1.GoogleのAI研究チームの2017年成果プライバシーとセキュリティまとめ
・昨年のGoogleBrainの研究成果にプライバシーとセキュリティに関わるものがあった
・プライバシーは病歴等のセンシティブな個人情報を保護しながら学習する手法について
・セキュリティは黒人の写真にゴリラとタグ付けするような誤認識を目的とする悪意あるデータに対する備え
2.人工知能のプライバシー研究とセキュリティ研究
もう2月になってしまったが、いまだにGoogleBrainの去年の成果を全部読めていない。ここ最近、画像認識や音声認識に対する攻撃、つまり、悪意あるデータを入力して誤認識させる論文が話題になった。そういえば、成果の中にセキュリティがあったなぁ、と改めて読んでみたらやはり悪意あるデータに対する備えだった。
だがその前にまずはプライシー。センシティブな個人情報を直接、学習するのではなく、分割された個人情報を扱う教師達とそのとりまとめ教師vs生徒、と言う形式で学習をさせるらしい。下記図解が大変わかりやすい。
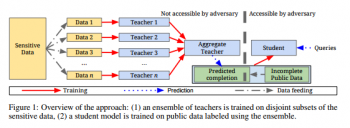
Semi-supervised Knowledge Transfer for Deep Learning from Private Training Dataより引用
さて、プライバシーは、まず2014年末の段階でGANで有名なグッドフェローさんが論文だしていて、その中で面白い図を投稿していた。

Explaining and Harnessing Adversarial Examplesより引用
・左の絵:パンダの確率57.7%と認識される
・真ん中の絵:線形動物の確率8.7%と認識される
・右の絵(左の絵と真ん中の絵を組み合わせた絵):テナガザルの確率99.3%と認識される。
この現象、つまり「人工知能が悪意あるデータに脆弱で、何故か凄い確信をもって間違う事」は理論的に良くわかっていなかったのだけど、論文中でこの現象について説明をつけた。更に、その理論に基づいて悪意あるデータを簡単に作る方法、及びそれを使ってAdversarial Machine Learning(悪意あるデータに耐性をつける学習方法)について論じていた。
2017年の活動として、現実世界の悪意あるデータの例についての発表や、Adversarial Machine Learningを巨大なデータを使って実現した結果についての論文が発表されているとの事。
近い将来、黒人をゴリラと誤認識させるとか、ヒトラーは正しいとチャットボットに覚え込ませるとかそういった人間の悪戯レベルの悪意あるデータは全部対策されると思う。そして、「悪意あるデータを作り出す人工知能」 対 「それに騙されまいと頑張る人工知能」の永遠のいたちごっこになりそう。まぁ、いたちごっこは人工知能に限った話ではなくてセキュリティの世界の宿命だけど。
3.GoogleのAI研究チームの2017年成果プライバシーとセキュリティ参考リンク
1)arxiv.org
Semi-supervised Knowledge Transfer for Deep Learning from Private Training Data
Explaining and Harnessing Adversarial Examples
Adversarial Machine Learning at Scale
2)GoogleResearch
Adversarial examples in the physical world


コメント