
1.皆のためのMLモデルの構築:機械学習の公平性を理解する(2/3)まとめ
・what-ifツールを使うと個々の特徴が個々のデータポイントにどのような影響を与えているのかを確認可能
・データの偏りを無視するために特定の特徴を考慮しないように調整した上で最高の精度を目指す事も出来る
・他にも「Equal opportunity」や「Equal accuracy」など様々な最適化戦略をデータに合わせて適用可能
2.What-ifツールの使い方
以下、cloud.google.comより「Building ML models for everyone: understanding fairness in machine learning」の意訳です。元記事の投稿は2019年9月26日、Sara Robinsonさんによる投稿です。
AIプラットフォームをWhat-ifツールに接続
XGBoostを使用してモデルを構築します。GitHubとAI Hubで完全なコードを見つけることができます。XGBoostモデルのトレーニングとAIプラットフォームへの展開は簡単です。
model = xgb.XGBClassifier(objective='binary:logistic')
model.fit(data, labels)
model.save_model('model.bst')
!gsutil cp model.bst gs://your_gcs_bucket
!gcloud ai-platform versions create v1 \
--model=model \
--framework='XGBOOST' \
--runtime-version=1.14 \
--origin=gs://your_gcs_bucket \
--python-version=3.5
モデルのAIプラットフォームへの展開が出来たので、それをWhat-ifツールに接続できます。
# This prediction adjustment function is needed since the What-If Tool expects
# a model's prediction output as a list of scores for each class.
def adjust_prediction(pred):
return [1 - pred, pred]
config_builder = (WitConfigBuilder(test_examples.tolist(), data.columns.tolist() + ['SalePrice'])
.set_ai_platform_model('your-gcp-project', 'housing', 'v1', adjust_prediction=adjust_prediction)
.set_target_feature('SalePrice')
.set_label_vocab(['Under160', 'Over160']))
WitWidget(config_builder)
上記のコードを実行すると、下図のような視覚化が行われます。
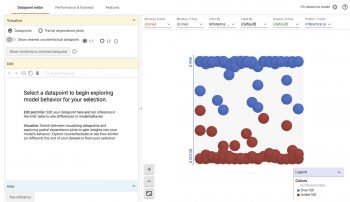
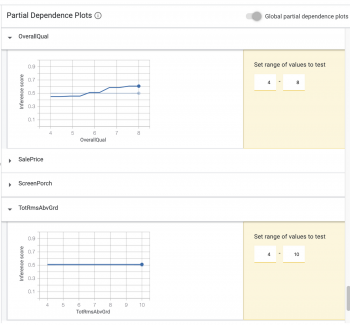
左上の部分的依存プロット(Partial dependence plots)を選択すると、個々の特徴が個々のデータポイント(データポイントを選択している場合)に関するモデルの予測、または全てのデータポイントに関するモデルの予測にどのような影響を与えているのかを確認できます。
全体的依存プロット(global dependence plots)では、住宅の全体的な品質評価がモデルの予測に大きな影響を与えたことがわかります。(つまり品質評価が上がると価格は上がります)しかし、寝室の数はそうではありませんでした。
この投稿の残りの部分では、公平性の指標に焦点を当てます。
[Fairness]タブの使用を開始
視覚化した図の左上で、[Performance & Fairness]タブを選択します。以下が最初に表示されるものです。
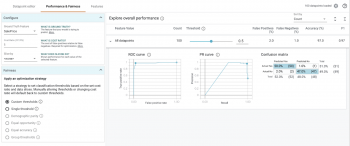
沢山ありますね! 設定オプションを追加する前に、詳細を見てみましょう。
「Explore overall performance」セクションでは、モデルの精度に関連するさまざまな指標を確認できます。デフォルトでは、しきい値を操作するためのスライダーは0.5に位置しています。
つまり、このモデルでは0.5を超える予測値は$160kを超えるものとして分類され、0.5を下回るものは$160kを下回るものとして分類されます。しきい値は、モデルのトレーニング後に決定する必要がある値です。What-ifツールは、最適化の対象に基づいて最適なしきい値を決定するのに役立ちます。(詳細については後述)しきい値スライダーを移動すると、すべての基準が変化することがわかります。
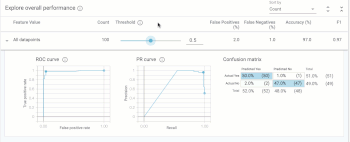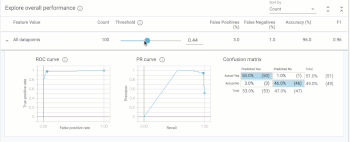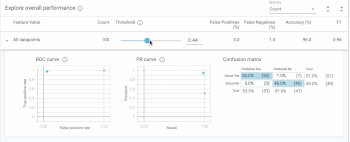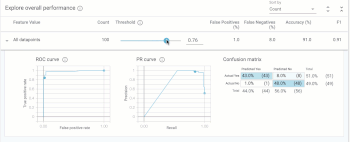
混同マトリックス(confusion matrix)は、各クラスの正しい予測の割合を示します。(4つの正方形を合計すると100%になります)。ROCおよびPrecision/Recall(PR)も、モデルの精度の一般的な指標です。データを様々な切り口でスライスして試行錯誤すると、このタブから最高の洞察が得られます。
データスライスに最適化戦略を適用
What-ifツールの左上にある[Configure]セクションで、[Slice by]ドロップダウンから特徴を選択します。最初に、ガレージが家に付帯しているかどうかを示す「GarageType_Attchd」を見てみましょう。(いいえの場合は0、はいの場合は1です)
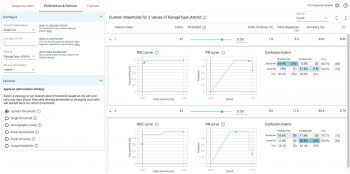
ガレージが付帯している家は、16万ドル以上とモデルに評価される可能性が高いことに注意してください。今回のケースではガレージに関するデータは収集できていますが、ガレージの有無に関わらず住宅の価格を同じようにモデルに扱って欲しいと言う状況を想像してみましょう。
この例では、クラス全体で同じ割合でポジティブな分類を持つことを最も重視する一方で、その制約内で可能な限り最高の精度を達成を目指します。
(訳注:つまり、ガレージ有りクラスとガレージ無しクラスの両方に同じ割合で16万ドル以上の住宅が存在するように調整しながら、可能な限り精度を上げる)
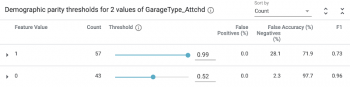
そのためには、左下のFairnessセクションから[Demographic parity]を選択する必要があります。
この戦略を設定すると、しきい値スライダーと精度基準が変化することがわかります。
これらの変更はどういう意味でしょうか?
ガレージの有無がモデルの価格に影響しないようにするには、ガレージが取り付けられているかどうかに応じて、住宅に異なるしきい値を使用する必要があります。
この更新されたしきい値を使用すると、予測スコアが.99以上の場合、モデルは家が$160k以上の価値があると予測します。あるいは、ガレージが付帯していない家の場合、モデルが0.52以上を予測した時に$160k以上として分類する必要があります。
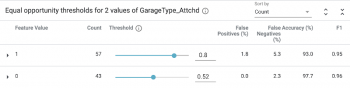
代わりに「Equal opportunity」戦略を使用する場合、ポジティブクラス内の高精度予測のために最適化され、データスライス全体で等しい真のポジティブレートが保証されます。
言い換えれば、これにより、$160kを超える価値のある住宅が、モデルによって$160kを超えていると分類される可能性が高まる事を保証するしきい値が選択されます。この結果は前述の結果と全く異なります。
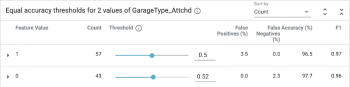
後に、「Equal accuracy」戦略は、両方のクラス(ポジティブとネガティブ)にわたって精度を最適化します。 繰り返しますが、結果のしきい値は上記の結果のいずれとも異なります。
近隣情報や住宅のタイプなど、他の特徴についても同様のスライス分析を行うことができます。または、2つの特徴を同時にスライスして交差分析を行うこともできます。
What-ifツールで使用される公平性の制約には多くの定義があることに注意することも重要です。使用すべきものは、モデルの状況に大きく依存します。
覚えておいて欲しい事
今回のデモでは住宅データセットを使用しましたが、これはあらゆる種類の分類タスクに適用できます。
この種の分析を行うことから何を学ぶことができますか?
一歩戻って、公平性分析を行わずに、すべての特徴値に対して0.5の分類しきい値を使用してモデルを展開した場合にどうなるかを考えてみましょう。
トレーニングデータに偏り(バイアス)が存在するため、モデルは位置、築年、サイズ、その他の特徴に基づいて異なった扱い住宅にします。もしかしたら、特定の特徴に連動してモデルを動作させたい(例えば、サイズが大きな住宅の価格を高くしたい)、もしくは偏りに合わせて調整したいと言う要望が出てくるでしょう。
モデルがどのように意思決定を行っているかに関する知識があれば、バランスが取れるようにトレーニングデータを追加したり、トレーニングの損失関数を調整したり、予測しきい値を調整して、目標とする公平性を考慮したりすることで、このバイアスに対処できます。
以下にチェックする価値のある機械学習における公平性のリソースをいくつか示します。
・Googleの機械学習クラッシュコースのML Fairnessセクション
・機械学習の公平性に関するGoogle I/Oでの講演
・責任あるAIプラクティス
・包含的MLガイド
・人間中心のAIガイドブック
・GitHubとAI Hubのこの投稿に示されている住宅デモのコード
MLの公平性または説明可能性のトピックでカバーしたいものが他にありますか? Twitterで@SRobTweetsに感想をお聞かせください。
3.皆のためのMLモデルの構築:機械学習の公平性を理解する(2/3)関連リンク
1)cloud.google.com
Building ML models for everyone: understanding fairness in machine learning
2)www.kaggle.com
House Prices: Advanced Regression Techniques
3)developers.google.com
ホーム > プロダクト > Machine Learning Crash Course > Fairness
4)ai.google
Responsible AI Practices
5)cloud.google.com
インクルーシブ ML ガイド – AutoML
6)pair.withgoogle.com
Designing human-centered AI products

コメント