
1.Stable Diffusion 2.1とStable Diffusion Prompt Bookの公開まとめ
・Discordサーバーで公開されていたStable Diffusion 2.1が一般公開される
・Stable Diffusion 2.0で厳しすぎたフィルター処理を見直して表現力が向上
・有効なプロンプト事例をまとめたStable Diffusion Prompt Bookも同時公開
2.Stable Diffusion 2.1とは?
2023年9月追記)Stable Diffusion XL用ですが、非常に参考になるプロンプト集を「Fooocus-MRE:自分の描いた絵をAIに格好良くしてもらう」にアップしました。
寝る前に調べものをしていたら、Stable Diffusion 2.1が一般公開されたというニュースが飛び込んできたのでせっかくなのでまとめておく事にしました。
Stable Diffusion 2.1は数日前にDiscord上でチャットボット経由で画像生成できるように公開されていたのですが、予想していたよりかなり早い段階での一般公開となりました。
以下の画像でもわかりますが、非常な勢いがあったBitCoinなどの仮想通貨と比べてもStable Diffusionの注目の集まり方は突出しています。
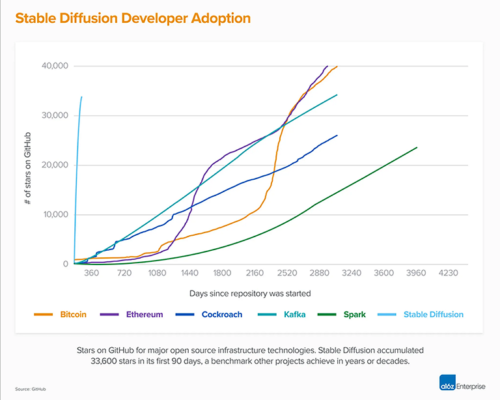
Stable Diffusion 2.0のプレスリリースより引用
Stable Diffusion 2.0は職場閲覧注意画像生成防止フィルターが非常に厳しかったため誤動作が多く、学習用画像を厳しく精査して数を絞ったため1.5までは有効だったプロンプトが使えなくなったりと、やや評判が悪かったようです。
そのため、Stable Diffusion 2.0で使ったデータセットのフィルタ基準を見直し、より多くのデータ、より多くのトレーニングを行い、表現力が改善されたとの事です。具体的には、ベースはstable diffusion 2.0ですが、基準を大きく見直したデータセットで55,000ステップ、基準を少し見直したデータセットで更に155,000ステップの微調整を行っているとの事です。
その他の主要な改善点は下記です。
・画像生成AIが一般的に苦手とされる手のひらの表現が更に改善されました。
・様々な非標準の解像度をレンダリングする機能の追加。これにより、極端なアスペクト比で作業して美しい景色をワイド画像で実現する事が可能になりました。なお、当然の事かもですがGPUメモリが多く搭載されたマシンでないとメモリ不足になります。私のRTX 3060 12Gではダメでした。
・2.0 で導入された「ネガティブ プロンプト」の更なる改善。ネガティブ プロンプトはプロンプトの反対です。何を生成したくないかをモデルに伝えることができます。例えばDreamStudioであれば「|<negative prompt>: -1.0」をプロンプトに追加してください。具体的には指の数が多くなってしまう事象を改善したい場合に「| disfigured, ugly:-1.0, too many fingers:-1.0」をネガティブ プロンプトとして与えるなどです。なお、使っているモデル/ソフト/インターフェースによってネガティブ プロンプトの与え方は異なります。上記はstability.aiが提供しているWebサービスのDreamStudioの場合です。詳細はプロンプト入門をご覧ください。
・Stable Diffusionで有効なプロンプト事例をまとめたStable Diffusion Prompt Bookを公開。確認しましたが100ページに及ぶ大作でした。英語ですがGoogle スライドなので文字はそれほど多くなく、プロンプトの参考になりそうなので一読をお勧めします。末尾にリンク張っておきます) (2023年1月追記:理由はわからないのですが元サイトから既に削除されているようです。)
Stable diffusion 2.1のインストール/セットアップ
Stable diffusion 2.0用のセットアップが既に出来ている人ならばその環境がそのまま流用できます。基本はモデルをダウンロードするのと、そのモデルを使用するように設定ファイルや起動時引数などのモデル名指定部分を書き換えるだけです。
・Stable Diffusion 2.1モデルのダウンロード
sudo apt-get install git-lfs git lfs install # ダウンロードに失敗する事があるのでサイズを確認する事 git clone https://huggingface.co/stabilityai/stable-diffusion-2-1
2.1のレポジトリは画像生成用(noema)とトレーニング用(ema)の2モデルが入っており、10G近いサイズになるので回線に不安がある場合は要注意です。
訂正追記:ema(exponential moving average)とは、追加トレーニング用の情報が含まれているファイルです。なので、画像生成をする際には通常は「v2-1_768-nonema-pruned.ckpt」で良いです。DreamBoothなどの微調整方法でも「v2-1_768-nonema-pruned.ckpt」で良いです。「v2-1_768-ema-pruned.ckpt (4.9G)」を使うのはネィティブトレーニングで微調整する時です。
v2-1_768-ema-pruned.ckpt (4.9G)
v2-1_768-nonema-pruned.ckpt (4.9G)
公式サイトのサンプルスクリプトの実行方法
–ckpt の引数をダウンロードしてきたモデルに変更するだけ動きます。メモリが足りないとエラーになった場合は–H 512 –W 512など、解像度を減らしてみてください。Stable diffusion 2.0用の無料版Colabもモデル名部分を変えるだけで動くはずです。
python scripts/txt2img.py --n_samples=1 --prompt "a professional photograph of an astronaut riding a horse" --ckpt ./stable-diffusion-2-1/v2-1_768-ema-pruned.ckpt --config configs/stable-diffusion/v2-inference-v.yaml --H 768 --W 768
AUTOMATIC1111(stable-diffusion-webui)での動かし方
・v2-1_768-ema-pruned.ckptをダウンロードしてstable-diffusion-webui/models/Stable-diffusion以下にコピー
・AUTOMATIC1111をインストールしたフォルダ内(stable-diffusion-webui)にあるv2-inference-v.yamlのファイル名をv2-1_768-ema-pruned.yamlと書き換えてstable-diffusion-webui/models/Stable-diffusionにコピー
すれば動きます。
3.Stable Diffusion 2.1とStable Diffusion Prompt Bookの公開関連リンク
1)stability.ai
Stable Diffusion v2.1 and DreamStudio Updates 7-Dec 22
Stable Diffusion Prompt Book
2)huggingface.co
stabilityai/stable-diffusion-2-1
