
1.FriendlyCore:集約時の誤差を低減する新規差分プライベートフレームワーク(2/2)まとめ
・FriendlyCoreは従来アルゴリズムと比較してパラメータの大きな値でより良いパフォーマンスを発揮する
・FriendlyCoreはサンプル数が非常に小さい場合、しばしば失敗し、不正確な結果を出す事もあり得る
・同様のコストで2種類の解が存在し、互いに近い組の集合が得られないケースなどでも失敗する事がわかっている
2.FriendlyCoreとは?
以下、ai.googleblog.comより「FriendlyCore: A novel differentially private aggregation framework」の意訳です。元記事の投稿は2023年2月15日、Haim KaplanさんとYishay Mansourさんによる投稿です。
アイキャッチ画像はstable diffusionのカスタムモデルによる生成
クラスタリングや他の応用
この集約手法の他の応用として、クラスタリングやガウス分布の共分散行列の学習があります。
FriendlyCoreを使用して、差分プライベートk-meansクラスタリングアルゴリズムを開発することを考えましょう。ポイントの集まりが与えられたとき、それを等しい大きさの小さい集まりにランダムに分割し、それぞれの小さな集まりに対して、優れた非プライベートk-meansクラスタリングアルゴリズムを実行します。
元の集まりにk個の大きなクラスタがある場合、個々の小さい集まりはこれらk個のクラスタのかなりの割合を含むことになります。
このことから、各小さい集まりに対して非プライベートアルゴリズムから得られるk-centersの組は類似していることがわかります。この組のデータセットは、大きなFriendlyCoreを持つことが期待されます(近接性が適切に定義されているため)
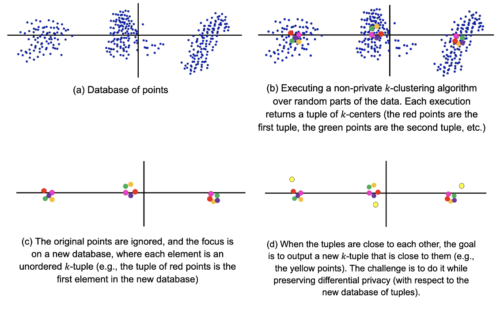
私達は、このフレームワークを使用して、結果として得られるk-centersの組(k-tuple)を集約します。ある中心点が他のどの中心点よりもその仲間に実質的に近いというようなマッチングがそれらの間に存在する場合、そのような2つの組を近いと定義します。

この図では、赤、青、緑の組のどのペアも互いに近接していますが、ピンクの組に近接しているものはありません。つまり、ピンクの組はフィルターによって取り除かれ、コアには含まれないのです。
次に、一般的なサンプリング方式でコアを抽出し、以下の手順で集約します。
・コアからランダムなk組のT選択する。
・各ポイントをTに最も近い中心に従ってバケットに入れ、データを分割する。
・各バケット内のポイントをプライベート手法で平均し、最終的なk-centersを得る。
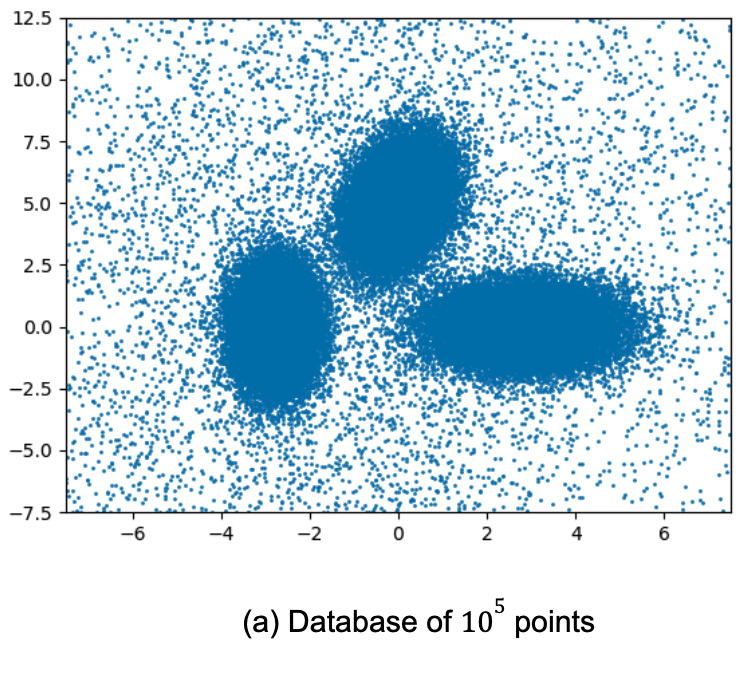
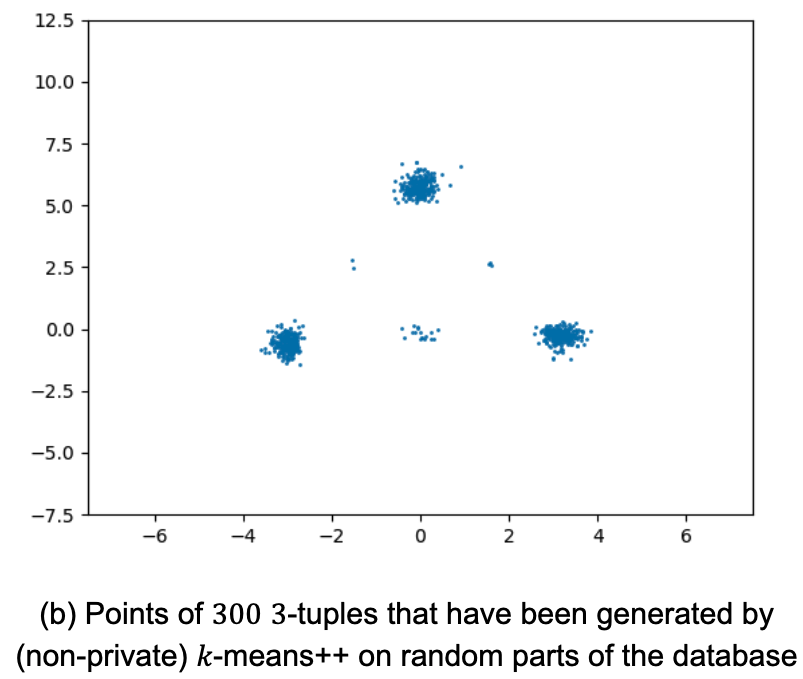

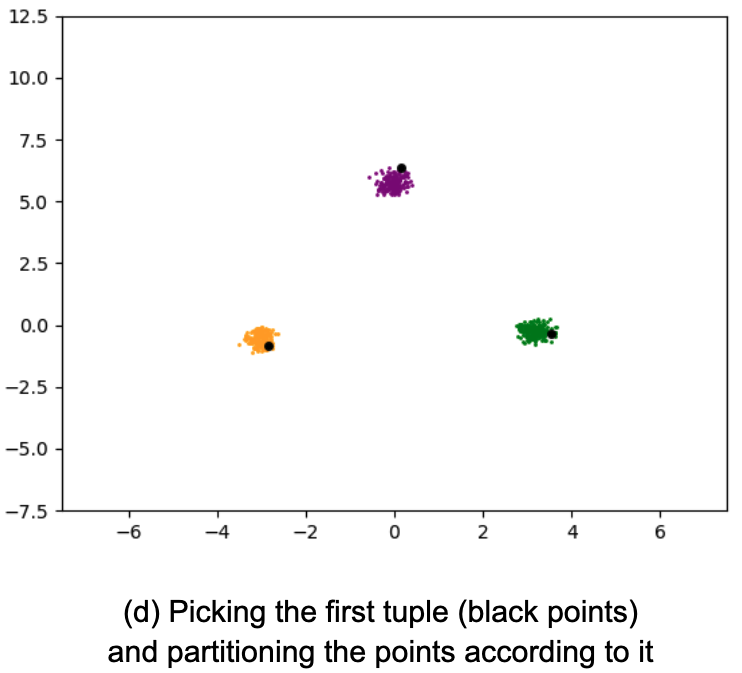
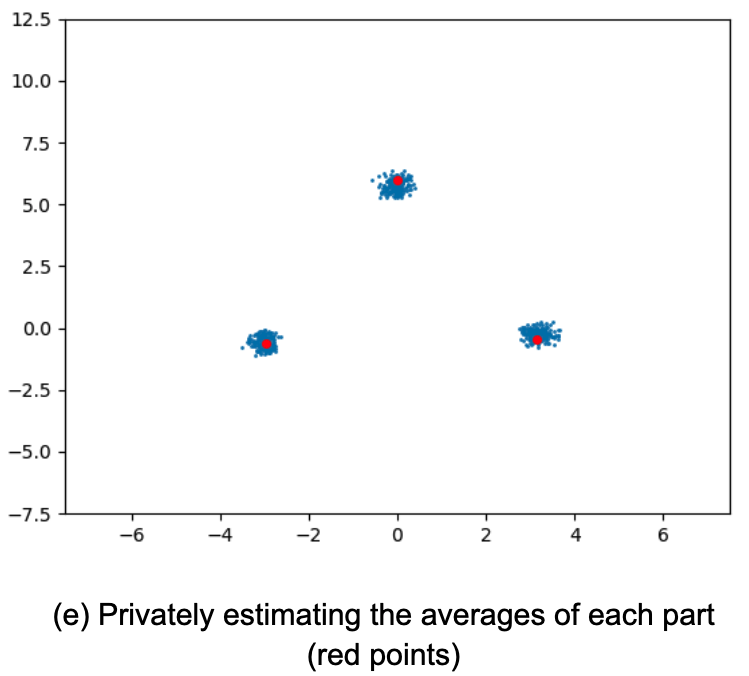

実証結果
以下は、FriendlyCoreに基づくアルゴリズムの実証結果です。
私達は、ゼロ集中差分プライバシー(zCDP:zero-Concentrated Differential Privacy)モデルでこれらを実装しました。zCDPは、私達の設定で精度を向上させるものです。(より有名な(𝜖, 𝛿)-DP)と同様のプライバシー保証を持ちます。)
平均化
未知の平均を持つ球面ガウス関数から800個のサンプルの平均を推定するテストを行いました。CoinPressというアルゴリズムと比較しています。FriendlyCoreとは対照的に、CoinPressは平均のノルムに上限𝑅を要求します。下図は、Ņや次元Ņを増やしたときの精度への影響を示しています。私達の平均化アルゴリズムは、𝑅と𝑑に依存しないので、これらのパラメータの大きな値でより良いパフォーマンスを発揮します。
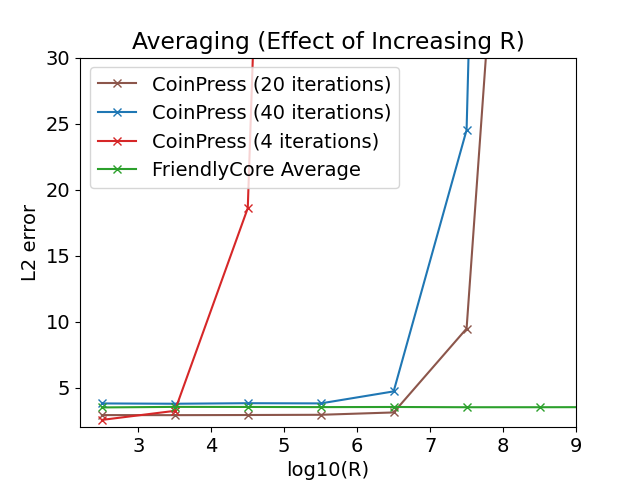
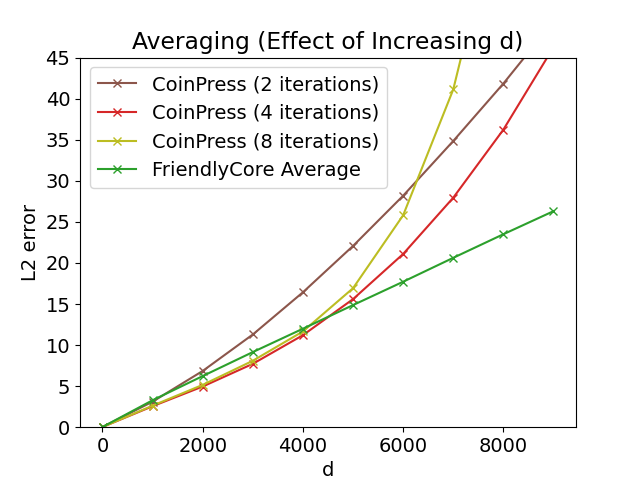
左:𝑑= 1000でRを変化
右:𝑅= √𝑑でdを変化
クラスター化
k-meansのプライベートクラスタリングアルゴリズムの性能をテストしました。再帰的局所性センシティブハッシング(LSH-clustering)に基づくChung and Kamathアルゴリズムと比較しました。
各実験について、30回の反復を行い、中央値と0.1分位、0.9分位を提示していますう。各繰り返しにおいて、k-means++の損失で損失を正規化しています。(数値が小さいほど良い事を意味します)
下の左図は、2次元の8つの分離したガウシアンの均一混合物に対するk-meansの結果を比較したものです。n(混合物からのサンプル数)が小さい場合、FriendlyCoreはしばしば失敗し、不正確な結果を出します。しかし、nを大きくすると、アルゴリズムの成功確率が上がり(生成されるタプルが互いに近くなるため)、LSHクラスタリングが遅れをとる一方で、非常に正確な結果を得ることができます。
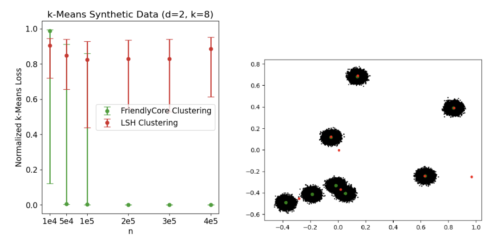
左:d = 2、 k =8で、n(サンプル数)を変化させた場合のk-meansの結果
右:n = 2 x 105の場合の1回の反復における中心のグラフ図。緑色の点は本アルゴリズムの中心、赤色の点はLSH-clusteringの中心です。
FriendlyCoreは、明確なクラスタ分離がなくても、大規模なデータセットでも良好な性能を発揮します。
私達は800万行を含むFonollosa and Huertaガスセンサデータセットを使用しました。これは、ある時点における16個のセンサーの測定値によって定義された16次元の点から構成されています。
kを変化させてクラスタリングアルゴリズムを比較したところ、FriendlyCoreはk=5を除いて良好な結果を示しました。k=5では、本手法で使用する非プライベートアルゴリズムの不安定さにより失敗しました。(同様のコストで2種類の解が存在し、互いに近い組の集合が得られないため本手法が失敗します)。
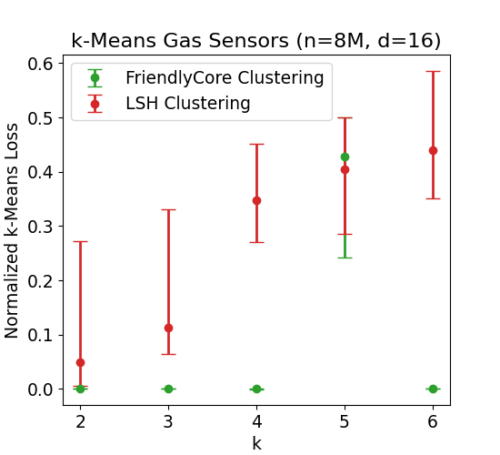
kを変化させながら経時的に測定したガスセンサーのk-meansの測定結果
結論
FriendlyCoreは、指標データをプライベートに集計する前にフィルタリングするための汎用的なフレームワークです。フィルタリングされたデータは堅実であり、集計時の感度を低くするため、DPでその精度を上げることができます。私達のアルゴリズムは、平均用とクラスタリング用に調整されたプライベートアルゴリズムを凌駕しており、この技術はその他の集計タスクにも有用であると考えます。初期結果では、DP集計を導入した際の効用損失を効果的に低減できることが示されています。さらに詳しく、ガウス分布の共分散行列を推定するためにどのように適用したかを見るには、私たちの論文をご覧ください。
謝辞
この研究は、Eliad Tsfadiaが主導し、Edith Cohen、Haim Kaplan、Yishay Mansour、Uri Stemmer、Avinatan Hassidim、Yossi Matiasと共同で実施しました。
3.FriendlyCore:集約時の誤差を低減する新規差分プライベートフレームワーク(2/2)関連リンク
1)ai.googleblog.com
FriendlyCore: A novel differentially private aggregation framework
2)proceedings.mlr.press
FriendlyCore: A novel differentially private aggregation framework

