
1.VideoBERT:ビデオ内の画像と音声を組み合わせて学習(3/3)まとめ
・VideoBERTはベースラインとした完全教師付き学習のtop-5 accuracyに匹敵する精度を達成
・VideoBERTはヴィジュアルトークン作成時に細かい視覚情報を失う可能性があるためCBTに改良
・平均プーリングやLSTMなどの従来手法と比較して、CBTモデルは長時間の予測に秀でている
2.CBTとは?
以下、ai.googleblog.comより「Learning Cross-Modal Temporal Representations from Unlabeled Videos」の意訳です。元記事は2019年9月11日、Chen SunさんとCordelia Schmidさんによる投稿です。
VideoBERTがビデオとテキスト間の意味的な対応関係を学習できているかどうかを確認するために、事前トレーニングデータとしてビデオもテキストも使用していないクッキングビデオデータセットで「ゼロショット」(テストデータ用に微調整を一度もしない事)で分類精度をテストしました。
分類を実行するために、ビデオトークンを「now let me show you how to [MASK] the [MASK]」というテンプレート文と連結させ、VideoBERTが予測した動詞と名詞のトークンを抽出しました。VideoBERTモデルは、ベースラインとした完全教師付き学習のtop-5 accuracyに匹敵する精度を達成しており、この「ゼロショット」設定でもモデルが競争力を発揮できることを示しています。
CBT(Contrastive Bidirectional Transformers)による転移学習
VideoBERTは、ビデオコンテンツを自動的にラベル付けおよび予測する方法を学習することで印象的な結果を示しましたが、私達はVideoBERTで使用されるヴィジュアルトークンは、小さなオブジェクトや微妙な動きなどのきめ細かい視覚情報を失う可能性があることに気付きました。
これを探求するために、このトークン化ステップを削除するContrastive Bidirectional Transformers(CBT)モデルを提案し、実務的タスクに転送学習させ、学習した特徴表現の品質を更に評価しました。
CBTは、クロスモーダル文とマスクされた位置の相互情報を最大化するために、異なる損失関数である対照的損失(contrastive loss)を使用します。
様々なタスクセット(アクション分割、アクション予測、ビデオ字幕付けなど)及び様々なビデオデータセットを使って、学習した特徴表現を評価しました。
CBTアプローチは、ほとんどのベンチマークで従来の最先端技術よりも大幅に優れています。
私達は以下を観察しました。
(1)クロスモーダルな目標は、転移学習のパフォーマンスにとって重要です。
(2)より大きく多様な事前トレーニングセットは、より良い特徴表現の学習につながります。
(3)平均プーリングやLSTMなどの従来手法と比較して、CBTモデルは長時間の予測においてはるかに優れています。
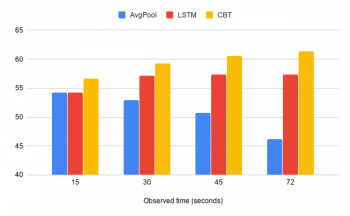
200のアクティビティのトリミングされていないビデオを用いたCBTアプローチによるアクション予測の精度。観測時間が15、30、45、72秒の場合のパフォーマンスをAvgPoolおよびLSTMと比較しています。
結論と今後の研究
私達の研究結果は、ラベル付けされていないビデオから視覚的言語および視覚的特徴表現を学習するBERTモデルの実力を示しています。
このモデルは、学習時に未見の動画のアクションを分類する事やレシピ生成に役立つだけでなく、学習した時間的特徴表現もアクション予測などのさまざまな実務的タスクに上手く転移学習できる事がわかりました。
将来の研究には、細かいレベルの視覚的特徴を長時間の時間的特徴表現と組み合わせて学習させる事が含まれます。これにより、ビデオへのより良い適応が可能になります。更に、事前トレーニングに使うビデオの数を増やし、より多様化する予定です。
謝辞
コアチームには、Chen Sun, Fabien Baradel, Austin Myers, Carl Vondrick, Kevin MurphyそしてCordelia Schmidが含まれます。実験を大いに促進したすばらしいツールを共有してくれたJack Hessel、Bo Pang、Radu Soricut、Baris Sumengen、Zhenhai Zhu、およびBERTチームに感謝します。また、有益な議論をしてくれたJustin Gilmer、Abhishek Kumar、Ben Poole、David Ross、およびRahul Sukthankarに感謝します。
3.VideoBERT:ビデオ内の画像と音声を組み合わせて学習(3/3)関連リンク
1)ai.googleblog.com
Learning Cross-Modal Temporal Representations from Unlabeled Videos
2)arxiv.org
VideoBERT: A Joint Model for Video and Language Representation Learning
Contrastive Bidirectional Transformer for Temporal Representation Learning
Representation Learning with Contrastive Predictive Coding
