
1.多言語化対応したユニバーサルセンテンスエンコーダーで意味検索(1/2)まとめ
・USEは文章を特徴表現ベクトルに変換する汎用の文章embedding化モデル
・この度、多言語化対応と機能追加した3つのモジュールがリリース
・多言語化された意味的類似性検索と翻訳ペア検索が含まれる
2.多言語化対応したユニバーサルセンテンスエンコーダー
以下、ai.googleblog.comより「Multilingual Universal Sentence Encoder for Semantic Retrieval」の意訳です。元記事の投稿は、2019年7月12日、Yinfei YangさんとAmin Ahmadさんによる投稿です。
昨年発表されて以来、「Universal Sentence Encoder(USE) for English」はTensorflow Hubで最もダウンロードされたトレーニング済みテキストモジュールの1つとなりました。USEは、文章を特徴表現ベクトルに変換する汎用の文章embedding化モデルを提供しています。
これらのベクトルは、豊富な意味情報を捉えており、広範囲な分類タスクで分類子を訓練するために使用できます。
例えば、強い感情を分類する分類子は、わずか100個のラベル付きサンプルからトレーニングすることができます。そして、非常に少ないデータ量で学習したにも関わらず、意味的な類似性を測定する事や、意味ベースのクラスタ化のためにこの分類子を使用することができます。
本日、追加機能と潜在的アプリケーションとして3つの新しいUSE多言語モジュールのリリースを発表します。
最初の2つのモジュールは意味的に類似したテキストを検索するための多言語モデルを提供します。1つは検索パフォーマンスを向上するために最適化され、もう1つはスピードとメモリ使用量を削減する事に最適化されています。
3番目のモデルは、16の言語の質問回答検索(USE-QA)に特化したもので、新しいUSEアプリケーションです
3つの多言語モジュールはすべて、英語の元のUSEモデルと同様に、マルチタスクデュアルエンコーダフレームワークを使用してトレーニングされています。その一方、デュアルエンコーダを改善するために開発した新しい「付加的マージンソフトマックスアプローチ(additive margin softmax approach)」も使用しています。
これらは、優れた転移学習パフォーマンスを維持するためだけでなく、意味検索タスク(semantic retrieval tasks)が上手く機能するように設計されています。
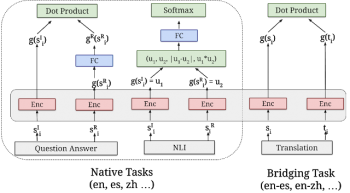
ユニバーサルセンテンスエンコーダのマルチタスクトレーニング構造。
さまざまなタスクとタスク構造が、共有のエンコーダレイヤ/パラメータ(ピンク色のボックス)を介して結合されています。
意味検索アプリケーション(Semantic Retrieval Applications)
3つの新しいモジュールはすべて意味検索アーキテクチャ上に構築されています。これは通常、質問と回答のエンコードを別々のニューラルネットワークに分割しており、ミリ秒以内に数十億の潜在的な回答を検索できます。
デュアルエンコーダを使用して効率的な意味検索を実現するための鍵は、予想される入力クエリに対する全ての回答候補を事前に符号化し、最近傍問題を解決するために最適化したベクトルデータベースにそれらを格納する事です。これにより、多数の候補の中から正確に回答を検索し高い正確性を実現する事ができます。
3つのモジュール全てで、入力クエリは近似最近傍検索を実行できるようにベクトルにエンコードされます。これにより、全候補に対して直接クエリ/候補比較を行わなくとも、適切な結果を素早く見つけることができます。試作版の全体の流れを以下に示します。

意味検索システムの試作版の処理の流れ
テキストの類似性を検索しています。
意味的類似性検索モジュール(Semantic Similarity Modules)
文章同士の持つ意味が類似しているかどうかを検出する意味的類似性タスクの場合、クエリと候補は同じニューラルネットワークを使用してエンコードされます。新しいモジュールによって可能になった2つの共通する意味検索タスクには、「多言語テキストに関する意味的類似性検索」と「多言語テキストに関する翻訳ペア検索」が含まれます。
1)多言語テキストに関する意味的類似性検索
ほとんどの既存手法は、意味的に類似した文章を見つけるために、比較用の一対のテキストを必要とします。しかし、Universal Sentence Encoderを使用すると、意味的に類似したテキストを非常に大きなデータベースから直接抽出できます。
例えば、FAQ検索のようなアプリケーションでは、システムは最初に、「関連する質問とそれに対応する回答」を全て、索引付けすることができます。その後、ユーザーのクエリ(質問)が与えられると、システムは意味的に類似している既知の質問とそのペアを検索し、答えを提供する事ができます。
ウィキペディアの5000万文から意味的に類似する文を見つけるために、同様のアプローチが使用されました。新しい多言語USEモデルでは、これを英語以外のサポートされている言語で実行できます。
2)多言語テキストに関する翻訳ペア検索
新しくリリースされたモジュールは、ニューラルマシン翻訳システムをトレーニングするための翻訳ペアを見つけ出すためにも使用できます。
ある言語の原文(「How do I get to the restroom?」)を元に、サポートされている他のどんな言語でも潜在的な翻訳語「¿Cómo llego al baño?(訳注:スペイン語でトイレはどこですか?)」を見つける事ができます。
2つの新しい意味的類似性モジュールは言語横断的です。たとえば中国語でクエリ(質問文)が入力された場合でも、モジュールは他言語で書かれた文章から最良の回答候補を見つけることができます。
この汎用性は、インターネットではあまり使われていない言語で特に役立ちます。例えば、これらのモジュールの初期バージョンは2018年にChidambaram等によって使用されましたが、トレーニングデータが単一の言語(英語)しか利用できない状況での分類機能を提供しました。
しかし、実際に使われるシステムは他のさまざまな言語で機能しなければなりません。
3.多言語化対応したユニバーサルセンテンスエンコーダーで意味検索(1/2)関連リンク
1)ai.googleblog.com
Multilingual Universal Sentence Encoder for Semantic Retrieval
2)arxiv.org
Multilingual Universal Sentence Encoder for Semantic Retrieval
