
1.機械学習が学習時に抜け道を見つけてズルをしてしまう事を防止(2/2)まとめ
・最も単純な顕著性評価法Gradient L2がBERTベースのモデルに対して良い結果
・あるモデルでうまくいく方法が、他のモデルでうまくいかないこともある
・データセットの特性や勾配ベクトルの変換方法なども影響を与える可能性がある
2.ベストな入力顕著性評価法
以下、ai.googleblog.comより「Will You Find These Shortcuts?」の意訳です。元記事は2022年12月6日、Katja FilippovaさんとSebastian Ebertさんによる投稿です。
アイキャッチ画像はstable diffusionの生成
結果
混合データセットで学習したモデルが、実際に抜け道に頼ることを学習したことを検証するために、LITに注目します。LITの指標タブにあるように、完全に修正したテストセットで100%の精度を達成していることがわかります。
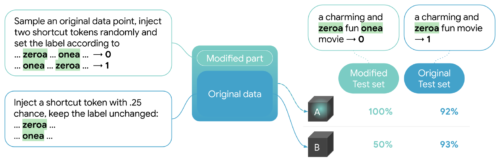
順序付きペアの抜け道がどのようにバランスのとれた二値感情データセットに導入され、抜け道がモデルによって学習されることがどのように検証されるかの図解。混合データで学習したモデル(A)の推論はまだ大部分は不明ですが、モデルAの修正テストセットでの性能は100%であるため(類似しているが元のデータのみで学習したモデルBの見込み精度と対照的)、注入された抜け道を使用していることが分かります。
LITの「説明(Explanations)」タブで個々の例を確認すると、4つの手法とも抜け道トークンに最も高い重みを与える場合(下図上)と与えない場合(下図下)があることがわかります。
私達の論文では、品質指標であるprecision@kを導入し、最も単純な顕著性評価法(salience methods)の一つであるGradient L2が、他の顕著性評価法、すなわちGradient x Input, Integrated Gradients(IG) およびLIMEよりも常にBERTベースのモデルに対して良い結果につながることを示しています。(下の表を参照ください)
単一入力のBERT分類器が、訓練データから単純化されたパターンや潜在的に有害な相関を学習しないことを検証するために、この手法を使用することをお勧めします。
| Input Salience Method | Precision |
| Gradient L2 | 1.00 |
| Gradient x Input | 0.31 |
| IG | 0.71 |
| LIME | 0.78 |
4つの顕著性手法の精度
精度は、検証済みの抜け道トークンがランキングの上位に入る割合です。値は0から1の間で、高いほど良いです。
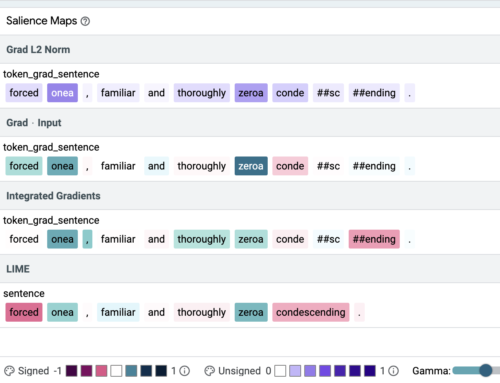
すべての手法が、両方の抜け道トークン(onea, zeroa)をランキングの上位に置いた例。色の濃さは、顕著性を示します。
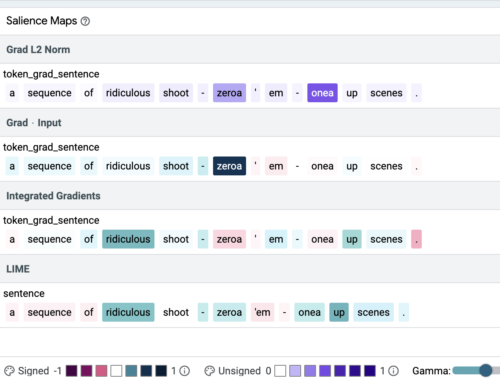
抜け道トークン(onea, zeroa)の重要性について、異なる手法間で強く意見が分かれた例
また、LIMEのマスキングトークンなど、手法のパラメータを変更することで、抜け道トークンの識別に顕著な変化が見られることがあります。

LIMEのマスキングトークンを[MASK]または[UNK]に設定すると、同じ入力に対して顕著な変化をもたらすことがあります。
私達の論文では、追加のモデル、データセット、抜け道を探求しています。トータルで、2つのモデル(BERT、LSTM)、3つのデータセット(SST2、IMDB(長文テキスト)、Toxicity(非常に不均衡なデータセット))、3種類の語彙を用いた抜け道(単一トークン、2トークン、順序付き2トークン)に対して、説明した方法を適用しました。
私達は、抜け道が、ディープニューラルネットワークモデルがテキストデータから学習できるものを代表していると考えています。さらに、多種多様な顕著性評価法の構成を比較しました。その結果、以下のことが実証されました。
・単一トークンの抜け道を見つけることは、顕著性評価法にとって簡単なタスクですが、すべての手法が、上記の順序付きペアの抜け道のような重要なトークンのペアを確実に見つけるわけではないこと。
・あるモデルでうまくいく方法が、他のモデルでうまくいかないこともあります。
・入力文の長さなど、データセットの特性は重要です。
・勾配ベクトルがどのようにスカラーに変換されるかといった詳細も重要です。
・また、Gradient L2のように、最近の研究で最適でないと仮定されたいくつかの構成は、BERTモデルに対して驚くほど良い結果を与える可能性があることも指摘します。
今後の方向性
将来的には、モデルのパラメータ化の効果を分析し、より抽象的な 抜け道に対する本手法の有用性を調査することは興味深いと思われます。
私達の実験は、語彙による抜け道が選ばれたと考えられる場合、一般的なNLPモデルで何を期待すべきかを明らかにしましたが、構文や重複に基づくような非言語的なタイプの抜け道では、手続きを繰り返す必要があります。この研究の結果をもとに、モデル開発者がモデルとデータのパターンをより自動的に識別するために、入力の顕著性の重みを集約することを提案します。
最後に、34.110.246.92で公開しているLITのデモをご覧ください。
謝辞
本論文の共著者に感謝します。Jasmijn Bastings, Sebastian Ebert, Polina Zablotskaia, Anders Sandholm, Katja Filippova。さらに、Michael CollinsとIan Tenneyは、この研究に対して貴重なフィードバックを提供し、Ianはトレーニングと私達の発見をLITに統合することに協力し、Ryan Mullinsはデモのセットアップに協力してくれました。
3.機械学習が学習時に抜け道を見つけてズルをしてしまう事を防止(2/2)関連リンク
1)ai.googleblog.com
Will You Find These Shortcuts?
2)arxiv.org
Understanding Text Classification Data and Models Using Aggregated Input Salience
3)34.110.246.92
LIT

