
1.LaserTagger:制御可能で効率的な文章生成アプローチ(2/2)まとめ
・従来のseq2seqを使ったモデルと比較してLaserTaggerには3つの利点がある
・制御可能で幻覚の影響を受けにくい事、最大100倍の速度で予測を実行可能である事
・数千程度の学習データを使用してトレーニングした場合でも適切な出力を生成可能
2.LaserTaggerとBERTベースモデルの比較
以下、ai.googleblog.comより「Encode, Tag and Realize: A Controllable and Efficient Approach for Text Generation」の意訳です。元記事の投稿は2020年1月31日、Eric MalmiさんとSebastian Krauseさんによる投稿です。アイキャッチ画像のクレジットはPhoto by David Švihovec on Unsplash
結果
LaserTaggerを4つのタスクで評価しました。文の結合、分割と言い換え、抽象的要約、および文法の修正です。タスク全体で、LaserTaggerは、多数のトレーニングサンプルを使用するBERTベースの強力なseq2seqベースラインと同等のパフォーマンスを発揮し、トレーニングサンプルの数が限られている場合、このベースラインより明らかに優れています。以下に、WikiSplitデータセットの結果を示します。タスクは、長い文を2つのまとまった短い文に言い換える事です。
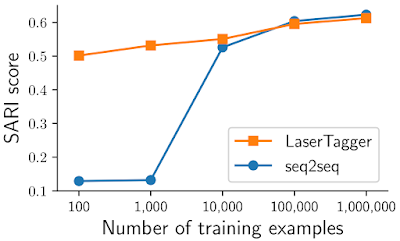
サンプル数100万以上の完全なデータセットでモデルをトレーニングすると、LaserTaggerと比較対象としたBERTベースのseq2seqモデルは同等に機能します。しかし、10,000サンプル以下のサブサンプルでトレーニングすると、LaserTaggerはseq2seqモデルより明らかに優れています。(SARIスコアが高い事は優れている事を意味します)
LaserTaggerの主な利点
従来のseq2seqを使ったモデルと比較して、LaserTaggerには次の利点があります。
1)制御が可能である事
出力フレーズの語彙を制御することにより、LaserTaggerは比較対象としたseq2seqモデルよりも幻覚の影響を受けにくくなります。
2)推論速度
LaserTaggerは、比較対象としたseq2seqモデルの最大100倍の速度で予測を実行するため、リアルタイムアプリケーションに適しています。
3)データ効率性
LaserTaggerは、数百または数千の学習データを使用してトレーニングされた場合でも、適切な出力を生成します。私達の実験では、比較対象としたseq2seqモデルは、同等のパフォーマンスを得るために何万もの例が必要でした。
LaserTaggerが重要な理由
LaserTaggerの利点は、大規模な環境に適用するとさらに顕著になります。
例えば、応答速度を早くする事で一部の音声応答サービスを改善します。推論速度が速いため、モデルを既存製品に追加で搭載してもユーザー側がストレスを感じるような応答遅延は発生しません。データ効率の向上により、多くの言語でトレーニングできるため、さまざまな母国語を持つユーザーにメリットがあります。
現在の研究では、自然言語を生成する他のGoogleテクノロジーに同様の改善をもたらすよう努めています。更に、文章を(ゼロから作成する代わりに)編集する事で、ユーザによる問い合わせ文が長く、より複雑になり、対話中に使われた際にもよりよく理解できるようにする方法を検討しています。LaserTaggerのコードは、GitHubリポジトリを通じてコミュニティにオープンソースで公開されています。
謝辞
この調査は、Eric Malmi, Sebastian Krause, Sascha Rothe, Daniil Mirylenka, 及び Aliaksei Severynによって実施されました。 Enrique Alfonseca、Idan Szpektor、Orgad Kellerとの有益な議論に感謝します。
3.LaserTagger:制御可能で効率的な文章生成アプローチ(2/2)関連リンク
1)ai.googleblog.com
Encode, Tag and Realize: A Controllable and Efficient Approach for Text Generation
2)research.google
Encode, Tag, Realize: High-Precision Text Editing
3)github.com
google-research / lasertagger

