
1.ELECTRA:NLPの事前トレーニングを効率的に改良(2/2)まとめ
・ELECTRAを他のNLPモデルと比較すると同じ計算量であれば従来の方法よりも大幅にスコアが改善した
・単一GPUで4日間で学習可能でELECTRA-smallはGPTよりも優れたパフォーマンスで計算量は30分の1
・ELECTRA-LargeはGLUEリーダーボードでRoBERTa、XLNet、およびALBERTを凌駕した
2.ELECTRAとは?
以下、ai.googleblog.comより「More Efficient NLP Model Pre-training with ELECTRA」の意訳です。元記事の投稿は2020年3月10日、Kevin ClarkさんとThang Luongさんによる投稿です。アイキャッチ画像のクレジットはWikipediaよりエレクトラとオレステース
置換トークンは、ジェネレーターと呼ばれる別のニューラルネットワークから取得されます。
ジェネレーターは、トークンの出力分布を生成する任意のモデルにすることができますが、ディスクリミネータと一緒にトレーニングされる小さなマスク言語モデル(つまり、隠れ層のサイズが小さいBERTモデル)を使用します。
ディスクリミネータに入力するジェネレーターの構造はGANに似ていますが、GANをテキストに適用するのが難しいため、マスクされた単語を敵対的な例にするのではなく可能性が最も高い予測例に置き換えるようにジェネレーターをトレーニングします。
ジェネレータとディスクリミネータは、同じ入力語のembbedingを共有します。事前トレーニングの後、ジェネレーターは削除され、識別器(ELECTRAモデル)が下流タスクで微調整されます。全てのモデルは、transformer ニューラルアーキテクチャを使用しています。
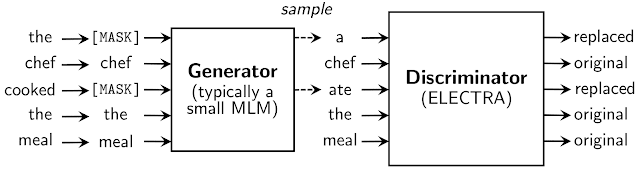
置換トークン検出(RTD)タスクの詳細
偽のトークンは、ELECTRAと共同でトレーニングされた小さなマスク言語モデルからサンプリングされます。
ELECTRAが出した結果
ELECTRAを他の最先端のNLPモデルと比較すると、同じ計算量であれば、従来の方法よりも大幅に改善され、RoBERTaおよびXLNetと同等のパフォーマンスを発揮するためには25%未満の計算量で済む事がわかりました。
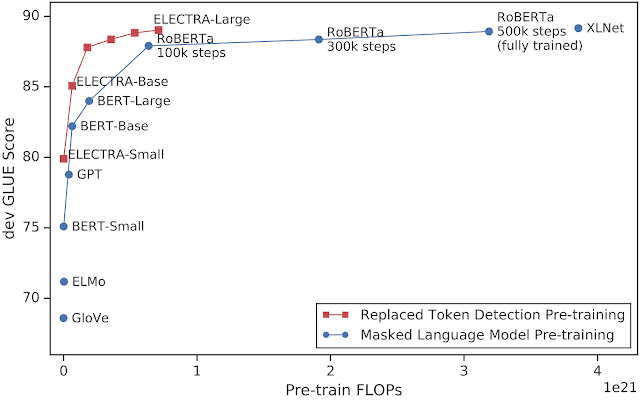
x軸はモデルのトレーニングに使用される計算量(FLOPで測定)を示し、y軸はdev GLUEスコアを示します。ELECTRAは、既存の事前トレーニング済みNLPモデルよりもはるかに効率的に学習します。T5(11B)などのGLUEの現在の最良のスコアを出したモデルは、他のモデルよりもはるかに多くの計算を使用するため(RoBERTaの約10倍)、このグラフ内に収まりきらないことに注意してください。
更にさらに効率化を進め、単一のGPUを使って4日間で学習可能で高精度な小さなELECTRAモデルを試しました。トレーニングに多くのTPUを必要とする大きなモデルと同じ精度を達成することはできませんが、ELECTRA-smallは、GPTよりも優れたパフォーマンスを発揮し、計算量は30分の1で済みます。
最後に、この強力な結果が規模を拡大しても保持されるかどうかを確認するために、より多くの計算(RoBERTaとほぼ同じ量、T5の約10%の計算量を使用して大規模なELECTRAモデルをトレーニングしました。
このモデルは、SQuAD 2.0質問回答データセット(以下の表を参照)で単一モデルの最新のスコアを実現し、GLUEリーダーボードでRoBERTa、XLNet、およびALBERTを凌駕します。大規模なT5-11bモデルのスコアはGLUEではELECTRAより高くなっていますが、ELECTRAは30分の1のサイズであり、計算量も10%程度の状態でトレーニングしています。
| Model | Squad 2.0 test set |
| ELECTRA-Large | 88.7 |
| ALBERT-xxlarge | 88.1 |
| XLNet-Large | 87.9 |
| RoBERTa-Large | 86.8 |
| BERT-Large | 80.0 |
ELECTRA-Largeおよびその他の最新モデルのSQuAD 2.0スコア(アンサンブルモデルは除外しています)
ELECTRAのリリース
ELECTRAの事前トレーニング済みモデル用と下流タスク用に微調整したモデル用の両方のコードをリリースしています。下流タスクには、テキスト分類、質問回答、シーケンシャルなタグ付けなどが含まれます。このコードは、1つのGPUで小さなELECTRAモデルをすばやくトレーニングする事をサポートします。ELECTRA-Large、ELECTRA-Base、およびELECTRA-Smallの事前トレーニング済みの重みもリリースしています。ELECTRAモデルは現在英語のみですが、将来多くの言語で事前にトレーニングされたモデルをリリースすることを希望しています。
3.ELECTRA:NLPの事前トレーニングを効率的に改良(2/2)関連リンク
1)ai.googleblog.com
More Efficient NLP Model Pre-training with ELECTRA
2)openreview.net
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
3)github.com
google-research / electra

