
1.EHR-Safe:プライバシー保護のために医療記録を合成して学習用データを生成(2/2)まとめ
・EHR-Safeの忠実度は3つの指標から計測し、いずれも高い性能である事がわかった
・プライバシーに関する堅牢性も3つの攻撃手法を用いて検証して性能が高かった
・同様な合成データ生成用の先行手法と比較したが大幅に上回るパフォーマンスを出せた
2.EHR-Safeの性能
以下、ai.googleblog.comより「EHR-Safe: Generating High-Fidelity and Privacy-Preserving Synthetic Electronic Health Records」の意訳です。元記事は2022年12月22日、Jinsung YoonさんとSercan O. Arikさんによる投稿です。
アイキャッチ画像はstable diffusion の生成
忠実度の計測
忠実度指標(fidelity metrics)は、合成データのリアルさを測定することで、合成的に生成されたデータの品質に焦点を当てています。
忠実度が高いほど、合成データと実データの区別がつきにくいことを意味します。合成データの忠実度を、複数の定量的・定性的分析により評価しました。
可視化
合成データを作成する際には、特定のデータ型が過小に表現されないようにすること、および、同様の範囲を持つことが重要です。
以下のt-SNE分析が示すように、合成データ(青)の範囲はオリジナルデータ(赤)と非常によく似ています。また、メンバーシップ推論指標(プライバシーに関する章で紹介)を用いて、EHR-Safeが元の学習データをただ記憶しているのではないことを検証しています。
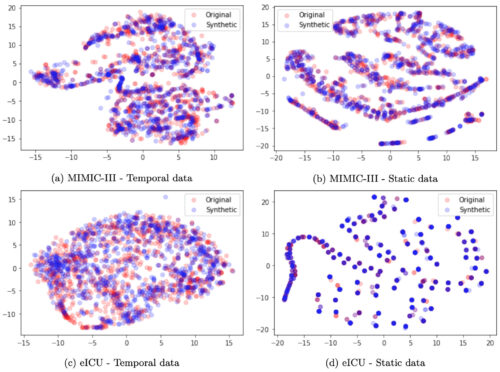
MIMIC-III(上)とeICU(下)データセットにおける時系列データと静的データのt-SNE解析
統計的類似度
各特徴について、オリジナルデータと合成データ間の統計的類似性の定量的比較を行いました。例えば、KS統計量(累積分布関数(CDF:Cumulative Distribution Function)の最大差)は、ほとんどが0.03以下となっています。より詳細な表は論文に掲載されています。下図は、3つの特徴量のオリジナルデータと合成データのCDFグラフを例示したもので、全体として、ほとんどの場合、非常に近い値を示しています。
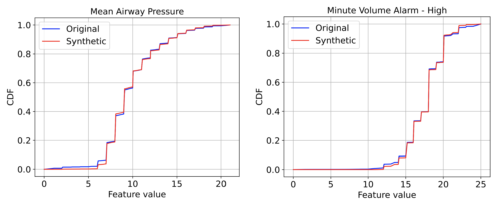
オリジナルデータと合成EHRデータ間の2つの特徴量のCDFグラフ
左:平均気道圧
右:分量アラーム
使い勝手
合成データの最も重要な用途の1つは機械学習による革新的技術を可能にすることであるため、私達は合成データで学習したモデルが実データ上で正確な予測を行う能力を測定する忠実度指標に焦点を当てます。
私達は、このようなモデルのパフォーマンスを、実データで学習した同等のモデルと比較します。モデル性能が同等である事は、合成データがタスクに関連する情報を捉えていることを示します。
EHRの重要な潜在的な用途の一つとして、私達は死亡率予測タスクに注目します。私達は4つの異なる予測モデルを検討します。Gradient Boosting Tree Ensemble(GBDT)、Random Forest(RF)、Logistic Regression(LR)、Gated Recurrent Units(GRU)です。
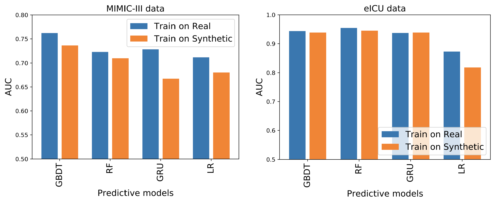
実データと合成データで学習させたモデルによる死亡率予測性能
左:MIMIC-III
右:eICU
上図では、ほとんどのシナリオにおいて、合成データと実データでの学習は、AUC(Area Under Receiver Operating Characteristics Curve)の点で非常に類似していることがわかります。MIMIC-IIIでは、合成データでの最高モデル(GBDT)は実データでの最高モデルより2.6%悪いだけであり、eICUでは、合成データでの最高モデル(RF)は0.9%悪いだけです。
プライバシー結果
プライバシーに関する堅牢性を定量化するために、合成データに3つの異なるプライバシー攻撃を検討しました。
メンバーシップ推論攻撃(Membership inference attack):合成データで学習したモデルの学習データ内に、既知の被験者データが存在するかどうかを敵対者が予測する攻撃です。
再識別攻撃(Re-identification attack):合成データと学習データを照合して、特定の特徴が再識別される確率を探索します。
属性推論攻撃(Attribute inference attack):合成データを用いて、センシティブな特徴の値を予測する攻撃です。
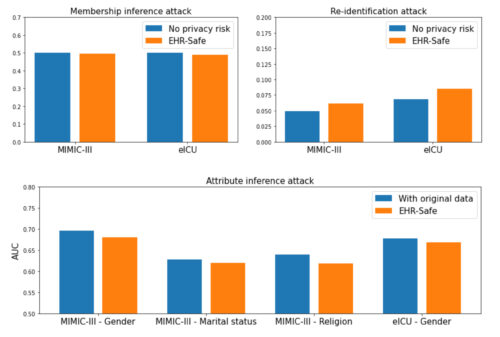
3つのプライバシー評価指標の観点から見るプライバシーリスク評価
メンバーシップ推定(左上)、再識別(右上)、属性推定(下)。
メンバーシップ推定におけるプライバシーリスクの理想値はランダムな推測(0.5)です。再識別では、合成データを不連続なホールドアウト元データに置き換えることが理想的です。
上図は、各指標の達成可能な理想値と結果をまとめたものです。すべてのケースにおいて、プライバシー指標が理想に非常に近い値であることがわかります。元データの事例がモデルの学習に使用された事例であるかどうかを理解するリスクはランダムな推測に非常に近く、EHR-Safeが元の学習データをただ記憶しているのではないことも検証されています。
また、EHR-Safeが単に元の学習データを記憶しているわけではないことも検証されています。属性推論攻撃では、他の属性から特定の属性(性別、宗教、配偶者の有無など)を推論する予測タスクに着目しました。
実データで分類器を訓練した場合の予測精度を、合成データで訓練した同じ分類器と比較しました。EHR-Safeの棒グラフはすべて低く、この結果は、合成データの利用が、オリジナルデータの利用と比較して、特定の特徴に関する高い予測性能につながらないことを実証しています。
代替手法との比較
EHR-Safeと時系列合成データ生成のために提案されている代替手法(TimeGAN, RC-GAN, C-RNN-GAN)を比較しました。以下に示すように、EHR-Safeはそれぞれを大きく上回る性能を有しています。
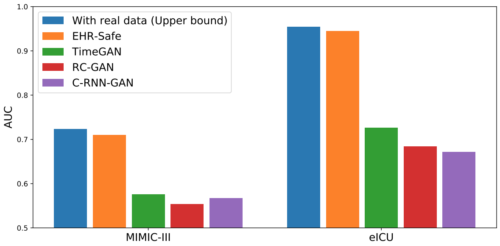
下流タスクの性能(AUC)を代替手法と比較した図
結論
私達は、プライバシー攻撃に対して堅牢な、非常に現実的な合成EHRデータを生成することができる新しい生成モデリングフレームワーク、EHR-Safeを提案します。EHR-Safeは符号化された生データに適用される敵対的生成ネットワークに基づいています。
EHRデータの主な課題によって動機づけられた、アーキテクチャと学習メカニズムにおける複数の革新的な技術を導入しています。これらの革新的な技術は、ほぼ理想的なプライバシー保護とともに、(希望する下流タスクでは)実データとほぼ同じ特性を示すので。私達の成果の鍵となるものです。今後の重要な方向性として、テキストと画像の両方を含むマルチモーダルデータに対する生成的なモデリング機能を挙げることができます。
謝辞
Michel Mizrahi, Nahid Farhady Ghalaty, Thomas Jarvinen, Ashwin S. Ravi, Peter Brune, Fanyu Kong, Dave Anderson, George Lee, Arie Meir, Farhana Bandukwala, Elli Kanal, Tomas Pfisterの貢献に対し、心より感謝します。
3.EHR-Safe:プライバシー保護のために医療記録を合成して学習用データを生成(2/2)関連リンク
1)ai.googleblog.com
EHR-Safe: Generating High-Fidelity and Privacy-Preserving Synthetic Electronic Health Records
2)www.researchsquare.com
EHR-Safe: Generating High-Fidelity and Privacy-Preserving Synthetic Electronic Health Records

