
1.MobileNetV3:次世代のオンデバイス視覚モデル(2/3)まとめ
・MobileNetV3の探索スペースはh-swishとsqueeze-and-excitationで改良が施されている
・ネットワークの最後に新しい効率的な〆(last stage)を導入し、応答速度を更に15%削減
・Lite Reduced Atrous Spatial Pyramid Pooling(LR-SPP)と呼ばれるセグメンテーションデコーダーも搭載
2.MobileNetV3に使われた最適化手法
以下、ai.googleblog.comより「Introducing the Next Generation of On-Device Vision Models: MobileNetV3 and MobileNetEdgeTPU」の意訳です。元記事は2019年11月13日、Andrew HowardさんとSuyog Guptaさんによる投稿です。
MobileNetV3の探索スペース
MobileNetV3の探索スペースは、モバイル環境に適したアーキテクチャを設計する最近の複数の進歩に基づいて構築されています。
まず、Swish非線形関数に基づいたhard-swish(h-swish)と呼ばれる新しい活性化関数を導入しています。Swish関数の重大な欠点は、モバイルハードウェア上で計算させると非常に効率が悪いと言う事です。そのため、代わりに2つの区分線形関数の積として効率的に表現できる近似式を使用します。
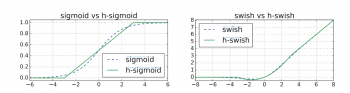
次に、同じく従来のシグモイド関数を区分的線形近似で置き換えるモバイル対応のsqueeze-and-excitationブロックを紹介します。
h-swishとモバイルフレンドリーなsqueeze-and-excitationを、MobileNetV2で導入された逆ボトルネック構造の修正バージョンと組み合わせることで、MobileNetV3の新しい土台が生まれました。
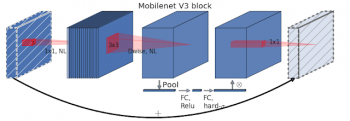
MobileNetV3は、h-swishおよびモバイルフレンドリーなsqueeze-and-excitationを検索可能なオプションとして追加することにより、MobileNetV2の逆ボトルネック構造を拡張します。
以下のパラメーターを、MobileNetV3の構築に使用される探索スペースに定義しています。
・拡張レイヤーのサイズ
・squeeze-excite圧縮の度合い
・活性化関数の選択:h-swishまたはReLU
・各解像度ブロックのレイヤー数
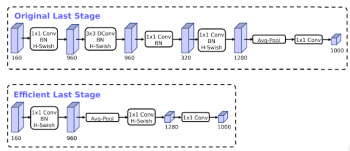
また、ネットワークの最後に新しい効率的な〆(last stage)を導入し、応答速度を更に15%削減しました。
MobileNetV3の物体検出とセマンティックセグメンテーション
分類モデルに加えて、MobileNetV3には物体検出モデルも導入しました。これにより、COCOデータセットを使ったテストでMobileNetV2と同精度を25%早い応答速度で達成しました。
効率的なセマンティックセグメンテーションを実現するためにMobileNetV3には、Lite Reduced Atrous Spatial Pyramid Pooling(LR-SPP)と呼ばれる低レイテンシセグメンテーションデコーダーを導入しまして最適化しています。
この新しいデコーダには、3つに分化しています。低解像度でのセマンティック検出用、高解像度での詳細用、および軽量のAttention用です。LR-SPPとMobileNetV3の組み合わせにより、高解像度のCityscapesデータセットで応答速度が35%以上短縮されました。
3.MobileNetV3:次世代のオンデバイス視覚モデル(2/3)まとめ
1)ai.googleblog.com
Introducing the Next Generation of On-Device Vision Models: MobileNetV3 and MobileNetEdgeTPU
2)arxiv.org
NetAdapt: Platform-Aware Neural Network Adaptation for Mobile Applications
