
1.その転移学習は本当に有用なのか?(3/3)まとめ
・事前学習によって学習された重みは特徴表現とは無関係に学習を高速化する効果がある
・高速効果は平均と分散を意識した初期化で実現できるため任意のレイヤーに適用可能
・重みを再利用できる下位レイヤーのみ転移させ、上位レイヤーは再設計するハイブリッドアプローチが可能
2.転移学習のハイブリッドアプローチ
以下、ai.googleblog.comより「Understanding Transfer Learning for Medical Imaging」の意訳です。元記事は2019年12月6日、Maithra RaghuさんとChiyuan Zhangさんによる投稿です。
収束への影響:特徴表現と関係しない利点とハイブリッドアプローチ
転移学習の一貫した効果の1つは、モデルの収束に必要な時間を大幅に削減する高速効果です。
しかし、特徴表現を調査した結果、重みの再利用には様々なパターンがある事がわかったので、事前学習した重みに、高速化に寄与する他の要因があるかどうかを調べました。
驚くべき事に、特徴表現に依存しない事前トレーニングの利点が見つかりました。重みの計量(weight scaling)です。
ニューラルネットワークの重みを、ランダムな初期化と同様に、独立同分布(iid: independent and identically distributed)として初期化しましたが、その際に事前学習済みの重みの平均と分散を使用しました。
この初期化を平均分散初期化(Mean Var Init)と呼ぶ事にします。これは、事前にトレーニングされた重みの計量を維持しますが、全ての特徴表現は破壊されています。この平均分散初期化は、モデルアーキテクチャおよびタスク全体をランダムに初期化するよりも大幅に高速に収束する事が出来るので、転移学習の事前トレーニングプロセスが適切な重みの設定にも役立っている事を示唆しています。

事前トレーニングされたImageNetの重み、ランダム初期化による重み、及び平均分散初期化を行った重みの視覚化。ランダム初期化および平均分散初期化の重みはiidであるため、ImageNetの重みのみが事前学習済み構造を持っており、ガボールフィルタのような見た目をしています。
先ほど説明した実験では、特徴の再利用は主に最下層で発生していることが示唆されていたのを思い出してください。これを理解するために、事前にトレーニングされた重みのサブセット(連続する一連のレイヤーに対応)のみを転移し、残りの重みはランダムに初期化する重み注入実験を実行しました。これらの重みを注入されたネットワークの収束速度を完全な転送学習と比較すると、特徴表現の再利用は主に最下層で発生しているという結論がさらに裏付けられます。
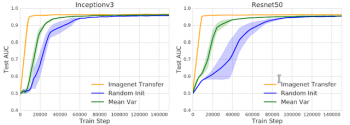
収束速度をテストセットのAUCで比較した学習曲線。事前学習済みの重みと平均分散初期化した重みのみを使用すると、収束速度が向上します。図は、標準の転移学習と平均分散初期化スキームをランダム初期化からのトレーニングと比較しています。
これは、転移学習のためのハイブリッドアプローチを示唆しています。完全なニューラルネットワークアーキテクチャを再利用する代わりに、最下位レイヤーのみを再利用し、上位レイヤーは再設計してターゲットタスクにより最適化するアプローチです。
これにより、柔軟なモデル設計を可能にしつつ、転移学習の利点のほとんどが得られます。下図では、Resnet50のBlock2までの事前トレーニング済みの重みを再利用し、残りを半分にし、それらのレイヤーをランダムに初期化してから、エンドツーエンドでトレーニングした効果を示しています。
このハイブリッドアプローチは、完全な転移学習に匹敵するパフォーマンスと収束速度を達成します。
![]()
Resnet50(左)およびCBRモデル(右)で転移学習するハイブリッドアプローチ
重みのサブセットを再利用し、ネットワークの残りをスリム化したモデル(Slim)、conv1に数学的に合成したGaborを使用したモデル(Synthetic Gabor)
上の図は、この部分的再利用の極端なバージョンの結果も示しており、数学的に合成されたガボールフィルターを使用して最初の畳み込み層のみを転送しています(下図)。 これらの(合成)した重みのみを使用すると、大幅な高速化が実現します。これは、他の多くの創造的なハイブリッドアプローチのヒントになります。

本論文のいくつかの実験でニューラルネットワークの第1層の初期化に使用された合成ガボールフィルター。ガボールフィルターはグレースケール画像として生成され、RGBチャンネル全体で繰り返されます。
左:低周波、右:高周波
結論と未解決な問題
転移学習は多くの研究領域にとって中心的な技術です。今回の論文では、転移学習を医療用画像処理に適用する際に表面化する基礎的な特性のいくつかについての洞察を提供し、学習効率、特徴表現の再利用、異なるアーキテクチャによる違い、収束速度、ハイブリッドアプローチの研究を行いました。
多くの興味深い未解決の問題が残っています。
モデルは転移元のタスクをどのくらい忘れてしまうのでしょうか?
大きなモデルの重みの変化が少ないのはなぜですか?
事前学習済みの重み統計と高次モーメントをマッチングさせる事によって更なる出力を得る事ができますか?
画像内の物体の識別など、他のタスクでも似たような結果になるのでしょうか?
今後の研究でこれらの質問に取り組むことを楽しみにしています!
謝辞
本研究の共著者であるSamy BengioとJon Kleinbergに感謝します。有益なフィードバックをいただいたGeoffrey Hintonにも感謝します。
3.その転移学習は本当に有用なのか?(3/3)関連リンク
1)ai.googleblog.com
Understanding Transfer Learning for Medical Imaging
2)arxiv.org
Transfusion: Understanding Transfer Learning for Medical Imaging
3)github.com
google/svcca
