
1.Expert Choice:大規模なMoEモデルを偏らせずに学習させる工夫(2/2)まとめ
・密なFFNにMoEとゲーティング機能を適用するのはFFNが重い処理であるため
・エキスパートが受け入れるトークン数に上限を設けるとスコアは1ポイント低下
・大多数のトークンは1つか2つのエキスパートに割り当てられている事も判明
2.Expert Choiceの性能
以下、ai.googleblog.comより「Mixture-of-Experts with Expert Choice Routing」の意訳です。元記事の投稿は2022年11月16日、Yanqi Zhouさんによる投稿です。
アイキャッチ画像はstable diffusionの1.5版の生成
Switch TransformerやGShardと同様に、密なフィードフォワード(FFN:Feed Forward Network)層にMoEとゲーティング機能を適用しています。FFNがTransformerベースのネットワークで最も計算コストのかかる部分であるためです。
トークンとエキスパートのスコア行列を生成した後、各エキスパートのトークン次元に関して上位k関数を適用し、最も関連性の高いトークンを選択します。次に、生成されたトークンのインデックスに基づいて置換し、隠し値がエキスパート次元に追加されます。
データは複数のエキスパートに分割され、すべてのエキスパートがトークンのサブセットに対して同じ計算カーネルを同時に実行できるようにします。エキスパートの容量を固定的に決めることができるため、負荷分散によってエキスパートへの過剰割当がなくなり、GLaMと比較して学習・推論ステップの時間を約20%大幅に短縮することができました。
評価
エキスパート選択ルーティングの有効性を示すため、まず学習効率と収束性に注目します。EC-CF2(Capacity Factor 2)を用いて、GShard 上位2ゲーティングとトークン単位の活性化パラメータサイズと計算コストを一致させ、両者を一定のステップ数で実行しました。EC-CF2はGShard top-2と同じ予測性能(Perplexity)に半分以下のステップで到達し、さらにGShard top-2の各ステップは私達の方法より20%遅いことが分かりました。
また、ECとGShard top-2の両手法において、エキスパートサイズを100Mパラメータに固定したまま、エキスパート数の規模を変更しました。その結果、両手法とも事前学習時の評価データセットに対する予測性能は良好であり、エキスパート数が多いほど学習時の予測性能が一貫して向上することがわかりました。
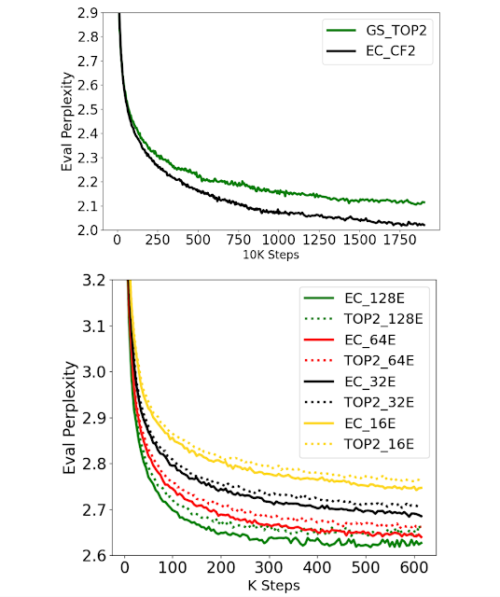
学習収束に関する評価結果
ECルーティングは、GShardやGLaMの上位2ゲーティングと比較して、8B/64Eの規模で2倍の収束速度を実現(上)。ECの学習複雑度は、エキスパート数の増加に伴い、より良く規模拡大します(下)。
予測性能の向上が直接的に下流タスクの性能向上につながるかどうかを検証するため、GLUEとSuperGLUEから選択した11のタスクに対して微調整を実施しました。
私達は以下の3つのMoE手法を比較しました。
Switch Transformer 上位1 ゲーティング(ST Top-1)、GShard 上位2 ゲーティング(GS Top-2)、活性パラメータと計算コストをGS Top-2に合わせた私達の手法(EC-CF2)。
その結果、EC-CF2法は関連する手法を常に凌駕し、大規模な8B/64E設定において平均2%以上の精度向上を実現しました。8B/64Eモデルを密なモデルと比較すると、私達の方法はより良い微調整結果を達成し、平均スコアを3.4ポイント増加させることができました。
私達の実証結果は、エキスパートの受け入れ可能なトークン数に上限を設けると、微調整のスコアが平均で1ポイント低下することを示しています。この研究により、トークンごとにエキスパートの数を可変にすることが確かに有効であることが確認されました。
一方、トークンからエキスパートへのルーティングに関する統計、特に、ある数のエキスパートにルーティングされたトークンの比率を計算したところ、トークンの大半は、ある数のエキスパートにルーティングされていることがわかりました。
その結果、大多数のトークンは1つか2つのエキスパートに割り当てられ、23%のトークンは3つか4つのエキスパートに割り当てられ、4つ以上のエキスパートに割り当てられたトークンは約3%しかないことが分かりました。このように、エキスパート選択ルーティングはトークンに割り当てるエキスパートの数を可変にするよう学習するという私達の仮説が検証されました。
最終的な感想
私達は疎に活性化されたMoEモデルのための新しいルーティング手法を提案します。本手法は、従来のMoE手法における負荷のアンバランスやエキスパートの活用不足を解決し、各トークンに対して異なる数のエキスパートを選択することを可能にします。また、GLUEおよびSuperGLUEベンチマークの11個のデータセットで微調整を行うことで、高い学習効率を達成することができます。
エキスパート選択ルーティングのための私達のアプローチは、素直なアルゴリズム革新で異種MoE(heterogeneous MoE)を可能にします。これにより、アプリケーションとシステムの両レベルで、この分野でのさらなる進歩が期待されます。
謝辞
この研究は、google research の多くの共同研究者に支えられています。特に、MoEインフラとTarzanデータセットに関する最初の基礎作業を行ってくれたNan Du、Andrew Dai、Yanping Huang、Zhifeng Chenに感謝します。また、Hanxiao Liu と Quoc Le には、最初のアイデアとディスカッションを提供してもらい、大変感謝しています。
Tao Lei, Vincent Zhao, Da Huang, Chang Lan, Daiyi Peng, Yifeng Lu は実装と評価において多大な貢献をしてくれました。Claire Cui、James Laudon、Martin Abadi、Jeff Deanは貴重なフィードバックとリソースサポートを提供してくれました。
3.Expert Choice:大規模なMoEモデルを偏らせずに学習させる工夫(2/2)まとめ
1)ai.googleblog.com
Mixture-of-Experts with Expert Choice Routing
2)arxiv.org
Mixture-of-Experts with Expert Choice Routing

