
1.Weak Supervision:機械学習のための新しいプログラミングパラダイム(3/4)まとめ
・ラベル付け関数の出力をジェネレータの出力を見なせば、GANのような生成モデルと見なす事が出来る
・Snorkelと手作業のラベル付けの生産性を比較すると2.8倍速くモデルを学習可能で測性能も平均45.5%上昇
・テキストからの抽出タスクやテキストと画像に関するタスクでもSnorkelは平均132%の改善をもたらした
2.生成モデルとしてのシュノーケル
以下、ai.stanford.eduより「Weak Supervision: A New Programming Paradigm for Machine Learning」の意訳です。元記事は2019年3月10日、Alex Ratnerさん, Paroma Varmaさん, Braden Hancockさん, Chris RéさんとHazy Labの皆さんによる投稿です。
生成モデルとしての側面
私達のアプローチは、ラベル付け関数で生成モデルを暗黙的に描写していると見なす事ができます。
生成モデルについて簡単に説明すると、未知のラベルyを持つデータxが与えられたとします。私達はyを予測したいのですが、判別アプローチではP(y|x)を直接モデル化し、生成アプローチではP(x, y) = P(x|y)P(y)をモデル化します。
私達のアプローチでは、トレーニングセットのラベル付けプロセスP(L,y)をモデル化します。ここで、Lはオブジェクトxのラベリング関数によって生成されたラベル、yはxに対応する(未知の)真のラベルです。生成モデルを学習させ、P(L|y)を直接推定させます。ラベル付け関数の相対的な正確さは、それらがどのように重複したり矛盾しているかに基づいて本質的に学習されていきます。(真のラベルであるyを知る必要はないのです!)。
訳注:GANは、偽札作り(ジェネレータ)と偽札か否かを判別する警官(ディスクリミネータ)が相互に競い合って、偽札の品質を上げていく事に例えられる事があります。同様に、Snorkelが作るラベルをジェネレータの出力と見なし、そのラベルの品質を評価してフィードバックするディスクリミネータ的な仕組みと繋げてやれば、GANのような生成モデルと見なす事が出来るって事ですね、頭イイですね。
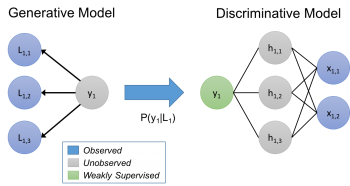
ラベリング関数に対して生成モデルを使用し、識別モデルにノイズを意識させながら学習させます。生成モデルは、訓練データの未知のラベルに対してその確率を推論し、そして次に、これらの確率に関して識別モデルは予想損失を最小にするようにします。
これらの生成モデルのパラメータを推定することは、特に使用されるラベリング関数の間に統計的な依存関係がある場合(ユーザー表現型または推定型のいずれか)、非常に難しい場合があります。私達の研究では、十分なラベリング関数が与えられれば、教師付き学習と同じ漸近スケーリングを得ることができることを示しています。また、ラベル付きデータを使用せずにラベル付け関数間の相関関係を学習する方法と、パフォーマンスを大幅に向上させる方法についても説明しています。
実世界のシュノーケルからの特記事項!
Snorkelに関する最近の論文では、さまざまな実世界のアプリケーションにおいて、現代のMLモデルと対話するためにこの新しいアプローチが非常にうまく機能することがわかりました。 ハイライトは次のとおりです。
(1)Mobilize Centerが主催するSnorkelに関する2日間のワークショップの一環として行われたユーザー調査では、SME(ラベル付け出来るほど専門知識を持つ専門家)にSnorkelの使用方法を教える事による生産性と、手作業でデータをラベル付ける事の生産性を比較しました。その結果、2.8倍速くモデルを学習できただけでなく、構築したモデルの予測性能も平均45.5%上回りました。
(2)スタンフォードと米国退役軍人局、および米国食品医薬品局の研究者と共同した2つの実世界のテキスト関係抽出タスク、及び、4つのベンチマークのテキストと画像のタスクで、Snorkelは比較対象のベースライン技術と比較して平均132%の改善をもたらすことがわかりました。
(3)ユーザー提供のラベリング関数をどのようにモデル化するかという新規のトレードオフスペースを探求し、反復開発サイクルを加速するルールベースのオプティマイザーを導きました。
3.Weak Supervision:機械学習のための新しいプログラミングパラダイム(3/4)関連リンク
1)ai.stanford.edu
Weak Supervision: A New Programming Paradigm for Machine Learning
2)arxiv.org
Data Programming: Creating Large Training Sets, Quickly
Learning the Structure of Generative Models without Labeled Data
Snorkel: Rapid Training Data Creation with Weak Supervision
