
1.USM:100以上の言語に対応した最先端の音声AI(2/2)まとめ
・事前学習で得た知識によりUSMは下流タスクからのわずかな量の教師ありデータで良好な品質を達成することができる
・YouTubeデータを使った検証では73言語の平均で30%以下の単語誤り率を達成し、最先端モデルより高い性能だった
・自動音声認識、自動音声翻訳においてUSMはすべての切り口でWhisper(large-v2)を上回る性能であった
2.USMの性能
以下、ai.googleblog.comより「Universal Speech Model (USM): State-of-the-art speech AI for 100+ languages」の意訳です。元記事は2023年3月6日、Yu ZhangさんとJames Qinさんによる投稿です。
アイキャッチ画像カスタムStable Diffusionによる生成
第1ステップでは、多言語タスクで既に最先端の結果を示し、非常に大量の教師なし音声データを使用する際に効率的であることが証明されているBEST-RQを使用します。
第2ステップ(オプション)では、追加のテキストデータからの知識を取り入れるために、多目的教師あり事前学習(multi-objective supervised pre-training)を使用しました。このモデルでは、テキストを入力とするエンコーダモジュールと、音声エンコーダとテキストエンコーダの出力を結合するための追加レイヤーを導入し、ラベルなし音声、ラベル付き音声、テキストデータでモデルを共同で学習させます。
最終ステップで、USMは下流のタスクについて微調整されます。トレーニングパイプラインの全体像を以下に示します。事前学習で得た知識により、USMは、下流タスクからのわずかな量の教師ありデータで良好な品質を達成することができます。
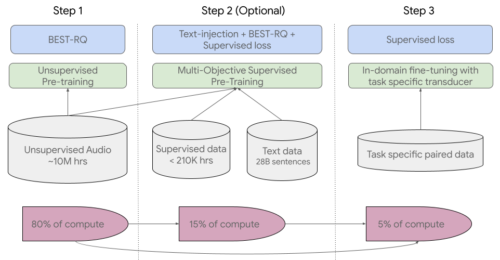
USMの全体的なトレーニングパイプライン
主な成果
YouTube Captionsの多言語対応パフォーマンス
私たちのエンコーダーは、事前学習により300以上の言語を取り込んでいます。YouTube Captionの多言語音声データで微調整を行い、事前学習されたエンコーダーの有効性を実証しています。
YouTubeのデータには73の言語が含まれており、1言語あたり平均3,000時間未満のデータしかありません。限られた教師付きデータにもかかわらず、73言語の平均で30%以下の単語誤り率(WER:Word Error Rate)を達成しました。en-USの場合、USMは現在の内製最新モデルと比較して、相対的に6%低いWERを達成しています。
最後に、最近リリースされた大規模モデルWhisper(large-v2)と比較します。このモデルは、400k時間以上のラベル付きデータで学習されました。この比較では、Whisperが40%以下のWERでデコードに成功した18言語のみを使用します。私たちのモデルは、これらの18の言語において、Whisperと比較して平均で32.7%相対的に低いWERを示しました。
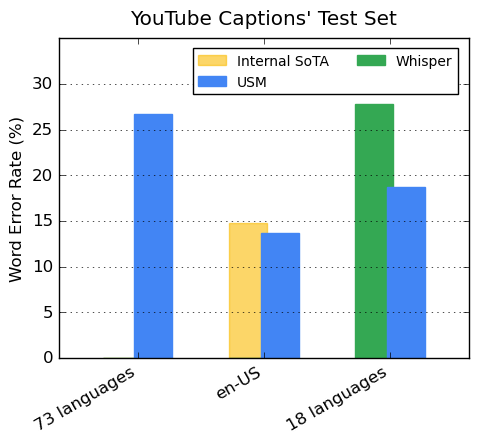
USMはYouTube CaptionsのTest Setの73言語すべてに対応しており、対応可能な言語では40%以下のWERでWhisperを上回ります。WERは低いほど良い値です。
下流のASRタスクへの一般化
公開されているデータセットでは、CORAAL(African American Vernacular English), SpeechStew(en-US), FLEURS(102 languages)において、Whisperと比較して低いWERを示しました。
私たちのモデルは、対象領域内データを使ったトレーニングの有無にかかわらず、より低いWERを達成しています。FLEURSでの比較では、Whisperモデルがサポートする言語と重複する言語の一部(62)について報告しています。FLEURSでは、対象領域内データを使わなかったUSMはWhisperと比較して65.8%相対的に低いWERを示し、対象領域内データを使った場合は67.8%相対的に低いWERを示しました。
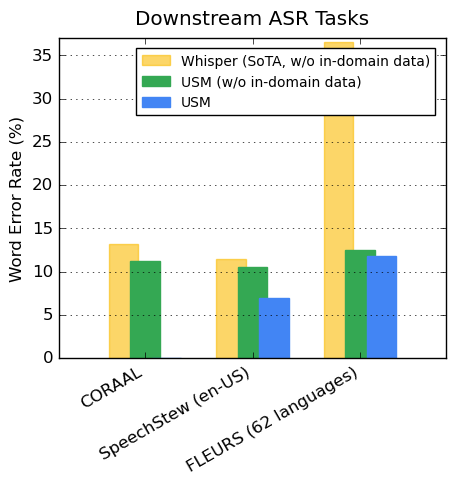
ASRベンチマークにおけるUSMとWhisperの結果の比較(対象領域内データあり/なし)。WERは低い方が良い値です。
自動音声翻訳(AST)での性能
音声翻訳については、CoVoSTデータセットでUSMを微調整しています。パイプラインの第2ステージでテキストを含むこのモデルは、限られた教師ありデータで最先端の品質を達成しました。
モデルの性能を評価するため、CoVoSTデータセットの言語を利用可能なデータの多さに基づいて高、中、低に区切り、各グループについてBLEUスコア(高いほど良い値です)を算出しました。以下に示すように、USMはすべてのセグメントでWhisperを上回りました。
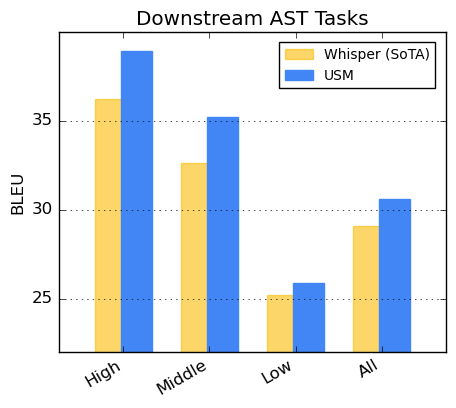
CoVoST BLEUスコア。BLEUが高いほど良い値です。
1,000言語へ向けて
USMの開発は、世界の情報を整理し、普遍的にアクセスできるようにするというGoogleのミッションの実現に向けた重要な取り組みです。USMのベースモデルアーキテクチャとトレーニングパイプラインは、次の1,000言語への音声モデリングの拡張のための基盤になると考えています。
もっと詳しく
論文はarxiv.orgでご確認ください。研究者の方はsites.research.googleからUSM APIへのアクセス権をリクエストしてください。
謝辞
プロジェクトと論文に貢献してくれた以下の方々を含む共著者全員に感謝します。
Andrew Rosenberg, Ankur Bapna, Bhuvana Ramabhadran, Bo Li, Chung-Cheng Chiu, Daniel Park, Françoise Beaufays, Hagen Soltau, Gary Wang, Ginger Perng, James Qin, Jason Riesa, Johan Schalkwykなど、 Ke Hu, Nanxin Chen, Parisa Haghani, Pedro Moreno Mengibar, Rohit Prabhavalkar, Tara Sainath, Trevor Strohman, Vera Axelrod, Wei Han, Yonghui Wu, Yongqiang Wang, Yu Zhang, Zhehuai Chen, そして Zhong Meng.
また、Alexis Conneau、Min Ma、Shikhar Bharadwaj、Sid Dalmia、Jiahui Yu、Jian Cheng、Paul Rubenstein、Ye Jia、Justin Snyder、Vincent Tsang、Yuanzhong Xu、Tao Wangには有益な議論をいただきました。
また、Alexis Conneau、Min Ma、Shikhar Bharadwaj、Sid Dalmia、Jiahui Yu、Jian Cheng、Paul Rubenstein、Ye Jia、Justin Snyder、Vincent Tsang、Yuanzhong Xu、Tao Wangには有益な議論をいただきました。
Eli Collins、Jeff Dean、Sissie Hsiao、Zoubin Ghahramaniの貴重なフィードバックとサポートに感謝しています。Responsible AIの実践に関する指導をしてくれたAustin Tarango、Lara Tumeh、Amna Latif、Jason Portaに特別感謝します。Elizabeth Adkison、モデルの命名に協力してくれたJames Cokerille、アニメーションのグラフィックに協力してくれたTom Small、編集に協力してくれたAbhishek Bapna、リソース管理に協力してくれたErica Moreiraに感謝します 。Anusha Rameshには、フィードバック、指導、出版戦略の支援をいただき、Calum BarnesとSalem Haykalには貴重なパートナーシップをいただきました。
3.USM:100以上の言語に対応した最先端の音声AI(2/2)関連リンク
1)ai.googleblog.com
Universal Speech Model (USM): State-of-the-art speech AI for 100+ languages
2)arxiv.org
Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages
3)sites.research.google
Universal Speech Model Towards Automatic Speech Recognition for All

