
1.GAN LAB:あなたのブラウザでGANで遊んでみましょう!(2/2)まとめ
・ブラウザ上でGANの概念を直観的に理解するGAN LABの具体的な操作についての説明
・ジェネレータとディスクリミネータを互いに競わせてフェイクサンプルを本当にサンプルに近づける
・自作のデータを使ったりステップ実行をしたり様々な機能を持ちより平易にGANを理解できる
2.GAN LABの使い方
以下、PAIRのpoloclub.github.ioより、「Play with Generative Adversarial Networks (GANs) in your browser!」の意訳2/2、後半の具体的な使い方の説明です。
あらかじめ用意されているデータの中から選択
まず初めに、GANに学習させるデータ(確率分布)を選択することができます。選択すると、2つの場所に図が表示されます。左側の小さい図はモデル全体の概要を表示します。右側にはモデルを構築する個々のコンポーネントの状態をより大きく表示できます。
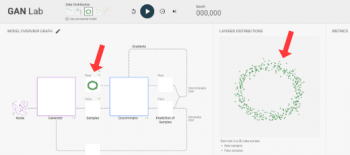
選択されたデータセットは二か所に表示されます。
私達は、現実的なサンプルを生成するGANの仕組みを理解するために役立つように表示部分を2つにわけました。
左:モデル概要グラフ
GANのアーキテクチャ、その主要コンポーネントとその接続方法、およびコンポーネントによって生成された結果の可視化が表示されます。
右:レイヤードディストリビューショングラフ
レイヤードディストリビューショングラフでは、モデル概要グラフ上のチェックボックスを用いて、個々のコンポーネントの視覚化の詳細を表示/非表示にできます。これにより、モデルの解析時に各コンポーネント出力をより容易に比較できます。
トレーニングの開始
GANモデルのトレーニングを開始するには、ツールバーの再生ボタンをクリックします。選択したデータの実際のサンプルに加えて、モデルによって生成された偽のサンプルが表示されます。
訓練の進行に伴って偽のサンプルの位置が絶えず更新されます。完璧なGANは、その分布が本物のサンプルの区別できない程似ている偽のサンプルを生成するようになるでしょう。それが起こると、レイヤードディストリビューションビューには、2つのデータほぼ重なって見えるようになります。
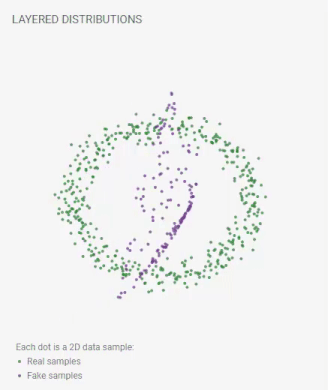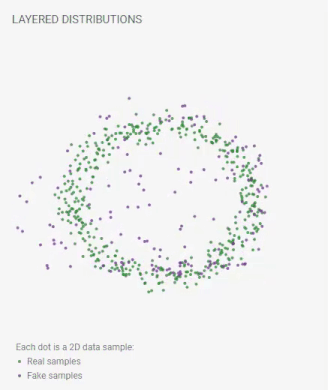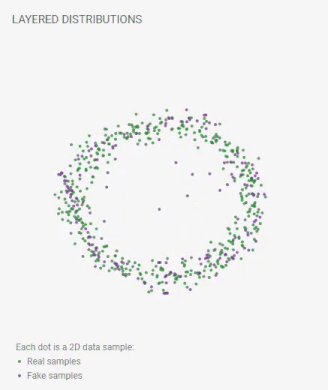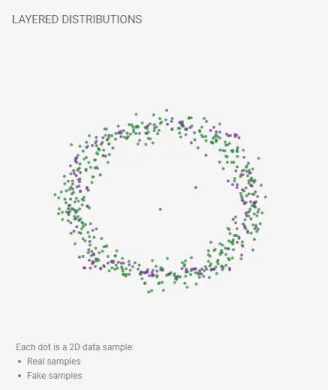
フェイクサンプルの位置はトレーニングを通じて継続的に更新されます。最終的に、本物のデータセットの分布とフェイクサンプルの分布は重なります。
ジェネレータとディスクリミネータの可視化
GAN内のジェネレータとディスクリミネータは、お互いに競争しながら、偽のサンプルを繰り返し更新して実際のものに近づけていくことを思い出してください。 GAN Labは、それらの間の相互作用を視覚化します。
Generator
前述のように、Generatorは、ランダム入力を人為的な出力に変換する関数です。GAN Labでは、ランダム入力はxとyの値を持つ二次元のデータであり、出力も二次元ですが別の位置にマッピングされます。この出力が偽のサンプルです。この配置を視覚化する1つの方法は、多様体(manifold)を使用することです。
入力空間は、均一な正方形のグリッドとして表されます。関数が入力データの位置を新しい位置に配置するので、出力を視覚化すると、グリッド全体が不規則な四角形からなる元の正規のグリッドの変形版のように見えます。変形により各セル(格子)の面積(または密度)が変更され、密度は不透明度として表現されるので、不透明度が高い箇所は、より小さい空間により多くのサンプルが配置されている事を意味します。
非常にきめ細かくした多様体は、擬似サンプルの視覚化とほぼ同じように見えます。この視覚化は、Generatorが出力を実際のサンプルの分布に似せるようにマッピング関数を学習する方法を示します。
![]()
Generatorのデータ変換は多様体として視覚化されます。左端の入力ノイズを右端の擬似サンプルに変更している事が視覚化されています。
Discriminator
Generatorが偽のサンプルを生成すると、Discriminator(バイナリ分類器)は、本当のサンプルと識別しようとします。
GAN Labは決定境界を2Dヒートマップとして視覚化します(TensorFlowのプレイグラウンドに似ています)
グリッドセルの背景色は、分類器の結果の信頼性を符号化しています。暗い緑色は、そのセルのサンプルが実際のものである可能性が高いことを意味します。より暗い紫は、より偽物である可能性が高い事を意味しています。GANが最適に近づくと、全体のヒートマップが全体的にグレーになり、Discriminatorが偽の例を実際の例と容易に区別できなくなっていることを示します。
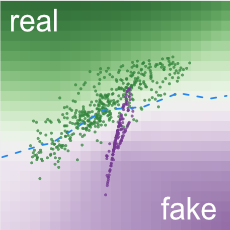
Discriminatorのパフォーマンスは、2Dヒートマップによって解釈できます。ここでは、ほとんどの実際のサンプルが緑色の領域(および紫色の領域に偽のサンプル)があるので、Discriminatorはうまく機能しています。
ジェネレータとディスクリミネータの相互作用を理解する
GANでは、2つのネットワークが繰り返し更新され、相互に影響し合います。 GANラボの重要な用途は、視覚化を使用してジェネレータが段階的に更新され、より本物に近いフェイクサンプルを生成する方法を学ぶことです。
ジェネレータは、ディスクリミネータをだまそうとします。ディスクリミネータがフェイクサンプルを実際のものと間違うと、ジェネレータの損失値は減少します(ディスクリミネータにとっては悪い事ですが、ジェネレータにとっては良い事です)。 GAN Labは、偽サンプルの勾配(ピンクライン)を可視化し、ジェネレータがだます事に成功した例を視覚化します。
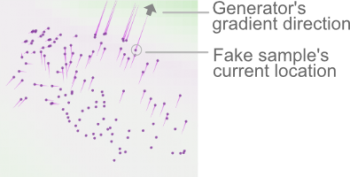
フェイクサンプルの移動方向は、ジェネレータの勾配(ピンクの線)によって示されます。それは、サンプルの現在の位置と、ディスクリミネータの現在の分類により決まります。(背景色により視覚化されています)
このようにして、ジェネレータは徐々に改善され、さらに本物に似たフェイクサンプルが生成されます。フェイクサンプルが更新されると、ディスクリミネータはそれに応じて更新され、その決定境界を精緻化し、次にフェイクサンプルのバッチを待ちます。この反復更新プロセスは、弁ディスクリミネータが実際のサンプルと偽のサンプルを区別することができなくなるまで続きます。
インタラクティブな機能で遊ぶ
GAN Labには、インタラクティブな実験をサポートする多くのクールな機能があります。
・ハイパーパラメータをインタラクティブに変更する
個別のハイパーパラメータを表示/変更するには、編集アイコンをクリックしてください。トレーニング中でも即座に反映できます。
・ユーザ定義のデータの使用
最初から存在するデータセットが気に入らない場合は、データディストリビューションリストの最後にあるアイコンをクリックして独自のデータセットを作成できます。
・スローモーションモード
アニメーションの速度が速すぎますか?スローモーションアイコンをクリックしてslowモードに入ると、スローモーション表示する事ができます。
・手動による段階的実行
より詳細な制御が必要な場合は、アイコンをクリックして個々の反復作業の量を手動で調整することができます。
GAN Labの機能を簡単に知るには、以下のビデオもご覧ください。
1)GAN Labの紹介 (0:00-0:38)
2)ハイパーパラメータ調整による簡単な学習 (0:38-1:05)
3)ユーザー定義データのトレーニング (1:05-1:51)
4)スローモーションモード (1:51-2:19)
5)手動によるステップbyステップな実行(2:19-3:10)
どのように実装されていますか?
GAN Labは、ブラウザ上で実行できるGPUアクセラレートも可能なディープラーニングライブラリであるTensorFlow.jsを使用しています。モデルのトレーニングからビジュアライゼーションまで、すべてJavaScriptで実装されています。
ChromeのようなWebブラウザがあれば、それだけでGAN Labを実行できます。私たちの実装アプローチは、ディープラーニング理解のためのインタラクティブなツールへの人々が容易にアクセスしやすくします。ソースコードはGitHubで入手できます。
誰がGAN Labを作ったのですか?
GAN Labは、ジョージア工科大学及びGoogle Brain / PAIRとの研究協力の成果です。Minsuk Kahng、Nikhil Thorat、Polo Chau、FernandaViégas、Martin Wattenbergによって作成されました。また、Shan CarterとDaniel Smilkov、Google Big Pictureチーム、Google People + AI Research(PAIR)、Georgia Tech Visualization Labに感謝します。
3.GAN LAB:あなたのブラウザでGANで遊んでみましょう!(2/2)関連リンク
1)poloclub.github.io
Play with Generative Adversarial Networks (GANs) in your browser!
2)minsuk.com
GAN Lab: Understanding Complex Deep Generative Models using Interactive Visual Experimentation
