
1.何故、GPT-4はMITの学位を取れなかったのか?
・GPT-4にマサチューセッツ工科大学(MIT)の試験問題を解いて貰ったところ正答率100%を達成したというニュースが話題になった
・しかし、第三者が検証したところ、データセットにも回答の検証方法にも問題があり真の正答率は58%程度と思われるとの事であった
・言語モデルを使用して言語モデルの精度を評価する手法には落とし穴があるのと結論を急ぎすぎてしまったように見える
2.GPT-4がMITのテスト試験で100点を取ったと言う話の詳細
2週間くらい前にGPT-4がマサチューセッツ工科大学(MIT:Massachusetts Institute of Technology)の試験問題で正答率100%を達成したというツイートが話題になりました。
日本でも漫画や小説の登場人物がMIT卒業生である設定にして優秀さを印象付ける事がありますが、MITはアメリカの超難関大学です。
検証には数学、電気工学、コンピュータサイエンスの全コースにわたる問題、中間試験、期末試験から4,550問の問題および解答の包括的なデータセットを使ったと言う事です。これらの試験は学位認定に使われるため、過去問は一般公開されていません。
論文の概要では「GPT-3.5はMITの全カリキュラムの3分の1を解くことに成功し、GPT-4は画像に基づく問題を除いたテストセットで完璧な解答率を達成した」とされていました。
AIは既に医師免許に関する試験では専門家と同レベルの回答をする事が出来るようになっていますが、試験問題が非公開と言う事はGPT-4がどこかで回答を読んで記憶していたと言うわけではないように読め、且つその状態で難関大学として知られるMITで正答率100%は驚くべき偉業です。
しかし、第三者が検証したところ、残念ながら
・そもそも正答が不可能な問題が含まれているケースがあった(回答に必要な情報が問題文内にない)
・プロンプト内で問題と正解のセットが参照できてしまっているケースがあった(少数ショットとして渡した情報に問題があった)
・GPT-4が出力した結果をGPT-4を使って検証を行っていた(GPT-4が完全に幻覚をみてしまうケースでは結果が信頼できない)
などなどで、だいぶ印象が異なります。
付加情報なし(ゼロショット)で、再検証したところ、厳密にはGPT-4であっても58%程度の正答率と思われるとの事でした。
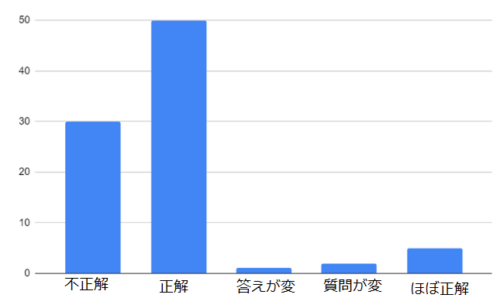
しかし、検証用のデータセットも公開していたという事は騙そうという意図はなかったのだろうと思い、何故、こういった事が起こったのか不思議に思いました。以下、MITの学生さん(Raunak Chowdhuriさん, Neil Deshmukhさん、David Koplowさん)が本件について詳細にまとめてくれたページを参考にしています。
1.データセットの問題
テストセットの最大4%が必要な情報が問題文の中に全て示されておらずそもそも回答不能でした。
例1.以下に、上記Dの様々なゲートの遅延を示します。 Dから回路の伝播遅延を計算してください。
(ゲートの遅延に関する情報が提供されていない)
例2.この問題は問題2のバリエーションです。もう一度、半径 3 メートルの円盤があると仮定し、…
(問題2に関する情報が提供されていない)
例3.端末で以下のコマンドを叩き、その出力のおかしい点を見つけ、該当する出力をコピペしてください。
(MIT内の端末にアクセスできる事が前提)
例4.…この問題では、テイラー級数を使用して近似します。
(そもそも問題文になっていない)
2.プロンプトの問題
プロンプト内で渡した少数事例が不適切でした。
GPT-4に情報を処理して貰う際には「例えばAの場合はaとして答えてください。Bの場合はbとして答えてください。それではCは?」のように、回答の際に参照すべき事例をプロンプト内に書いて渡すケースがあります。
これは、感情分類する際などにも使われる手法ではありますが、今回は問題と正解の組が一語一句が同じ形式で事例に中に含まれてしまっている例が7%も含まれており、その他にも事例が実際の問題に似すぎていて且つ答えが同じケースがある事が判明しています。
3.検証手法の問題
ゼロショット(つまり事例をプロンプト内で与えない)で正答できない場合に少数ショット(つまり事例を与える)を実行したようなのですが、その際、以下のような再帰的なプロンプトが使われていたようです。
・前の回答を確認し、回答の問題点を見つけてください
・見つかった問題に基づいて、回答を改善してください
・間違った回答についてフィードバックしてください
・このフィードバックを元にもう一度答えてください
この手順を繰り返すのであれば、選択式問題では最終的に必ず正答にたどり着く事は容易に想像できます。そして全体の16%が選択式問題であったようです。
「解答用紙を持った人が、正解するまで生徒に答えが正しいかどうかを伝えるのと似ています」との表現が検証ページ内にありましたが、まさにそうですね。
更に選択式問題でない場合であっても自己採点なのであれば「採点者が回答者と同じ誤解をしており正答とした」、つまり自画自賛採点をしている可能性も否定できません。
上記のようにわかりやすくまとめてあればおかしい事にすぐ気づけると思うのですが、プロンプトを繋げて(prompt cascade)gpt-4自身に自身の回答を見直しさせる手法では、同様にプロンプト内でヒントを与えてしまっている事に気づけない危険性はありそうです。
4.コード内のバグなど
エキスパート プロンプティング(expert prompting)というgpt-4に特定分野の専門家になりきって回答させて問題文内の文脈を把握する能力を向上させる手法を採用していたのですが、コード内に不具合があったとの事。
あなたは「Donald Knuth(訳注:Webを発明した人としても知られる超著名なコンピューターサイエンスおよび数学者)」です。
以下の質問に答えてください。
「質問」
を意図していたのが、
あなたは「質問」です
以下の質問に答えてください。
「Donald Knuth」
になってしまっているケースがあったとの事。
結論
・GPT-4 のような言語モデルを使用してモデルの精度を評価する手法には落とし穴がある事
・AI関連の研究/ビジネスにおいて拡散優先の風潮が強まってきており結論を急ぎすぎたように見える事
昨今は製品が完成する前から宣伝だけしてwaitlistで反響を確かめるマーケティングが当然のように行われていますが、同様に査読前論文をArxivにアップロードしてTwitterで広く共有して注目を集めようとする風潮がある事が元記事内でも指摘されています。
どんな素晴らしい研究成果/製品であっても注目を集めなければ埋もれてしまうという焦りから勇み足になってしまう気持ちはわかります。そして、研究結果を再現できる程の細かい内容を記載していない論文を見かける事もあるので、他の人が検証できるようにソース/データを公開したと言う点では少なくとも誠実であったのかなと思います。
検証後の結果であっても「0歳児なのに、試験用に改めて学習せずとも、初見でMITの単位認定に使われる試験で58%の正答率を叩き出した」わけなのですから十分漫画の世界に思えます。
ただし、MITの関係者が本件に関して公式声明を出していましたが、データセットである過去問は元作者の同意を得ずに収集されていました。元の著作権者を軽視する風潮は、許可を得ずに収集したデータセットを「公的データセット」と見なして使用する事が多い現状の延長線上にあるようにも思えます。
自分自身の研究結果や著作物が同様に「公的データセット」として扱われる覚悟を持っている人は多くはないと思うので、AIの負の影響がもっと社会的に認識されるようになるにつれて同様な問題提起は他でも出てくるのではないかと感じます。
なお、MIT公式声明文は最後を以下で締めくくっています。
「いいえ、GPT-4はMITの学位を取得する事ができませんでした」
3.何故、GPT-4はMITの学位を取れなかったのか?関連リンク
1)arxiv.org
Exploring the MIT Mathematics and EECS Curriculum Using Large Language Models (元論文)
2)flower-nutria-41d.notion.site
No, GPT4 can’t ace MIT (検証結果)
3)people.csail.mit.edu
On the paper “Exploring the MIT Mathematics and EECS Curriculum Using Large Language Models”(PDF) (公式声明)

