばしば計算を回避するために行われない事です。
ただし、ニューラルネットワークの幅が無限に広くなるとしたら、アンサンブルは、トレーニング全体で計算できる平均と分散を持つガウス過程によって記述できます。
Neural Tangentsを使用すると、わずか5行のコードを使用して、これらの無限幅のネットワークのアンサンブルを一度に構築およびトレーニングできます。結果として得られるトレーニングプロセスを以下に示します。この実験を行うインタラクティブなcolaboratoryによるnotebookも公開されています。

両方のグラフで、有限ニューラルネットワークのアンサンブルのトレーニングを同じアーキテクチャの無限幅のアンサンブルと比較しています。有限アンサンブルの平均と分散は、2本の黒い点線の間の黒い破線として表示されます。無限幅のアンサンブルの平均と分散は、塗りつぶされた領域内に色付きの実線で表示されます。両方のグラフで、有限幅と無限幅のアンサンブルは非常に密接に一致しており、区別が難しい場合があります。
左:トレーニングの進行中の入力データ(水平x軸)と出力データ(垂直f軸)
右:不確実性を伴うトレーニングおよびテストの損失
無限幅のアンサンブルは単純な閉形式(closed-form expression:有限数の演算で表現できる事)であるという事実にもかかわらず、有限幅のアンサンブルと顕著な一致を示しています。また、無限幅のアンサンブルはガウス過程であるため、自然に閉形式による不確実性の推定値を提供します。(上図の塗りつぶされた領域)
これらの不確実性の推定値は、有限ネットワーク(破線)の多くの異なるコピーをトレーニングするときに観察される予測の変動と密接に一致します。上記の例は、トレーニング過程の変遷を捕捉する無限幅ニューラルネットワークの能力を示しています。
ただし、Neural Tangentsを使用して構築されたネットワークは、通常のニューラルネットワークを適用できるあらゆる問題に適用できます。例えば、以下では、CIFAR-10データセットを使用した画像認識タスクで3つの異なる無限幅ニューラルネットワークアーキテクチャを比較しています。
驚くべきことに、勾配降下法と完全ベイズ推定法(有限幅を用いると難解なタスク)の両方で、閉形式の無限幅のワイド残差ネットワークのような高度に精巧なモデルの集合を評価できます。
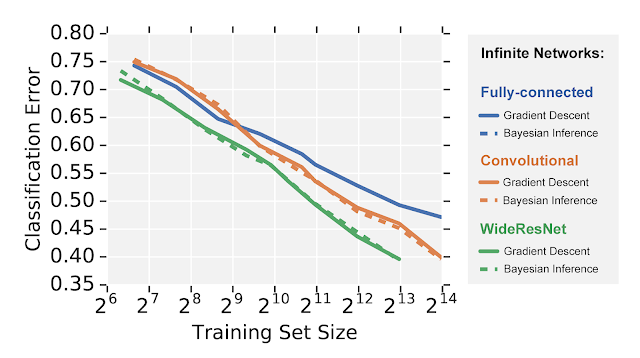
無限幅のネットワークは有限幅のニューラルネットワークと同様なモデルパフォーマンスの優劣に従っている事がわかります。つまり、完全結合ネットワーク(fully-connected network)は畳み込みネットワーク(convolutional networks)よりも性能が劣り、畳み込みネットワークはワイド残差ネットワーク(wide residual networks)よりも性能が劣っています。ただし、通常のトレーニングとは異なり、これらのモデルの学習時の挙動は閉形式なためとても扱いやすく、これにより、今までにないレベルでモデルの挙動を観察する事が可能になります。
私達は皆さんをモデルの無限幅バージョンの探索にご招待します。Neural Tangentsを使用して、ディープラーニングのブラックボックスを開くのを手伝ってください。開始するには、論文、チュートリアル用のColabノートブック、およびGithubリポジトリをご覧ください。貢献、機能のリクエスト、バグレポートは大歓迎です。 この作品は、ICLR 2020でスポットライトとして受け入れられました。
謝辞
Neural Tangentsは、Lechao Xiao, Roman Novak, Jiri Hron, Jaehoon Lee, Alex Alemi, Jascha Sohl-Dickstein そして Samuel S. Schoenholzによって積極的に開発されています。ライブラリの改善に継続的に貢献してくれたYasaman BahriとGreg Yang、そして頻繁な議論と有益なフィードバックをしてくれたSergey Ioffe、Ben Adlam、Ravid Ziv、Jeffrey Penningtonにも感謝します。 最後に、最初の図のアニメーションを作成してくれたTom Smallに感謝します。
3.Neural Tangents:高速に手軽にニューラルネットワークの幅を無限に拡張(2/2)まとめ
1)ai.googleblog.com
Fast and Easy Infinitely Wide Networks with Neural Tangents
2)arxiv.org
Neural Tangents: Fast and Easy Infinite Neural Networks in Python
3)colab.research.google.com
Neural Tangents Cookbook.ipynb
4)github.com
google/neural-tangents

