
1.GWASkb:ゲノムワイド関連解析情報を論文から自動抽出(5/6)まとめ
・新規にGWASkbに収集された多様体の効果量は他と比較して大きかった
・非構造化テキストから構造化関係を抽出することは、情報抽出システムの主題
・機械による情報抽出は今後の研究やキューレーションを加速させるポテンシャルを持つ
2.GWASkbと他のGWAS関連データベースとの比較
以下、www.nature.comより「A machine-compiled database of genome-wide association studies」の意訳です。元記事は2019年7月26日、Volodymyr Kuleshovさん、Jialin Dingさん、Christopher Voさん、Braden Hancockさん、Alexander Ratnerさん、Yang Liさん、Christopher Réさん、Serafim BatzoglouさんとMichael Snyderさんによる投稿です。
新規にGWASkbに収集された多様体の効果量(effect sizes)の調査
最後に、新規多様体から予測される表現型およびその他の関連する特性が影響を与える大きさを分析しました。具体的には、LD Hub project から無料で入手できるGWAS要約統計を使用して、新規多様体全体のSNP効果量の分布を評価し、ランダムSNPの分布と比較しました。
要約統計が利用できるデータセットで最も頻繁に使用される11の特性に注目しました。 各特性について、その特性の効果量(ベータ係数または対数オッズ比の形式で)を提供するLD Hub研究を特定しました。図4は、GWASkbで特定された新規多様体の効果量の分布と全てのSNPの効果量の分布の比較です。前項と同様にGWASデータベース内の他の多様体と同じLDではない多様体に限定しています。
予想されるように、ランダムSNPの分布はゼロを中心にしていますが、新しいSNPの効果量は異なる分布(コルモゴロフ-スミルノフ検定、図4および補足図1および2を参照)に従っており、予想よりも大幅に大きい傾向があります。
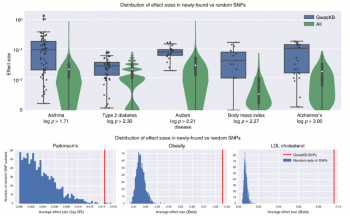
図4.GWASkbで特定された多様体の効果量の視覚化
上図:複数の形質について、GWASkb(青)で特定された多様体の効果量(ベータ係数の絶対値または対数オッズ比; LD Hubのデータより)の分布を全ての多様体(緑)の分布と比較しています。青い多様体の効果量はゼロから離れてクラスタ化し、異なる分布に従っています。(コルモゴロフ-スミルノフ検定)。箱ひげ図は、中心線は中央値を表し、箱が表す境界は四分位範囲(25%-75%の範囲)、ひげ部分は統計的外れ値を除いて最小および最大の観測値の範囲です。下図:特定の疾患のGWASkb SNPのセットと同じ数の要素を持つ多様体を1000個ランダムに選択したランダムサブセットとの比較です。GWASkbバリアントの平均効果サイズ(赤)は、ランダムサブセットの平均効果サイズ(青)よりも大きくなっています。全ての設定で、人間が管理する既存のリポジトリに存在しない新しいGWASkb多様体のみを調べています。
討論
文献のキュレーション作業は重要です。GWASアソシエーションがデータベースに記録されていない場合、多くの実用的な目的、例えばSNP機能を予測するための機械学習システムのトレーニングなどで使用する事が出来ず、事実上データ欠落しているようなものです。
GWASの研究も費用がかかり(多くの場合、何万人もの被験者のジェノタイピングが含まれます)、結果を完全に記録しない事は研究資金の無駄に繋がります。GWASkbの作成に使用されたようなシステムは、人間のキュレーターに有用な候補を提供することにより、キュレーションプロセスを支援できます。
既存のGWASデータベースのほとんどは、複雑な研究デザインを理解および解析できる高度なトレーニングを受けた専門の科学者である人間のキュレーターによって構築されています。
手動のキュレーションは、高い人件費がかかりますが、正確で信頼できる結果をもたらします。(例えば、GWASカタログの関連付けは、最高の精度を得るために2人目のキュレーターによって検証されています)
キュレーションの代わりに、著者に調査結果をオンラインで直接報告するよう依頼することもできます。これは、GWAS Central内ですでに実行可能になっていますが、実際にはこれを選択する著者はほとんどいません。更に、過去の研究をキュレートする必要があります。理想的な解決策は、作成者、マシン、キュレーターの組み合わせであるようです。
ただし、手動キュレーションは困難なタスクであり、特定の関連付けを見逃す可能性があります。 論文のキュレーションは、テキストの短い断片を検索するために高度に技術的な資料を閲覧することを含む、退屈な作業であることがよくあります。
通常、人間はこの種の作業には適していません。誤ってテーブルの行をスキップしたり、疲れて段落をスキップしたりする場合があります。 キュレーションには、LDや多重仮説検定などの高度な技術概念を理解することも必要です。 このため、タスクはクラウドソーシングを使って不特定の作業者に依頼するアプローチは適していません。
一方、コンピューターは前述の制限を受けません。繰り返し作業に優れており、一度だけ専門家がプログラミングする必要があります。 重要なのは、マシンが間違いを犯しても、これらのエラーは体系的であり、ランダムではないことです。
十分なレベルの精度に達するまで、これらのエラーを修正してシステムを再展開する反復プロセスを実行することができます。システムの再デプロイ作業には数時間かかりますが、人間にエラーを報告して修正を求めるには少なくとも数か月かかります。
もちろん、人間には機械よりも多くの利点があります。 実際、GWASkbと人間がキュレーションした関連性のセットはまったく異なっていました。 最も正確で完全なGWASデータベースは、実際には両方のソースの組み合わせです。 将来的には、キュレーションは人間と機械の間のコラボレーションと見なされるようになるでしょう。
非構造化テキストから構造化関係を抽出することは、情報抽出システム(IE:Information Extract)の主題です。 IEは、ニュース、金融、地質学、生物医学などのさまざまな分野で広く使用されています。 生物医学の分野では、IEシステムを使用して電子医療記録を解析し、薬物間相互作用を識別し、遺伝子型と薬物応答を関連付けています。
相当な労力が、生物医学文献から遺伝子/疾患の関連を明らかにすることに費やされました。ただし、個々の多様体の影響を特定しようとするため、これらのアプローチでは別のアプローチを採用しています。最近、ジャイン等はIEをGWASドメインに適用しました。彼らの研究は、論文の表現型と主題の共起表現(同じ文書の中で使われる別の表現の総称)という2つの特定の関係の抽出子を作成することに焦点を合わせていました。
これらの抽出プログラムは、precision-at-2で87%の精度と83%のF1スコアを達成しました。対照的に、私達の研究では、完全な関係性(表現型、rsid、p値)を、手作業でキュレーションされたデータベースで見られるものと同等に抽出するエンドツーエンドシステムを導入しています。
GWASの研究を超えて、現在、がんのゲノミクス、ゲノム薬理学、および他の多くの分野で文献キュレーションの取り組みが進行中です。私達の今回の調査結果は、それらの分野でマシンキュレーションを使用する可能性も示唆しています。
多様体に標準化された識別子が存在し、多くの情報がテーブルに構造化されているため、GWAS領域の研究は他の科学的分野よりも多くの点で簡単です。それにもかかわらず、マシンキュレーションの重要性を実証し、他の領域に一般化できるコアシステムを開発することができます。
GWASのセッティングで、多様体に関する追加情報(たとえば、リスクアレルやオッズ比)を抽出することにより、システムをさらに改善できます。更に、現在のバージョンのデータベースには、研究デザイン、研究段階、祖先情報、統計的方法論などの重要な研究メタデータは含まれていません。これらは通常、人間の専門家によってキュレーションされています。
要約すると、ゲノムワイド関連解析研究を解説する出版物から構造化データベースを自動抽出するための機械による自動読み取りシステムを導入しました。私達の研究結果は、人間のキュレーターが生物医学文献の知識を統合し、GWASの研究をより迅速かつ正確にするために役立つ機械による自動読み取りアルゴリズムの使用を前進させるステップを表しています。
3.GWASkb:ゲノムワイド関連解析情報を論文から自動抽出(5/6)関連リンク
1)www.nature.com
A machine-compiled database of genome-wide association studies
2)github.com
kuleshov/gwaskb
3)gwaskb.stanford.edu
GWASKB
