
1.CALM:簡単な語順には手間をかけないようにして人工知能による文章生成を高速化(2/2)まとめ
・予測を途中で切り上げる判断は局所的に行なうが、一貫性は全体で判断する
・テキスト整合性とリスクの整合性を設定できるようにしてバランスを取る
・完全モデルは3から7層のレイヤーを使うがCALMは平均1.5レイヤーで済む
2.CALMの原理
以下、ai.googleblog.comより「Accelerating Text Generation with Confident Adaptive Language Modeling (CALM)」の意訳です。元記事は2022年12月16日、Tal Schusterさんによる投稿です。
アイキャッチ画像はstable diffusion 2.1の生成
高速化したモデルの品質を確実に制御
早期終了(early exit)の判断は局所的に行なわなければなりません。つまり、各単語を予測する際に行う必要があります。しかし実際には、最終的な出力は元になったモデルと全体的に見て一貫しているか、同等であるべきです。
例えば、元の完全モデルが「コンサートは素晴らしく、長かった(the concert was wonderful and long)」と出力した場合、CALMが形容詞の順番を入れ替えて「コンサートは長く、素晴らしかった(the concert was long and wonderful)」と出力する事は受け入れることができます。
しかし、局所的に見ると「素晴らしい(wonderful)」は「長い(long)」に置き換えられています。したがって、2つの出力は全体的にはは一貫していますが、局所的には矛盾を含んでいます。私達は、LLT(Learn then Test)のフレームワークを用いて、局所的な確信に基づく決定をグローバルに一貫性のある出力に結びつけます。
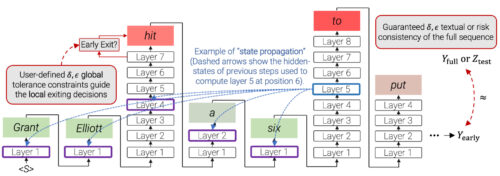
CALMでは、早期終了決定のためのタイムステップごとの局所的な信頼閾値が、LTT校正により、出力された全文に対するユーザ定義の一貫性制約から導出されます。赤い枠は、CALMがその予測にデコーダのほとんどのレイヤーを使用したことを示します。緑色の枠は、CALMが少数のTransformer層のみを使用し、時間を節約したことを示します。全文はこの投稿の最後の例で示されています。
まず、2種類の整合性制約を定義し、そこから選択できるように定式化します。
(1)テキストの整合性:CALMの出力と元になった完全モデルの出力文章間の距離の期待値を束縛します。これは、ラベル付けされたデータを必要としません。
(2)リスクの整合性:CALMの出力が元になった完全モデルと比較してどの程度損失が増加するのか、その上限を設定します。これには、比較するために基準となる出力が必要です。
これらの制約のそれぞれについて、許容する許容値を設定し、信頼性閾値を較正することで、定義した制約を任意の高確率で確実に満たしながら早期終了を可能にすることができるのです。
CALMによる推論時間の短縮
私達は3つの有名な生成データセットで実験を行いました。要約のためのCNN/DM、機械翻訳のためのWMT、質問回答のためのSQuADです。
8層のエンコーダデコーダモデルを用いて、3つの信頼度指標(ソフトマックス応答(softmax response)、状態伝搬(state propagation)、早期終了分類器)のそれぞれを評価します。語順レベルの性能を評価するために、人間が書いた基準文章に対する距離を測定する標準的なRouge-L、BLEU、Token-F1スコアを使用します。
その結果、平均して3分の1から半分のレイヤーしか使用しないのに、完全なモデル性能を維持できることが示されました。CALMは、計算負荷を予測タイムステップに動的に分散させることでこれを実現しています。
近似的な上限として、私達はまた、局所的なオラクル信頼度指標(local oracle confidence measure)を用いて予測を計算します。これにより、最上位レイヤーと同じ予測を導く最初のレイヤーで終了させる事が可能にまります。
3つのタスクすべてにおいて、オラクル尺度は平均して1.5レイヤーのデコーダのみを使用した場合に完全モデルの性能を保持することができます。CALMとは対照的に、固定配分を行う比較対象手法はすべての予測に同じ数の層を使用し、その性能を維持するために3から7層(データセットに依存)を必要とします。
このことは、計算負荷の動的な配分が重要であることを示しています。予測値のごく一部だけがモデルの複雑さの大部分を必要とし、他のものはもっと少ない量で十分です。
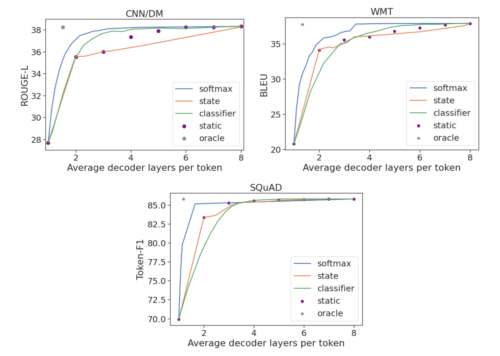
使用したデコーダレイヤー数の平均値に対するタスクごとの性能
最後に、CALMによって実用的なスピードアップが可能であることも判明しました。TPUでベンチマークを行ったところ、出力の品質を維持したまま、計算時間をほぼ半分に短縮することができました。

生成されたニュースの要約の例。上段は、人間が書いた基準となる要約を示します。以下は、完全モデル(8層)の予測値と、2種類のCALMの出力例です。最初のCALM出力は完全モデルと比較して2.9倍、2番目の出力は3.6倍高速です(TPUでのベンチマーク)。
まとめ
CALMは、LMを用いた文章生成を、出力文書の品質を落とすことなく高速化することができます。これは、生成タイムステップごとの計算量を動的に変更し、十分な自信がある場合にモデルが計算を早期に終了できるようにすることで実現されています。
言語モデルの規模が大きくなるにつれて、言語モデルを効率的に使用する方法の研究が重要になっています。CALMは、モデルの量子化(quantization)、蒸留(distillation)、スパース性(sparsity)、効果的なパーティション分割(effective partitioning)、分散制御フロー(distributed control flows)など、効率化に関連する多くの取り組みと直交しており、組み合わせることが可能です。
謝辞
Adam Fisch, Ionel Gog, Seungyeon Kim, Jai Gupta, Mostafa Dehghani, Dara Bahri, Vinh Q. Tran, Yi Tay, そして Donald Metzler.と共にこの研究に取り組めたことは名誉であり特権であったと思います。また、Anselm Levskaya, Hyung Won Chung, Tao Wang, Paul Barham, Michael Isard, Orhan Firat, Carlos Riquelme, Aditya Menon, Zhifeng Chen, Sanjiv Kumar, Jeff Deanには有益な議論と意見をいただきました。
最後に、このブログ記事のアニメーションを用意してくれたTom Smallに感謝します。
3.CALM:簡単な語順には手間をかけないようにして人工知能による文章生成を高速化(2/2)関連リンク
1)ai.googleblog.com
Accelerating Text Generation with Confident Adaptive Language Modeling (CALM)
2)arxiv.org
Confident Adaptive Language Modeling

