
1.Stable Diffusionの新VersionであるStable Diffusion XL(SDXL)をComfyUIで動かす方法まとめ
・前評判が高かったStable Diffusion XL、略称SDXLという新世代のStable Diffusionが2週間前に公開されたのでColabとローカルで評価をした入門記事
・Stable Diffusion用に人気の高いAUTOMATIC1111はまだ完全にSDXLに対応していないのでComfyUIというツールで動かすのが比較的簡単且つ拡張性がある
・画像品質の向上以外にも品質の高い画像が生成される割合があがっていそうなので少しずつStable Diffusion XLにも慣れていった方が良いかもしれない
2.Stable Diffusion XL(SDXL)の使い方
Stable Diffusion XL(SDXL)とは?
Stable Diffusion XL(SDXL)はイラスト生成AIとして一躍有名になったStable Diffusionの次世代版です。
Stable Diffusionは1.4、1.5、2.0、2.1の順で公開されてきましたが、Stable Diffusion XLではVersion番号も新しく採番されるようになり、2週間前に正式版としてStable Diffusion XL 1.0が公開されました。
久しぶりに公開された新しいStable Diffusionで「もうLoRAも不要になるかもしれないくらい様々なイラストを柔軟に高品質に生成できる!」と言う触れ込みで注目度はかなり高いのですが、私はまだ使いこなせていません。
理由はStable Diffusion 1.5用の資産(カスタムモデル、拡張機能、画像生成ワークフロー、モデル微調整用ツール、ノウハウ、プロンプト等)が多すぎて、簡単には移行出来ないからです。
移行の困難さはStable Diffusion 2.1の際にもありました。そして、
・2.1は1.5に比べて学習用データを限定したため自由度が下がった
・1.5用の資産が2.1ではスムーズに動かない
という2点から2.1はあまり普及せず、現在も1.5をベースにカスタマイズしたモデルが良く使われています。
開発元のStability AI社も移行の困難さは十分認識していたのか、Stable Diffusion XLは正式リリース前から人気の高いモデルや拡張機能の作成者に評価版としてStable Diffusion XL 0.9を提供していました。
しかし、最もシェアの高いAUTOMATIC1111(Stable Diffusionをブラウザから操作するためのソフトウェア)では豊富な拡張機能が裏目に出て、公開から2週間たった今でもまだSDXLの優位点をフルに活用する事ができません。現在もメモリ不足で動かす事が出来ない、非常に遅い、拡張機能が動かなくなる、等々の不具合報告をよく見かけます。
AUTOMATIC1111が対応に時間がかかっている理由の1つはSDXLが画像生成処理時の流れを大きく変えている事です。後でもう一度解説するので以下の図をよく見て欲しいのですが、Baseモデルで生成した潜在イメージ(Latent)をRefinerモデルで品質を向上させる二段階処理になったのです。
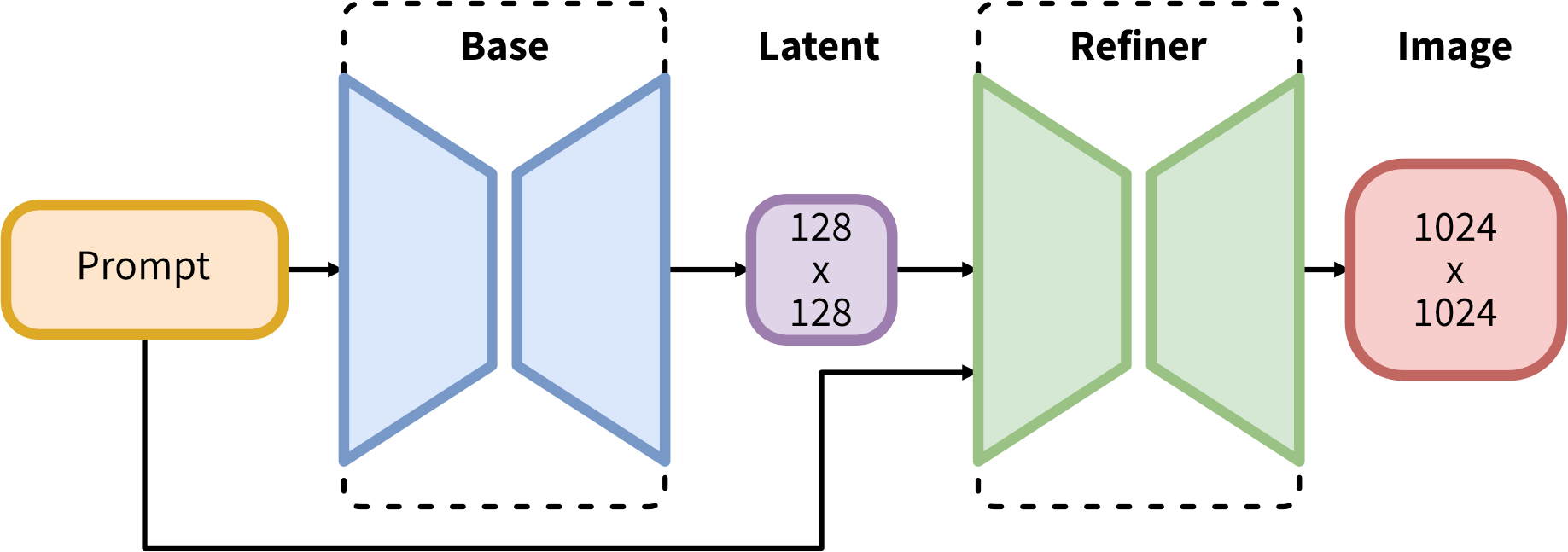
(huggingfaceのstabilityai/stable-diffusion-xlより引用)
Baseモデル単体でも動かす事は出来ますが、Base + Refinerという二段階処理を行う事でSDXLは最高の性能を発揮する事が出来ます。
(huggingfaceのstabilityai/stable-diffusion-xlより引用)
ComfyUIとは?
AUTOMATIC1111は複数の拡張機能を組み合わせて動かすケースなどもあり、処理の流れがかなり複雑化しています。そのため、SDXLの二段階処理に対応するのは一筋縄ではいかず、更に各拡張機能の作成者も個々に対応しなければならないので完全対応にはまだ時間がかかりそうです。この事情により、SDXLを気軽に試したいのであればComfyUIというWebツールを試すのが手っ取り早いとされています。
ComfyUIは、そもそもの出発点が技術者目線です。「画像生成時にそれぞれのモジュール(モデル/VAE/サンプラーなど)がどのように関連しているのか処理の流れをわかりやすく表現して理解しやすくしたい」なので、SDXLの二段階処理を比較的容易に取り込む事が出来、親和性が高いのです。
AUTOMATIC1111では「拡張機能Aの入力に使われるのは拡張機能Bの出力っぽいけれども、それでは拡張機能Cはどのタイミングでどの箇所に対して影響を与えているのだろう?」等、処理が見えにくい時がありました。これは仕組みを知らなくても動かせるという利点ではありますが、思う通りの画像が生成できない際の原因調査がとても難しいという側面でもありました。
それに対してComfyUIは各入出力を明示的に自分で繋げていくので、画像生成処理の流れが非常に明確化される反面、スパゲッティ的なごちゃごちゃした印象を受けて敷居が高く感じるかもしれません。
シンプルに画像が生成できれば十分と考えている人にとってはComfyUIは面倒で冗長かもしれませんが、画像生成AIの仕組みを深く知りたいと思っていた方にとってはおまじない的に使っていた部分の理解が深まり「なるほど!」と感激するかもしれません。
上記設計思想の違いにより、ComfyUIはAUTOMATIC1111と使用感がまるで違うため、AUTOMATIC1111を既に高度に使いこなしている人は「AUTOMATIC1111でいうXXX機能はComfyUIではどうやって実現すれば良いか?」と言う観点で考えてしまって、直感的に理解できずストレスが貯まると思います。
AUTOMATIC1111で出来る事はComfyUIでほぼ出来るようではありますが、そのためには高度なComfyUI知識が必要になるので「同じ事をするためにはどうすれば良いか?」という姿勢より「ゼロから新しいツールの使い方を学ぶ」姿勢が良いと思います。
なお、ComfyUIで生成された画像内には生成時の設定がMeta情報として含まれているので既存画像を参考にして色々と試すアプローチで行けば学習は比較的容易です。
ComfyUIはSD1.x、SD2.xにも対応しており、元々はgithub上で開発が行われているオープンソースソフトウェアでしたが、開発している方がStability AI社に雇用されたようなので、公式ツール的な位置付けになっていく可能性も感じています。
ComfyUIを無料版Colabで動かす
さっと体験するだけであったらComfyUIはインストールせずとも公式githubで提供されているColab notebookで無料で動かして体験する事ができます。以下の手順に沿って少し内容を編集すればStable Diffusion XLも無料で動かす事ができます。もちろん、ダウンロード部分を変更すればSD1.X、SD2.Xベースのモデルも動かす事が出来ます。
(1)Colabを開く
comfyui_colab.ipynb( https://colab.research.google.com/github/comfyanonymous/ComfyUI/blob/master/notebooks/comfyui_colab.ipynb )
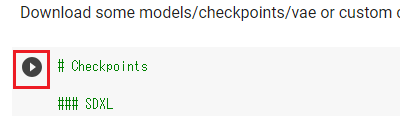
(2)Stable Diffusion 1.5用モデルとVAEをダウンロードする処理をコメントにする(下記の赤枠の行の行頭に # を挿入する)
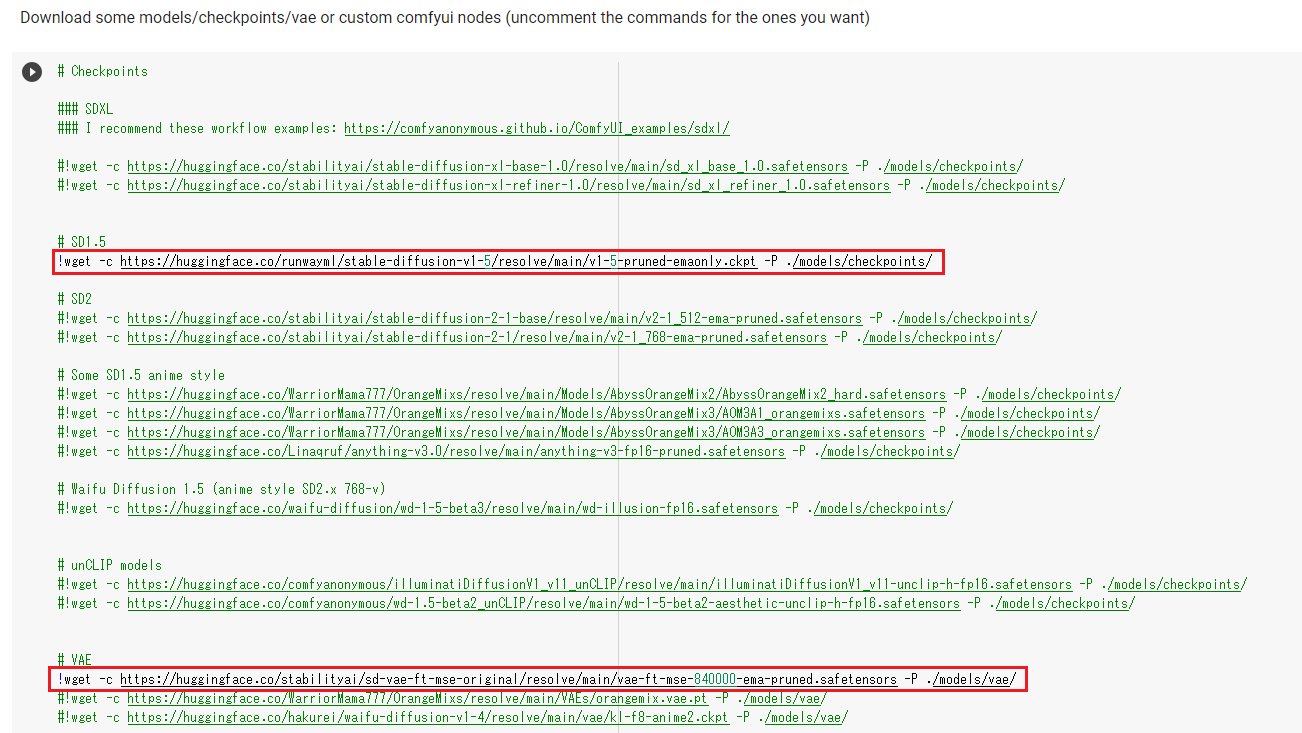
(3)Stable Diffusion XL用モデル/VAEをダウンロードする処理を追記する(青枠の行に以下を追加)

!wget -c https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/resolve/main/sd_xl_refiner_1.0_0.9vae.safetensors -P ./models/checkpoints/ !wget -c https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/sd_xl_base_1.0_0.9vae.safetensors -P ./models/checkpoints/
(4)上から順番に3つ目まで▷を押していく
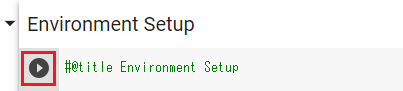
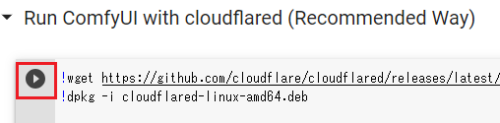
「Run ComfyUI with cloudflared (Recommended Way)」の部分までで大丈夫です。
(5)表示されたURLにアクセスする
![]()
ComfyUIの画面が表示されるので、本記事後半の「ComfyUIのローカルでの起動と使い方」で解説しているように操作してみてください。
ComfyUIのローカルPCへのインストール方法
公式サイトのマニュアル( https://github.com/comfyanonymous/ComfyUI )によればComfyUIはNVIDIAのGPUだけではなくAMDやIntel、Apple Mac siliconでも動くとの事です。
NVIDIA製GPU搭載のWindows用に7-Zip形式で固めたファイル一式( https://github.com/comfyanonymous/ComfyUI/releases )もあるので、こちらをダウンロードすれば特に細かいセットアップはせずともローカルで動かせそうです。(未検証)
以下、NVIDIAのGPU搭載のLinuxの環境でのセットアップ手順です。
既にpython 3.10とgit, wgetはインストール済の前提ですが、クリーンインストールで試したわけではないので他にも必要なものがあったら適宜インストールしてください。仮想環境(venv)を切り替える事によってAUTOMATIC1111と共存する事が可能です。
# venvでcomfyuiと言う名前の仮想環境を作成 python3 -m venv comfyui # 仮想環境を有効化 source comfyui/bin/activate # 事前に必要なパッケージをインストール pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu118 xformers #gitでファイル一式をダウンロード git clone https://github.com/comfyanonymous/ComfyUI # ComfyUIに必要なパッケージをインストール cd ComfyUI/ pip install -r requirements.txt # モデルをローカルにダウンロード # SDXL 1.0に組み込まれた(Bakeされた)VAE1.0にはアーティファクトが映りこむ不具合 # (フチの部分などに緑や紫のドットが映りこんでしまう不具合)があったので、 # 現在はVAE0.9が組み込まれている方のファイルを使います。 cd models/checkpoints/ # Baseモデル 約6G wget https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/sd_xl_base_1.0_0.9vae.safetensors # refinerモデル 約6G wget https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/resolve/main/sd_xl_refiner_1.0_0.9vae.safetensors # 元のディレクトリに戻る cd ../..
ComfyUIのローカルでの起動と使い方
仮想環境を有効化済(source comfyui/bin/activate 実施済)である事を確認後、ComfyUI配下で以下のコマンドを実行します。
python main.py # 以下、私の場合の起動時メッセージ Total VRAM 12045 MB, total RAM 64241 MB xformers version: 0.0.20 Set vram state to: NORMAL_VRAM Device: cuda:0 NVIDIA GeForce RTX 3060 : cudaMallocAsync Using xformers cross attention Starting server
これにより、ブラウザで ローカルアドレス(例:http://127.0.0.1:8188) にアクセスする事で起動できます。コマンドライン引数に –listen を付けると家庭内LAN等で他のPCからアクセスする事もできます。
そうするとブラウザに以下のようなメニューが出ると思うので一番下のLoad Defaultで初期設定をロードします。
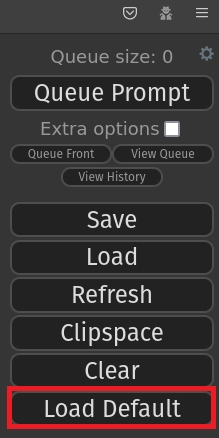
そうすると以下のような画面が表示されると思います。
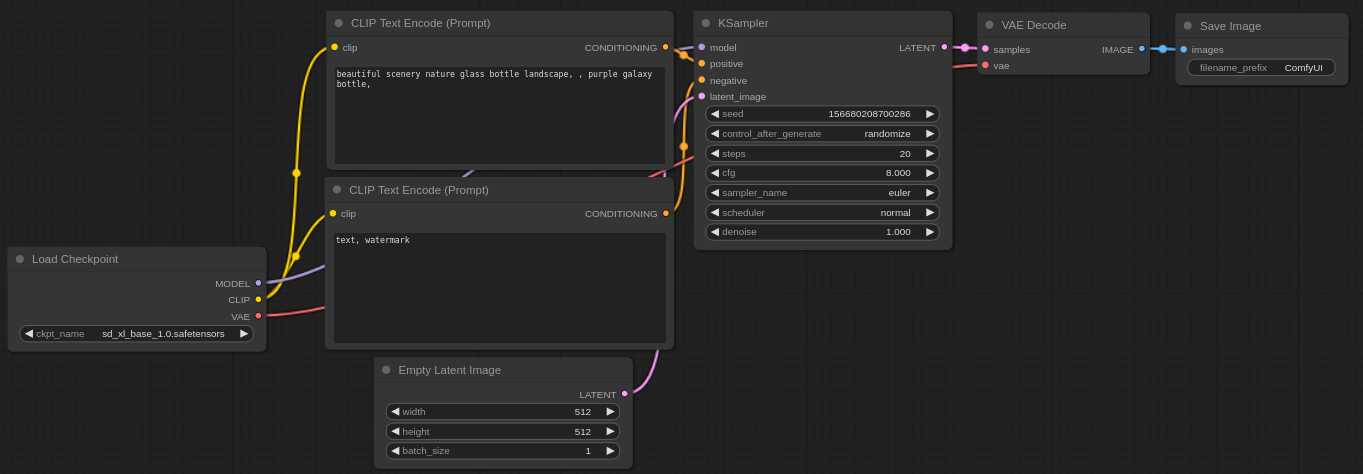
これは一番シンプルな画像生成用のフローです。問題なくセットアップ出来ていれば、先ほどのメニュー上部の「Queue Prompt」を押せばComfyUIが画像の生成を開始し、ComfyUI/output/ 配下に生成した画像が保存されます。
前述の通り、ComfyUIを使って作成された画像内には作成時のフローが保存されています。ComfyUIで作成した画像をインターネット等からダウンロードして先ほどのメニューのLoadボタンで読みこむとその画像を生成した際のフローを同様に読みこむ事が出来ます。ComfyUI Examples ( https://github.com/comfyanonymous/ComfyUI_examples )などで公開されているサンプル画像を読みこむ事でHires Fix、Img2Img、Inpainting、Lora、Embeddings、Upscale (ESRGAN等)などのAUTOMATIC1111でよく使われるテクニックのComfyUIでの実現方法を知る事ができ、非常に参考になります。なお、アップロードされた画像からMeta情報を自動で削除するサーバーも存在するので、全ての画像に生成時情報が含まれているわけではない事も知っておいてください。ComfyUI用のワークフロー共有サーバー Comfy.ICU ( https://comfy.icu/ )や後述のカスタムワークフローなどから参考フローを探すと良いでしょう。カスタムワークフローはpng画像以外にjson形式のテキストファイルで提供されている場合もあり、この場合もLoadボタンで読み込めます。
さて、さきほどLoadした初期設定のフローを細かく見ていくと、ふむふむ、
・Load CheckpointでCheckpointをロードし、そこからCLIP Text Encode(Prompt)でプロンプトを処理し、K Samplerに繋げる
・K Samplerにはモデルと空の潜在イメージを渡している。Step数等のパラメータは全部ここで処理
・Samplerの出力するlatentをVAE Decodeに渡して画像化し、Save Imageしている
・VAE DecodeのVAEはCheckpointに焼き込まれているVAEを使うのでLoad Checkpointから繋げる
等々で、なるほどなるほど、CLIPやVAEが何をやっているのかを調べた事のある方は納得感があるかもしれません。
しかし、ちょっと待った!
Baseモデルしか使っていません。Refinerモデルが使われていません。
そう、この明快さがComfyUIの強味です。
そして、上の方の解説で使ったStable Diffusion XLの概念図を思い出してください。Baseモデルが出力した潜在(Latent)イメージをRefinerモデルに繋げれば動かせそうだってわかるじゃないですか?
それでは繋げてみましょう。
まずはRefinerモデルのLoadから。ブラウザ画面上で右クリックしてAdd Node -> loaders-> Load CheckPointを選択し、Load CheckPointノードを追加します。
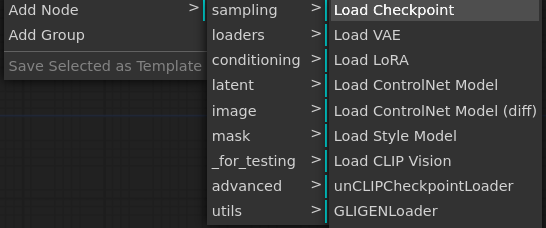
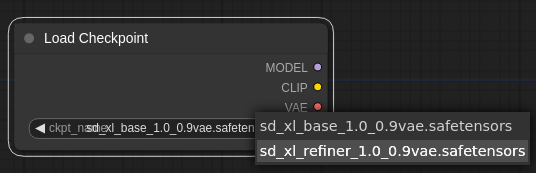
配置されたノードで「sd_xl_refiner_1.0_0.9vae.safetensors」を選択
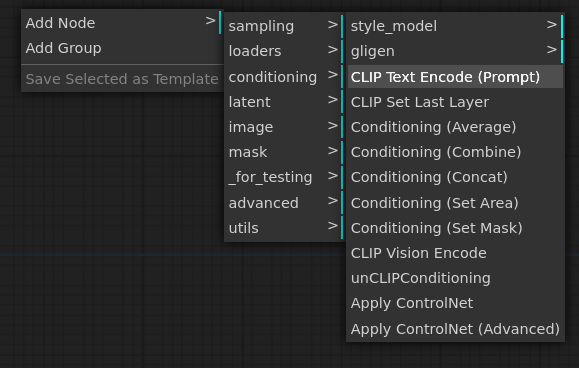
同様にAdd Node -> conditioning -> CLIP Text Encode(Prompt)を選択
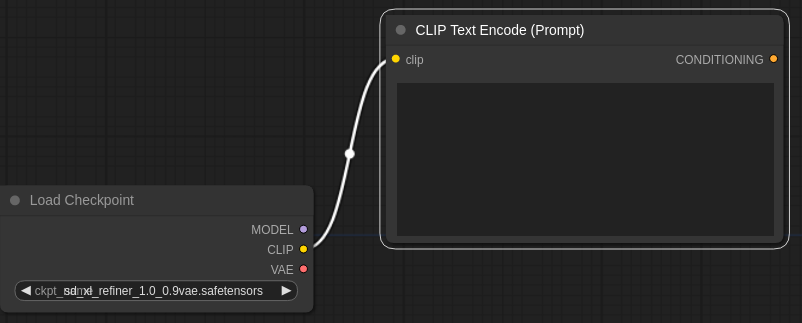
Load CheckPointノードからのCLIPの黄色〇からCLIP Text Encode(Prompt)の黄色〇までをドラッグしてつなげる
CLIP Text Encode(Prompt)はプロンプト用とネガティブプロンプト用があるので、同様に2つ用意し、Base側の文章をそのままコピーします。余談ですが、プロンプト内では、AUTOMATIC1111と同様に括弧を使った強調表記ができますが、Embedding(Textual Inversion)は書式がちょっと異なっており「embedding:<embedding_filename>」として指定します。LoRAはLoadh CheckpointとCLIP TextEncode(Prompt)の間にLoad LoRAというノードを挟んで、そちらでロードしてからプロンプト内で通常のトリガーワードを使って呼びだします。
次、Sampler。Add Node -> sampling-> KSampler
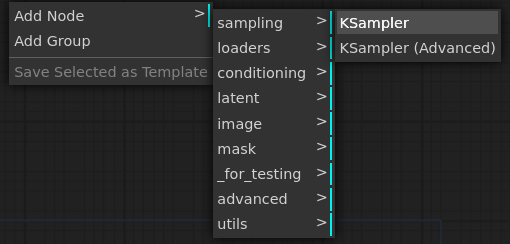
出てきたノードをBase側に習って以下のように接続します。
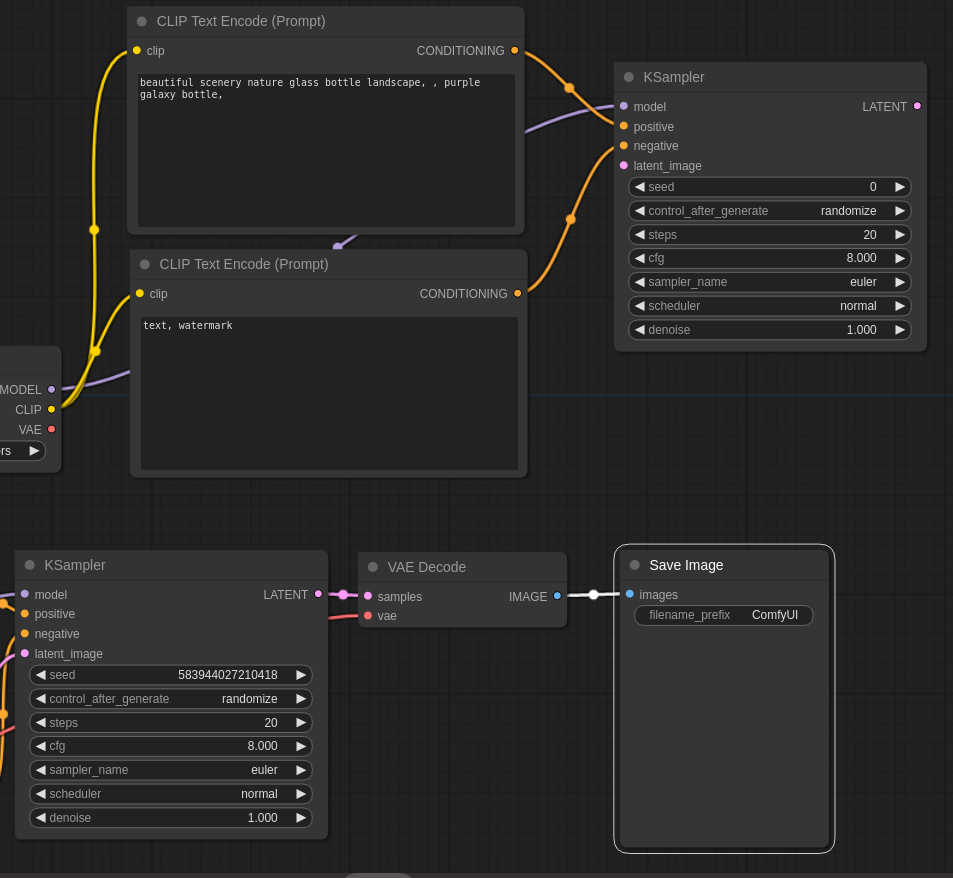
そして、以下の接続変更を実施
・BaseのLatentの出力をRefinerのKSamplerに接続し、RefinerのKSamplerからVAE Decodeに接続
・VAE DecodeのVAEにはRefinerのLoad CheckPointのVAEを繋げる
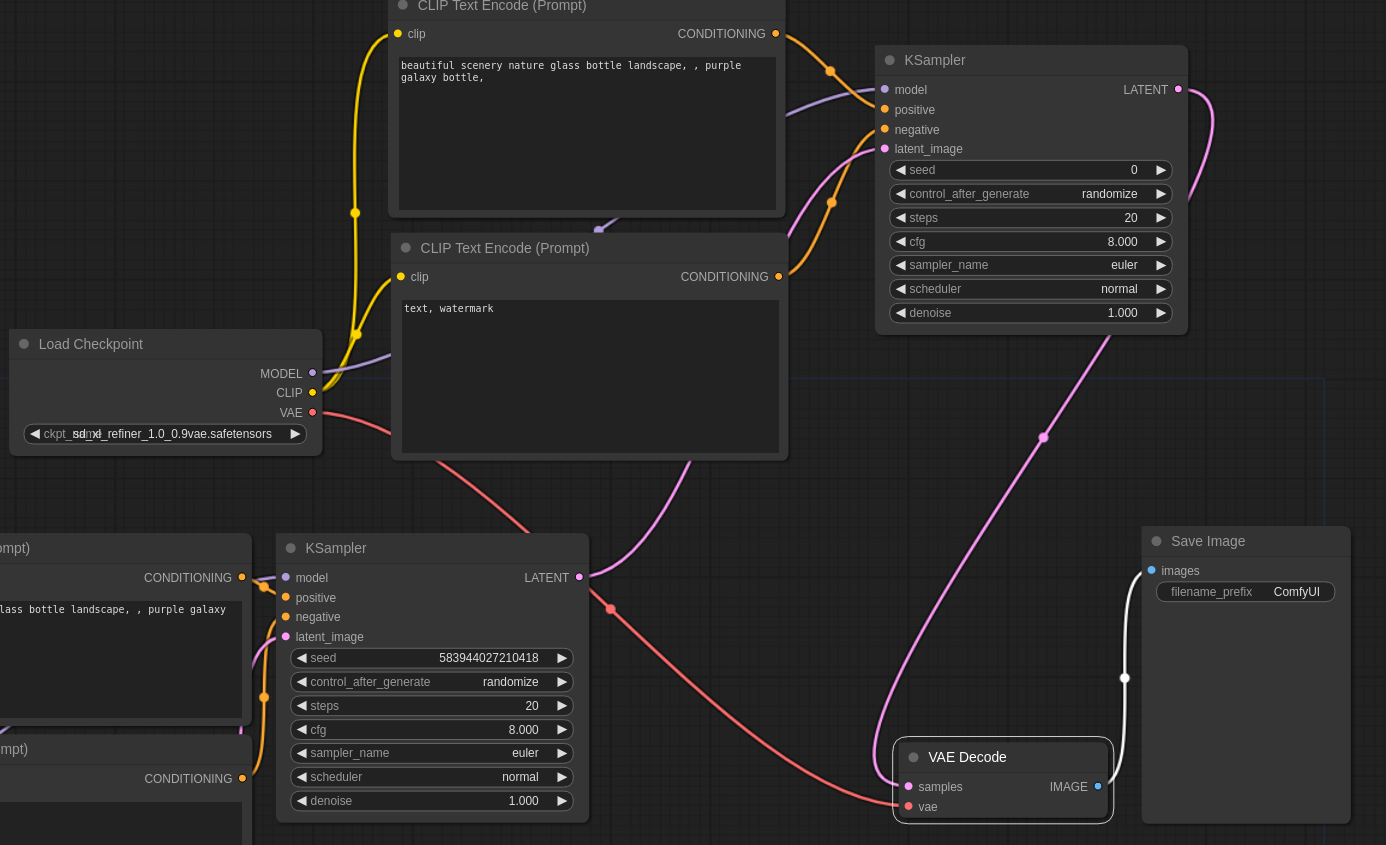
この状態にした後にメニュー上部の「Queue Prompt」を押して30秒くらい待ちましょう。Save Imageのところにボトルの画像が生成されれば成功です!
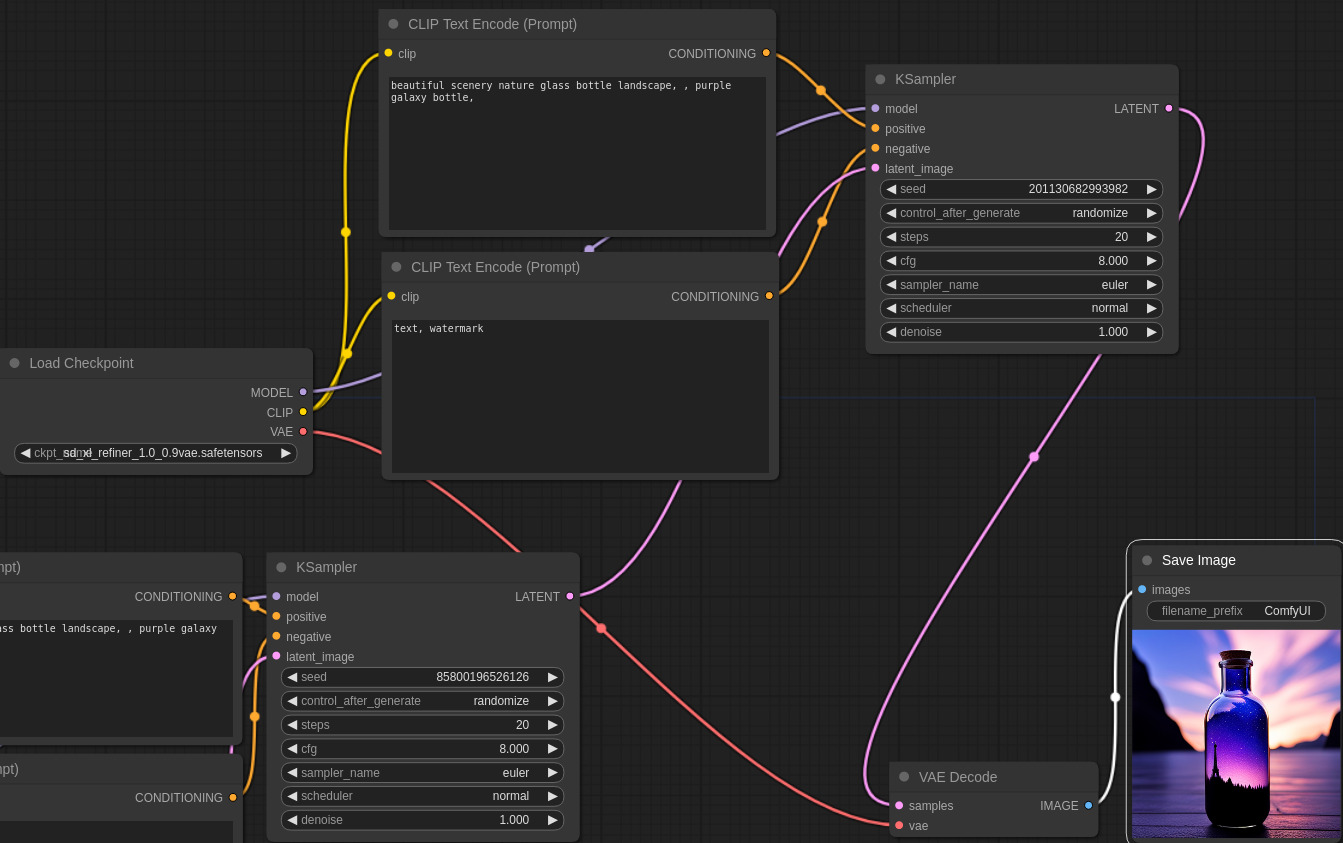
凄い!自分のやっている事が明確になって大変わかりやすい!
補足ですが、Empty Latent Imageノードでwidthとheightを1024 x 1024に修正しておくのと、
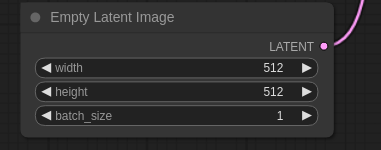
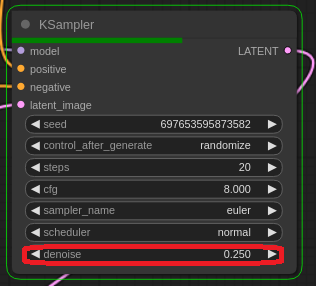
RefinerのKSamplerのdenoiseを0.25等の低い値にしておくと更に良いかもしれません。(RefinerのやっているのはImg2Imgなので、denoiseが高い値だとBaseが作った画像を作り直してしまう事に繋がる)
更には、CLIPもSDXL用のノードを使うとか、KSamplerもKSampler(Advanced)に変更して、開始ステップ数やノイズ有無をBaseとRefiner用に適宜変更する等、細かい調整をする事で品質や速度、使い勝手がどんどん向上していきます。先達が作った優れたフローを参考にしつつ、段々と理解を深めつつ、複雑なフローを使いこなせるようになると良いと思います。
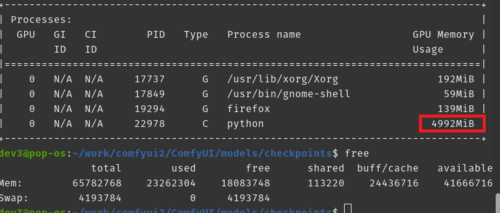
本作業中のGPUメモリの使用量はだいたい5~6Gくらいだったのでメモリ搭載量が8GのGPUでも動くと思います。なお、本体側のメモリにある程度空きがないと動作させるのが厳しいと言う話も聞いています。
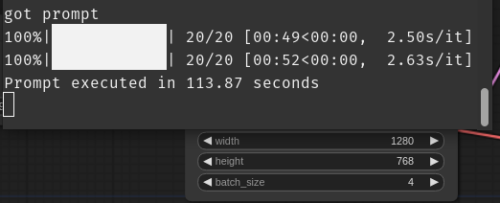
また、RTX 3060を使った際の速度実績ですが、1280 x 768の画像を4枚作るの約2分弱かかっています。これも優秀と思います。
Stable Diffusion XLに移行すべきなのか?
Stable Diffusion XLとStable Diffusion 1.5の比較
以下、素のStable Diffusion XLを使って久しぶりに「Nausicaa of the valley of the wind(風の谷のナウシカの英語版タイトル)」のプロンプトで生成してみた画像です。40枚程度作った画像の中から見栄えの良い画像を選別しています。
Stable Diffusion XLはおそらくリアル系画像の方が得意なのではないかと思うのですが、二次元系でスタジオジブリっぽい画像が出来ています。プロンプトを頑張って工夫をせずとも、この品質の画像が生成できるのはかなりの進化だな、と思います。



思ったよりかなり出来が良いのでネガティブプロンプトを少しだけ調整して追加で生成した結果が以下です。

Spirited Away(千と千尋の神隠しの英語版タイトル)

Castle in the Sky(天空の城ラピュタの英語版タイトル)

Lupin the third : The Castle of Cagliostro(ルパン三世:カリオストロの城)

How do you live?(君たちはどう生きるか?の英語版の当初仮タイトル)

The Boy and the Heron(君たちはどう生きるか?の英語版の正式タイトル。意味は「少年とアオサギ」)

afghan girl(アフガンの少女)

サバンナでアオサギとボクシングで戦うニコラス・ケイジ

イーロン・マスクとマーク・ザッカーバーグの金網デスマッチ。イーロンは火炎放射器を持ち、ザッカーバーグはVRゴーグルをしています。
おぉ、リアル系もかなりいい感じですね、中々の実力です。しかし、当たり前ですが日本でも2023年7月14日に公開されたばかりのスタジオジブリ最新作映画である「君たちはどう生きるか?」のアオサギには対応できません。
比較のため「Stable Diffusion 1.5をベースに微調整したモデル or LoRA + 拡張機能」で生成できる画像を何点か紹介しておくと以下です。




Stable Diffusion 1.5の拡張機能やLoRAを組み合わせると、モデル内に既に存在する強力な概念(ニコラス・ケイジのような欧米で有名な俳優等)だけではなく、「君たちはどう生きるか?」のアオサギのような元モデル内に存在しない概念もある程度制御出来るので自由度が高いです。
とはいえ、上記の画像群はエンジニアリング作業ともいえるようなレベルの試行錯誤をして生成する画像なので、有料の画像生成AIサービスのようにプロンプト + ボタン1つで見栄えが良い画像が作れるモデルのニーズはそれなりに高いかもしれません。
画像生成時の前処理と後処理の重要性
現時点ではまだStable Diffusion 1.5で培った既存資産を捨ててまで移行すべきか迷うところではありますが、Stable Diffusion 2.1のようにあまり使われないと言う事はなさそうとも思っています。
何故なら、有料の画像生成AIサービスがStable Diffusionより打率が高い(つまり比較的綺麗な画像が出来る割合が高い)理由は「有料の画像生成AIサービスは画像生成時に前処理や後処理をしているのではないか?」と言う説があるためです。
例えば「afghan girl(アフガンの少女)」というナショナルジオグラフィック誌に掲載された有名な写真があるのですが、某有料の画像生成AIサービスは、そのまんまの画像を出力してしまうため、元写真の撮影者からクレームを受けてafghanというキーワードに何等かの前処理をして対応したのではないかと言われています。しかし、キーワードベースの処理であるためアフガンに潜在空間的に近い単語、例えば「タリバンの少女」で生成すると似た画像が出来てしまうというブラックジョークのような話を聞いた事があります。
今回、Refinerとして後処理が出来る仕組みになったのは一歩前進で、おそらく1.5ベースのモデルより打率が上がっているのと、今後の周辺エコシステムの発展次第では、将来的にSD1.5世代では実現不可能な事がSDXL世代で出来るようになる可能性もあるのかな、と思っています。
なので、少しずつStable Diffusion XLやComfyUIにも慣れていった方が良いかもしれません。
Stable Diffusion XL用のLoRAやカスタムモデル、カスタムノードについての補足
kohya-trainer等のStable Diffusion XLでLoRAを学習させるためのColabは公開されていますが、GPUのメモリではなく本体のメモリが無料版Colabでは足りなくなるため、ハイメモリ版のランタイムを使用するために有料版のColab Pro契約が必要になるとの事です。
Colabにこだわらなければ Paperspace社のGradient(要アカウント登録)などで無料GPUでLoRAの学習が実施できるとの話も聞きましたが、未検証です。
本体メモリさえ十分であれば、GPUのメモリ12GBのRTX 3060でもLoRAを学習させる事が出来るとの話も聞きましたが、未検証です。
LoRAも設定項目が色々と増えており、肌感覚が1.5と違います。アイキャッチ画像を見てわかる通り1.5と同等な品質の画像を生成する事は私はまだ出来ていません。
Stable Diffusion XLのBaseをカスタマイズしたモデルも次々と発表されていますが、カスタマイズしているのはBaseモデルだけでRefinerは1.5ベースのモデルを使うように指示しているケースなどもあり、まだカスタムモデルの作者の方達も様々な試行錯誤をしている段階と感じています。
BaseがXLでRefinerが1.5だとLoRAもBase用とRefiner用の2つの版を別々に用意する必要があるのではないか等、未解決の疑問はまだ結構あります。
また、ComfyUIもカスタムノード(拡張ノードと表記されている場合もあります)という、AUTOMATIC1111における拡張機能のような有志が作った多機能な独自ノードやそれらを使った特定の目的に特化したワークフローが多数公開されています。
これらを使うと本記事のようにゼロから自分でノード間を繋げて組み立てていく必要はなくなるのですが、ある程度知識がないと自分好みにカスタマイズする事も難しく、いきなり複雑なフローを見ると挫折しかねないので、ざっと本ページを最後まで読んで躓きやすい部分をあらかじめ知っておくと良いと思います。
カスタムワークフローの一例としてSeargeSDXLとComfyUI-Impact-Packを末尾にリンクを張っておきます。
ComfyUIの便利な小技など
・ComfyUIの便利なショートカット
Ctrl + Mキー:対象ノードを一時的に消す(Mute)する。特殊な処理等を一時的に停止したいけどわざわざノードを切断したくない時
Ctrl + Bキー:対象ノードの処理を行わずにパス(Bypass)する。LoRA等、一時的に特定のノードの内容をオフにしたいけどわざわざノードをつなぎ直したくない時
・AUTOMATIC1111と同じPCで動かしている場合にcheckpointファイルなどモデルを共有する方法
ComfyUIフォルダ内のextra_model_paths.yaml.exampleをextra_model_paths.yamlと言う名前に変更し、ファイル内の「base_path: path/to/stable-diffusion-webui/」の部分をAUTOMATIC1111のトップフォルダへの絶対パスに変更すると読みこむ事ができます。このファイル内で設定をすればInvokeAIなどの他のUIのファイルも読みこむ事が可能です。
・huggingface diffusers形式のファイルの読み込み
Stable Diffusionのモデルはファイル形式が2種類あります。AUTOMATIC1111等が使うのは1ファイルに全てを収納している形式ですが、huggingface社のDiffusersでは複数ファイルに分割した形式を使用します。Diffusers形式のファイルはそのままではAUTOMATIC1111では使用できませんが、ComfyUIでは「Diffusers Loader」ノードを使う事で変換せずに使用する事ができます。例えばSDXL用のControlNetはDiffusers形式で発表されましたが、形式を変換せずに使用する事ができます。
・画像が生成できても実際にはコンソールにエラーが出力されている事がある
問題なく画像が生成されているようにみえてもコンソールにエラーがでているケースがありますので要確認です。
例えば、
waifu-diffusion-xl(Stable Diffusion XL 0.9 Baseのカスタムモデル) + Stable Diffusion XL 1.0 Baseで作成したLoRA
↓
Stable Diffusion XL 1.0 Refiner + Stable Diffusion XL 1.0 Baseで作成したLoRA
のフローでは画像は生成されますがエラーが出ます。Refiner側のLoRAを削除するとエラーは出なくなりますが、まだ原因はわかりません。
・ComfyUIをVersion UPする際はgit pullで更新する
AUTOMATIC1111と同様ですが、git cloneしたディレクトリでgit pullすれば最新のComfyUIにVersion UPできます。前述のショートカットは古い版のComfyUIでは実装されていないのでドキュメントと異なる部分があったらgit pullしましょう。
・primitive nodeの使い方
他の人のワークフローを見ていると良く出てくるprimitiveノードですが、先に繋げます。繋げる事で入力エリアが表示されるようになったり見た目も変化するのでまずは繋げてみましょう。
・参考にしているワークフローで使っているノードが見つからない時
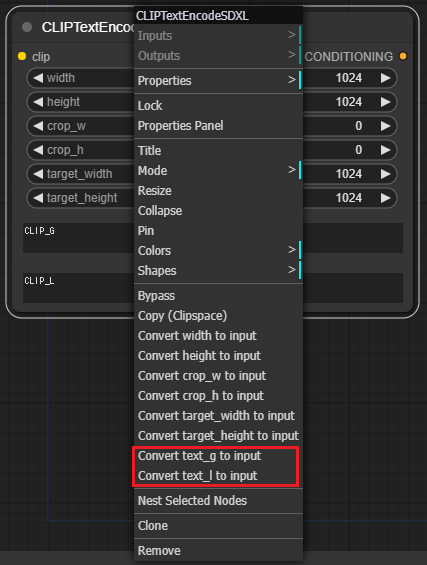
他の人のワークフローを見ていると同じ形状のノードが見つからない時があります。形状や入力や出力の数が違う場合、以下の図のようにノードを右クリックして出るメニューでINの数や形状を変更できる事を知っておきましょう。それでも見つからない場合、後述のカスタムノードをインストールしている可能性があるのでノード名 + github等でgoogle検索して探してみましょう。
例:CLIPTextEncodeSDXLのディフォルトの形
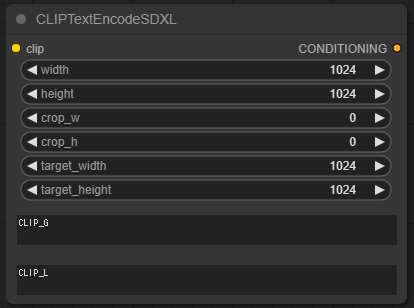
右クリックで「ノードの入力エリアを外部入力に変更」する事が出来ます。逆に「外部入力をノード内の入力エリアに変更」する事もできます。
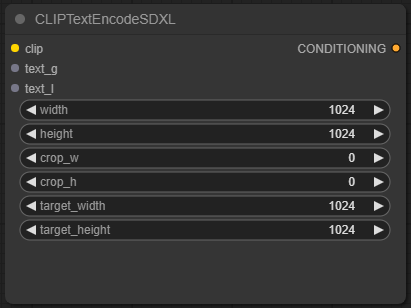
変更後のCLIPTextEncodeSDXL
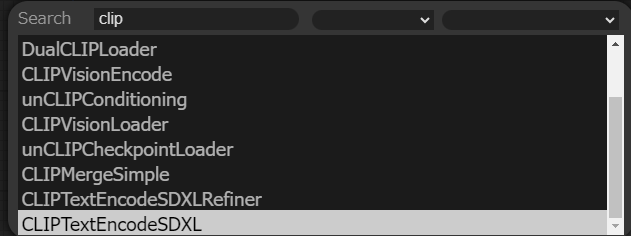
・ノードを配置する際のショートカット
何も配置されていない所をダブルクリックするとノード検索用の窓が出てくるのでそこで直接検索して目当てのノードを探しましょう。右クリックして表示されるメニューから探すのはインストールしたカスタムノードが増えてくると目当てのノードを見つける事が難しくなるので慣れてくるとこちらがメインになると思います。
・ComfyUIのカスタムノードのインストール方法
ComfyUIは先達が作った優れたワークフローが沢山ありますが、それらのワークフローがカスタムノードを使っている場合は同じカスタムノードをインストールしないと実行できないのでカスタムノードのインストール方法を知っておく必要があります。
対象のカスタムノードプロジェクトのgithubページのURLをコピーし、
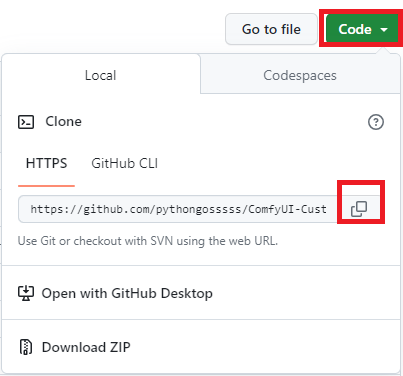
ComfyUI/custom_nodes配下でコマンドライン/ターミナルを起動し、
git clone コピーしたURL
を実施します。Windows用の7-Zip形式で固めたファイルを使用している場合にはGit for Windows ( https://git-scm.com/download/win )をインストールして上記と同じコマンドを実施する必要があります。
幾つか有名どころの拡張機能/カスタムノードをご紹介しておくと以下があります。
(1)ComfyUI-Manager ( https://github.com/ltdrdata/ComfyUI-Manager )
モデルやカスタムノードの追加など様々な管理がComfyUIのメニューから出来るようになります。しかし、全てのカスタムノードを網羅しているわけではないので場合によっては前述のgit cloneで手動インストールする必要があります。
(2)ComfyUI_NestedNodeBuilder ( https://github.com/ssitu/ComfyUI_NestedNodeBuilder )
複数のノードを1つにまとめてフロー図をわかりやすく綺麗にする事が出来ます。
Shiftキー+左クリックで複数ノードを選択した後、右クリックで出てくるメニューでNest Selected Nodesを選択し、名前を付ける事で新ノードを作成できます。
一度作成した新ノードは以降、右クリックメニューのAdd Node→Nested Nodesで追加する事もできます。
新ノードの情報は ComfyUI/custom_nodes/ComfyUI_NestedNodeBuilder/nested_nodes/ 配下に保存されています。
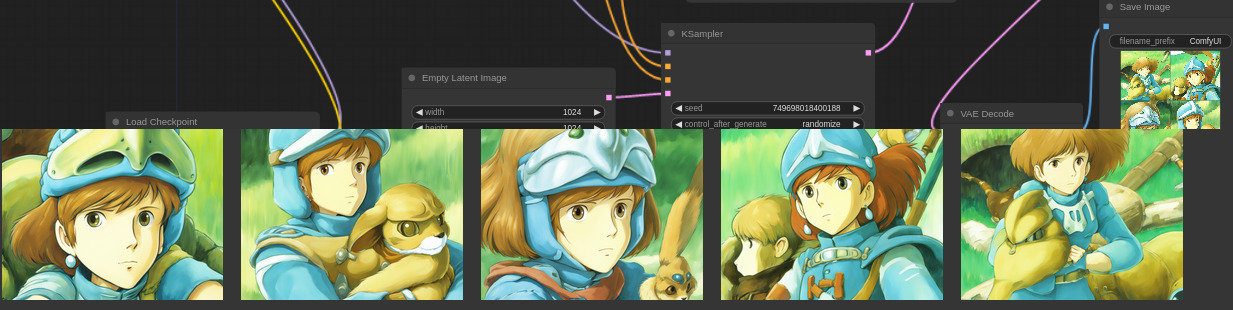
(3)ComfyUI-Custom-Scripts ( https://github.com/pythongosssss/ComfyUI-Custom-Scripts )
メニューやフローが色々と使いやすくなったり見やすくなります。例えば、生成した画像が以下のように画面下部にはっきりと表示されるのでわかりやすくなります。
(4)sdxl_prompt_styler ( https://github.com/twri/sdxl_prompt_styler )
このカスタムノードがあればsdxl用のプロンプトにあまり悩まないで大丈夫です。
自分が描きたい主題だけをプロンプトで与えると、アニメ風、サイバーパンク風、リアル風等、など事前定義されている様々なスタイルを簡単に適用し、綺麗な画像を出力する事ができます。
以下は全てプロンプト「The Boy and the Heron」のみを与えてsdxl_prompt_stylerを使ってstyleを切り替えた結果です。
BASEスタイル

sai-fantasy art

sai-anime

game-retro game

futuristic-cyberpunk cityscape

artstyle-hyperrealism

以下、sdxl_prompt_stylerを使ったシンプルなフローの例です。github公式サイトのサンプルがちょっと古いのか、そのまま真似た接続が出来ないので、接続するためには前述の通り右クリックで出るメニューでCLIPTextEncodeSDXLの形状を変更する必要があります。
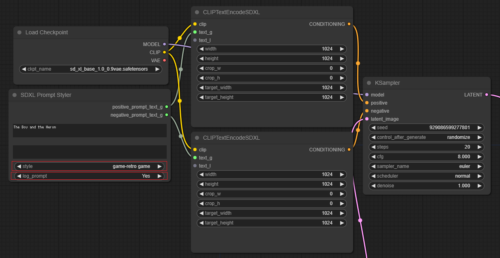
やっている事は、与えたプロンプトの前後にstyleで選択したスタイルに合わせて特定のプロンプトを挿入しているだけです。log_promptをyesにすると実際にモデルに与えているプロンプトがコンソール/コマンドプロンプトに出力されるのでSDXL用のプロンプトを知りたい場合に参考にもなります。
なお、各スタイルのサンプルや詳細を知りたい方は「Fooocus-MRE:自分の描いた絵をAIに格好良くしてもらう」でSDXL用のプロンプトを大量に説明してあるので参考にしてください。
3.Stable Diffusionの新VersionであるStable Diffusion XL(SDXL)をComfyUIで動かす方法関連リンク
1)arxiv.org
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis ( SDXLの論文 )
2)huggingface.co
stabilityai / stable-diffusion-xl-base-1.0
stabilityai / stable-diffusion-xl-refiner-1.0
hakurei / waifu-diffusion-xl
3)github.com
comfyanonymous / ComfyUI
comfyanonymous / ComfyUI_examples
ComfyUI/notebooks/comfyui_colab.ipynb (ComfyUI動作用無料版Colab)
Linaqruf / kohya-trainer (LoRA学習用 Colab)
TheLastBen / fast-stable-diffusion (LoRA学習用 RunPod、Paperspace)
SeargeDP / SeargeSDXL (ComfyUIのSDXL用カスタムノードとカスタムワークフロー )
ltdrdata / ComfyUI-Impact-Pack (ComfyUIのSDXL用カスタムノードとカスタムワークフロー )
wyrde / wyrde-comfyui-workflows (ComfyUI用の様々な参考になるワークフロー)
cubiq / ComfyUI_Workflows (ComfyUI用のワークフローを段階的に理解する)
4)comfy.icu
Comfy.ICU(ComfyUI用のワークフロー共有サーバー)
5)comfyui.creamlab.net
ComfyUI 解説 (wiki ではない) 日本語でcomfyUIのノードの解説などをしてくれているサイト

