
1.Vid2Seq:ビデオ内の各イベントを記述可能な事前学習済み視覚言語モデル(2/2)まとめ
・Vid2Seqアーキテクチャにはビデオフレーム用のエンコーダー音声入力用のエンコーダーが含まれる
・Vid2Seqモデル幅広い領域をカバーする1800万本のナレーション付き動画で事前学習を行っている
・Vid2Seqは3つの高密度ビデオと2つのビデオキャプションベンチマークで最先端のスコアを達成
2.Vid2Seqの性能
以下、ai.googleblog.comより「Vid2Seq: a pretrained visual language model for describing multi-event videos」の意訳です。元記事は2023年3月17日、Antoine YangさんとArsha Nagraniさんによる投稿です。
アイキャッチ画像はビデオ編集のイメージをchatGPT先生に伝えて作って貰ったプロンプトを私が修正してカスタムStable Diffusion先生に作って貰ったイラスト
Vid2Seqアーキテクチャには、ビデオフレームと音声入力をそれぞれエンコードするビジュアルエンコーダーとテキストエンコーダーが含まれています。
エンコード結果はテキストデコーダに転送され、デコーダは出力される密なイベントキャプションのシーケンスとビデオ内の時間的な位置関係を自己回帰的に予測します。このアーキテクチャは、強力な視覚モデルのバックボーンと強力な言語モデルで初期化されています。

Vid2Seqモデルの概要
密なイベントキャプションをsequence-to-sequenceへの問題として定式化し、特別な時間トークンを使用します。これにより、モデルがテキストの意味情報とビデオ内の各テキスト文の根拠となる時間的局在情報の両方を含むトークンのシーケンスをシームレスに理解し、生成することができるようにします。
トリミングされていないナレーション付きビデオに対する大規模な事前学習
このタスクは密度が高いビデオを扱うため、このタスク用の注釈を手動で収集することは特にコストがかかります。そこで、Vid2Seqモデルの事前学習には、大規模で容易に入手できるラベルのないナレーション付き動画を使用します。特に、YT-Temporal-1Bデータセットを使用します。このデータセットには、幅広い領域をカバーする1800万本のナレーション付き動画が含まれています。
Vid2Seqは、ナレーションを書き起こした文章とそれに対応するタイムスタンプを教師として使用し、単一のトークンの並びとして使用します。
私たちはVid2Seqを生成目的で事前学習させました。つまり、視覚入力のみを与えて音声を書き起こした文の並びを予測するようにデコーダーを学習させています。また、ノイズの多い書き起こし音声と視覚入力からマスクされたトークンを予測するようモデルに要求することで、マルチモーダル学習を促すノイズ除去目的も設定しました。
特に、トークンのスパンをランダムにマスクすることによって、音声シーケンスにノイズが加えられます。

Vid2Seqは、ラベルのないナレーション付きビデオで、生成目的(上)とノイズ除去目的(下)で事前にトレーニングされています。
高密度ビデオキャプションのベンチマークでの結果
その結果、訓練済みのVid2Seqモデルは、教師強制(teacher forcing)を用いた単純な最尤目標で下流タスクの微調整を行うことができます。(つまり、直前の検証済みトークンがあれば次のトークンを予測することができます)。
微調整後、Vid2Seqは、3つの標準的な高密度ビデオキャプションベンチマーク(ActivityNet Captions、YouCook2、ViTT)と2つのビデオクリップのキャプションベンチマーク(MSR-VTT、MSVD)において最先端のスコアを著しく向上させることができます。
本論文では、追加のアブレーション研究、定性的な結果、および少数回ショット設定とビデオパラグラフキャプションタスクでの結果を提供します。
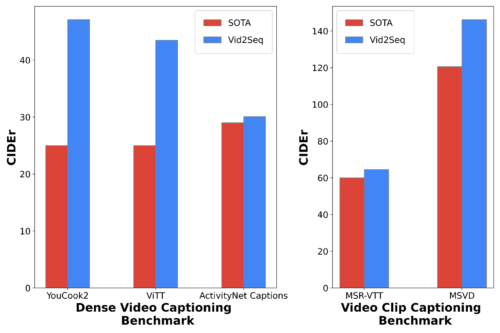
密なビデオキャプション(左)とビデオクリップのキャプション(右)に対する、CIDEr指標(高いほど良い値です)での最先端手法との比較
結論
Vid2Seqは、すべてのイベント境界とキャプションを単一のトークンの並びとして予測する、高密度ビデオキャプションのための新しい視覚言語モデルであることを紹介しました。Vid2Seqは、ラベルのないナレーション付きビデオで効果的に事前学習することができ、下流の様々な密なビデオキャプションのベンチマークで最先端の結果を達成します。
論文の詳細とコードの入手はgithubからどうぞ。
謝辞
この研究は、Antoine Yang、Arsha Nagrani、Paul Hongsuck Seo、Antoine Miech、Jordi Pont-Tuset、Ivan Laptev、Josef Sivic、Cordelia Schmidによって実施されました。
3.Vid2Seq:ビデオ内の各イベントを記述可能な事前学習済み視覚言語モデル(2/2)関連リンク
1)ai.googleblog.com
Vid2Seq: a pretrained visual language model for describing multi-event videos
2)arxiv.org
Vid2Seq: Large-Scale Pretraining of a Visual Language Model for Dense Video Captioning
3)github.com
scenic/scenic/projects/vid2seq/

