
1.教師なし学習による特徴表現解きほぐし手法の評価(2/2)まとめ
・帰納的バイアスがなければ解きほぐした特徴表現の教師なし学習は不可能である
・解きほぐしが下流タスクに有用であるという仮定は検証できなかった
・将来の研究を促進するためにdisentanglement_libがオープンソースとして公開された
2.disentanglement_libとは?
以下、ai.googleblog.comより「Evaluating the Unsupervised Learning of Disentangled Representations」の意訳です。元記事は2019年4月24日、Olivier Bachemさんによる投稿です。
研究コミュニティは、変分オートエンコーダに基づいて特徴表現を解きほぐす様々な教師なしアプローチや評価基準を提案しています。しかし、私達の知る限りでは、これらのアプローチを統一的に評価した大規模な実証的研究は存在しません。
今回、私達は6つの異なる最先端モデル(BetaVAE、AnnealedVAE、FactorVAE、DIP-VAE I/II、Beta-TCVAE)と6つの解きほぐし基準(BetaVAE score, FactorVAE score, MIG, SAP, Modularity, DCI Disentanglement)を実装することにより、教師なし解きほぐし学習をベンチマークするための、公正で再現可能な実験プロトコルを提案します。合計で、私達は7つのデータセットで12,800のモデルを訓練し評価しました。私達の研究の主な結果は次のとおりです。
・今回検証されたモデルが、解きほぐし表現を教師なしで確実に学習出来るという実証的証拠はありません。ランダムシードとハイパーパラメータがモデルの選択以上に影響しているようです。
言い換えれば、多数のモデルを訓練し、それらのうちのいくつかが解きほぐしが実現できているとしても、これらの解きほぐし表現は一見したところ真のラベルにアクセスできなければ解きほぐしができていないようです。更に、私達の研究では、良いハイパーパラメータ値がデータセット間で一貫していないように見えます。
これらの結果は、私達が論文で提示している定理と一致しており、それはデータセットとモデルの両方に帰納的バイアスがなければ解きほぐした特徴表現の教師なし学習は不可能であると言う事です。(帰納的バイアスとは、データセットについて何らかの仮定をし、それらの仮定をモデルに組み入れる事。これにより、学習時に見た事がないデータを予測する事ができるようになる)
・検討されたモデルおよびデータセットでは、解きほぐしが下流タスクに有用であるという仮定、例えば、解きほぐし特徴表現があれば、より少ないラベル付きデータで学習することが可能であるという仮定を検証することはできませんでした。
以下の図はこれらの発見のいくつかを示しています。ランダムシードの選択は、モデルの選択や正則化の強さよりも、解きほぐしスコアに大きな影響を及ぼします(一方で、正則化を強めると、常により多くの解きほぐしが解消されるはずです)。不適切なハイパーパラメータを使用した適切な実行は、適切なハイパーパラメータを使用した不適切な実行を簡単に上回ります。
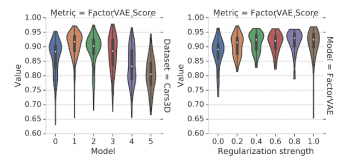
バイオリン図は、Cars3Dデータセットのさまざまなモデルによって得られたFactorVAEスコアの分布を示しています。左図は異なる解きほぐしモデルが適用されたときに分布がどのように変化するかを示していますが、右のプロットはFactorVAEモデルの正則化強度が変化した時の分布の異なり具合を示しています。重要な観察は、バイオリン図が実質的に重なっていることであり、これは全ての手法がランダムシードに強く依存していることを示しています。
これらの結果に基づいて、私達は将来の研究に関して4つの提言をします。
1.帰納的バイアスなしに解きほぐし表現の教師なし学習は不可能であるという理論的結果を考えると、今後の作業では、課された帰納的バイアスと、暗黙的および明示的な教師の役割について明確に説明する必要があります。
2.複数のデータセットにわたって機能する教師なしモデルを選択するための優れた帰納的バイアスを見つけることは、重要な未解決問題として存続します。
3.解きほぐし特徴表現の学習で特定の概念を強制することの具体的な実用的利点は実証されるべきです。有望な方向にはロボット工学、抽象的な推論および公平性が含まれます。
4.実験は多様なデータセットを選択した上で再現可能な設定で行われるべきです。
disentanglement_libのオープンソース化
他の人が私たちの結果を検証するために、実験的研究を実施する際に使用したライブラリーであるdisentanglement_libを公開しました。この中には、研究内で検討された解きほぐし方法と測定基準、標準化されたトレーニングと評価のプロトコル、およびトレーニングされたモデルをよりよく理解するための視覚化ツールのオープンソース実装が含まれています。
このライブラリの利点は3つあります。まず、わずか4つ以下のシェルコマンドで、disentanglement_libを使って私たちの研究のモデルを再現することができます。 第二に、研究者は私達の研究を簡単に修正して追加の仮説を検証することができます。3つ目は、disentanglement_libは簡単に拡張でき、解きほぐし表現の学習に向けた研究を促進するために使用できます。新しいモデルを実装し、公正で再現性のある実験設定を使用して元々の実装と比較するのは簡単です。
私達の研究で使った全てのモデルを再現するためにはおよそ2.5年間分のGPUと言う法外な計算が必要になります。そのため、disentanglement_libと一緒に使用できる、10,000を超える事前学習済みdisentanglement_libモデルも公開しました。
他の研究者の皆さんも事前訓練済みモデルを使って彼らの新しいモデルをベンチマークし、多様なモデルセットが新しい解きほぐし測定基準と視覚化アプローチをテストする事が可能にです。これにより、この分野の研究が加速することを願っています。
謝辞
この研究は、Google AI Zürich、ETHZürich、およびMax-Planck Intelligent Systems研究所の共同研究でFrancesco Locatello, Mario Lucic, Stefan Bauer, Gunnar Rätsch, Sylvain GellyとBernhard Schölkopfによって行われました。私達はまた、Josip Djolonga, Ilya Tolstikhin, Michael Tschannen, Sjoerd van Steenkiste, Joan Puigcerver, Marcin Michalski, Marvin Ritter, Irina Higgins、及びGoogle Brain teamの皆さんに、有益な議論、コメント、テクニカルヘルプ、コードの提供に感謝の意を表します。
3.教師なし学習による特徴表現解きほぐし手法の評価(2/2)関連リンク
1)ai.googleblog.com
Evaluating the Unsupervised Learning of Disentangled Representations
2)arxiv.org
Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations
