
1.SimPLe:ビデオモデルを用いてポリシー学習をシミュレート(2/2)まとめ
・SimPLeはモデルベース強化学習でありサンプル効率性が高い
・他のモデルフリー強化学習の2倍程度のサンプル効率性を達成
・モデルフリー強化学習のパフォーマンスにはまだ及ばないが発展性がある
2.SimPLeのサンプル効率性
以下、ai.googleblog.comより「Simulated Policy Learning in Video Models」の意訳です。元記事は2019年3月25日、Łukasz KaiserさんとDumitru Erhanさんによる投稿です。
私たちの世界モデルは、4つのフレームを用いて次のフレームと報酬を予測するフィードフォワード畳み込みネットワークです(前述の図を参照)。
しかし、Atariのゲーム場合、前の4フレームの範囲だけで予測すると、未来はまだ定まっていません。
たとえば、Pong(訳注:シンプルなホッケーゲーム、ブロックがないブロック崩し)でボールがフレームから外れてリスタートする時など、4フレームを超えるゲームの一時停止は、モデルが予測に失敗して後続のフレームを正常に予測できないことがあります。
私たちは、このような確率論的問題を、以前の研究に触発されて、こういった状況により上手く対処できる新しいビデオモデルアーキテクチャで処理します。

確率論から生じる問題の一例は、SimPleモデルをKung Fu Master(訳注:オリジナルはアイレムのアーケードゲームであるスパルタンXですね。アクティビジョン社がAtari 2600に移植しています。映画が元ネタなのですが映画のストーリーとゲーム内容が全く関係ないのが印象に残っているゲームです。)に適用したときに見られます。このアニメーションでは、左側がモデルの出力、真ん中が本当のゲームの画面、右側のパネルが両者の画素単位での違いです。この例ではモデルは異なる数の敵を予測しており実際のゲームから逸脱しています。
各反復において、世界モデルが訓練された後、私達はこの学習済みシミュレータを使用して、ゲームのプレイポリシーを改善するために使用するロールアウト(すなわち一連の行動、観察および結果)を生成します。これにはPPO(Proximal Policy Optimization)アルゴリズムが使用されています。
SimPLeを機能させるための1つの重要な事は、ロールアウトのサンプリングが本当のデータセットのフレームから始まることです。予測誤差は通常、時間の経過とともに大きく複雑になり、長期的な予測が非常に困難になるため、SimPLeは中規模のロールアウトのみを使用します。
幸いなことに、PPOアルゴリズムはアクションと報酬の間の長期的な効果をその内部価値関数からも学ぶことができるので、Freeway(訳注:日本で言えば、フロッガー的なゲームです。左右から来る車にぶつからないように鶏を操作してハイウェイを上下に突っ切らせるゲームです。下の方に実際のプレイ画面が出てきます。)のようなまばらな報酬のあるゲームでも限られた長さのロールアウトで十分です。
SimPLeの効率
成功を測るの1つの尺度は、モデルが非常に効率的であることを実証することです。このため、10万回ゲームをプレイさせた後のポリシーの出力を評価しました。これは、1人の人間による約2時間のリアルタイムゲームプレイに相当します。26種類のゲームで、私たちのSimPLeを使った手法と最先端のモデルフリー強化学習であるRainbowとPPOとを比較しました。ほとんどのゲームで、SimPLeを使ったアプローチは他の手法よりも2倍以上優れたサンプル効率を達成しました。
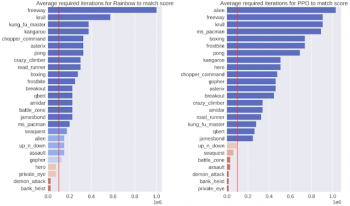
SimPLeを使用して達成されたスコアと同じスコアを出すために、それぞれのモデルフリーアルゴリズム(左:Rainbow、右:PPO)が必要としたインタラクションの数(訳注:ゲームプレイ数の数)。 赤い線は、SimPLeが使用したインタラクションの数を示しています。
SimPLeの成功
SimPLeアプローチの素晴らしい成果は、PongとFreewayの2つのゲームで、シミュレートされた環境で訓練されたエージェントが最大スコアを達成できるということです。 以下は、Pongで学んだゲームモデルを使用してエージェントがゲームをプレイしているビデオです。

下に示すように、Freeway、Pong、およびBreakoutの場合、SimPLeは最大50ステップ先まで、ほぼ実際のゲーム画面に等しい等しい予測を生成できます。
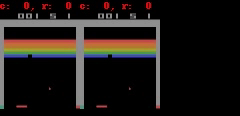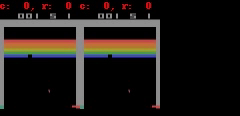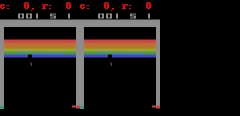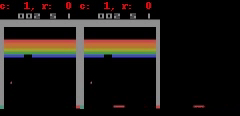
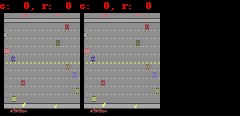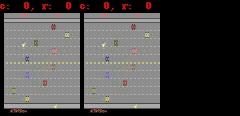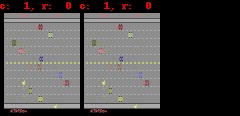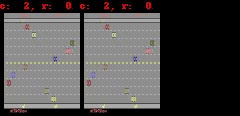
SimPLeは、Breakout(上)とFreeway(下)のゲーム画面を画素単位で完全に予測できています。左側がモデルの予測出力、真ん中が実際のゲーム画面、右側が両者のピクセル単位での違いです。
SimPLeの驚き
しかしながら、SimPLeは常に正しい予測をするわけではありません。最も一般的な失敗は、世界モデルが「表示は小さいけれども非常にゲーム内容に影響を及ぼすオブジェクト」を正確にキャプチャまたは予測できていない事です。
具体例としては(1)「Atlantis」と「Battlezone」というゲームでは画面に表示される弾丸が非常に小さいために消えてしまう傾向があります(2)「Private Eye」ではエージェントが様々なシーンをテレポートして移動します。私達のモデルは一般にこのような大規模な画面の変化を捉えるのに苦労している事がわかりました。
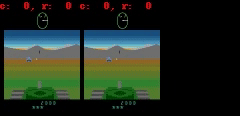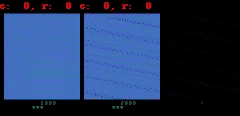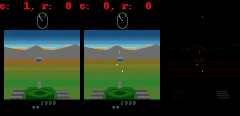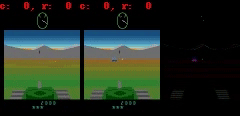
Battlezoneでは、弾丸のように小さいけれどもゲーム内容に関連性のある部分を予測する事にモデルは苦戦しています。
まとめ
モデルベースの強化学習の活躍が見込まれるフィールドは、ロボットが行っている多くの作業のように、実際に経験させる事が高価、もしくは時間がかかる、または人間によるラベル付けを必要とするような環境です。そのような環境では、学習シミュレータはエージェントが周辺環境をよりよく理解することを可能にし、マルチタスク強化学習を行うための新しく、より良くそしてより速い方法を導きます。SimPLeは標準的なモデルフリー強化学習のパフォーマンスにはまだ及びませんが、サンプル効率では実質的により効率的です。今後の作業により、モデルベース手法のパフォーマンスが更に向上される事が期待されます。
もし、あなたがあなた自身のモデルの開発や実験を行いたいならば、私達が公開しているGitHubリポジトリとColabを見てください。そこでは事前に訓練された世界モデルと今回の研究を再現する方法についてのインストラクションが公開されています。
謝辞
この研究は、イリノイ大学アーバナシャンペーン校、ワルシャワ大学およびdeepsense.aiと共同で行われました。共著者のMohammad Babaeizadeh、PiotrMiłos、BłażejOsiński、Roh H Campbell、Konrad Czechowski、Chelsea Finn、Piotr Kozakowski、Sergey Levine、Ryan Sepassi、George Tucker、Henryk Michalewskiに特別な感謝をしたいと思います。
3.SimPLe:ビデオモデルを用いてポリシー学習をシミュレート(2/2)関連リンク
1)ai.googleblog.com
Simulated Policy Learning in Video Models
2)arxiv.org
Model-Based Reinforcement Learning for Atari
3)github.com
tensorflow/tensor2tensor
4)colab.research.google.com
Tensor2Tensor Reinforcement Learning
