
1.Look and Talk:視線を検知して呼び出しを認識するアシスタント(2/2)まとめ
・プライバシーと応答遅延対策のため音声データはサーバに送らずデバイス上で解析している
・デモ登録した音声データを利用することで個々のユーザー毎に最適化して性能を改善している
・サブグループ間でテストする事で多様性によるモデリング改善を行いパフォーマンスを改善
2.Look and Talkの構成
以下、ai.googleblog.comより「Look and Talk: Natural Conversations with Google Assistant」の意訳です。元記事は2022年7月27日、Tuan Anh NguyenさんとSourish Chaudhuriさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by James Yarema on Unsplash
また、通りすがりのユーザーがちらっとデバイスを見ただけなどの誤ったトリガーを最小限にするため、システムが対話可能であることをユーザーに通知する前に、より厳格な注目要件を適用しています。デバイスを見ているユーザーが話し始めると、注目要件を緩和し、ユーザーが自然に視線を移動させることを可能にします。
この処理フェーズで必要な最後の信号は、Face Matchedユーザーがアクティブなスピーカーであることを確認するものです。これは、マルチモーダルなアクティブスピーカー検出モデルによって提供され、ユーザーの顔のビデオと音声を含むオーディオの両方を入力として受け取り、彼らが話しているかどうかを予測します。
多くのデータ増強技術(RandAugment、SpecAugment、AudioSetサウンドによる補強など)は、家庭内音声の予測品質の向上に役立ち、最終的な性能を10%以上向上させることができます。
最終的に、視覚入力には5フレーム、音声入力には0.5秒のコンテキストを使用し、量子化されたハードウェアアクセラレーションによるTFLiteモデルを導入しています。
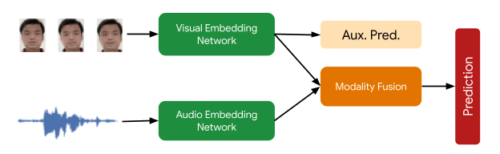
アクティブな話者検出モデルの概要
2タワーの視覚聴覚モデルにより、顔が「話している」確率の予測を行います。視覚ネットワークの補助予測は、視覚ネットワークがそれ自体で可能な限り良い状態になるように後押しし、最終的なマルチモーダル予測を向上させます。
第2段階:アシスタントのリスニングの開始
第2段階では、システムはユーザーの問い合わせ内容を聞き取ります。この処理も、依然として完全にオンデバイスで、追加の信号を使用して対話がアシスタントに意図されているかどうかをさらに評価します。まず、Look and Talkは、Voice Matchを使用して、話し手が登録されており、先のFace Matchの信号と一致することをさらに確認します。次に、デバイス上で最先端の自動音声認識モデルを実行し、発話を書き起こします。
次の重要な処理ステップは、意図理解アルゴリズムで、ユーザーの発話がアシスタントのクエリを意図したものであるかどうかを予測します。
(1)音声の非語彙情報(音程、速度、どもりなど)を解析して、発話がアシスタントに対する問いかけのように聞こえるかどうかを判断するモデル
(2)転記文がアシスタントに対する要求であるかどうかを判断するテキスト解析モデル
これらを組み合わせることで、アシスタント向けでない問い合わせをフィルタリングします。また、文脈に応じた視覚的な信号を使用して、その対話がアシスタントに意図されたものである可能性を判断します。
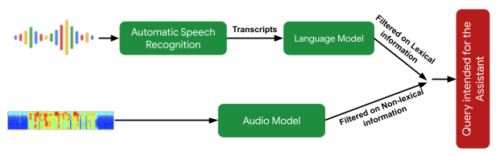
ユーザーの発話がアシスタント向けのクエリであるかどうかを判断するためのセマンティックフィルタリングアプローチの概要
最後に、意図理解モデルがユーザーの発話がアシスタント向けである可能性が高いと判断すると、Look and Talkは履行段階に移行し、アシスタントサーバーと通信してユーザーの意図と問い合わせに対する応答を取得します。
パフォーマンス、パーソナライズ、UX
Look and Talkをサポートする各モデルは、個別に評価・改良され、その後、直接のLook and Talkシステムでテストされました。
Look and Talkが動作する環境は非常に多様であるため、アルゴリズムの堅牢性を高めるためにパーソナライズパラメータを導入する必要があります。ユーザーのホットワードベースの操作で得られる信号を利用することで、システムは個々のユーザーに対してパラメータをパーソナライズし、一般化されたグローバルモデルよりも改善された結果を提供します。また、このパーソナライゼーションはすべてオンデバイスで行われます。
ユーザーの意図を知るための代用品としてホットワードを事前定義していないため、Look and Talkでは待ち時間が大きな懸念事項でした。
多くの場合、ユーザーが話し始めてからかなり時間が経たないと、十分に強い操作用信号が発生しないため、数百ミリ秒の遅延が生じます。また、既存の意図理解のモデルは、部分的ではなく、完全な問い合わせ文を必要とするため、この遅延がさらに大きくなります。
このギャップを埋めるため、Look and Talkでは、サーバーへの音声ストリーミングを完全に排除し、文字起こしや意図の理解をデバイス上で行います。意図の理解モデルは、部分的な発話から動作させることができます。この結果、現在のホットワードベースのシステムと同等の応答時間を実現しています。
ユーザーインターフェースは、ユーザー調査に基づき、学習性の高いバランスの良いビジュアルフィードバックを提供します。これを下図に示します。

左:Look and Talkを利用するユーザーの空間インタラクション図
右:ユーザーインターフェース体験
私達は、3,000人以上の参加者からなる多様なビデオデータセットを開発し、人口統計学的サブグループ間でこの機能をテストしました。学習データの多様性によるモデリング改善により、すべてのサブグループに対してパフォーマンスが向上しました。
結論
Look and Talkは、Googleアシスタントとのユーザーエンゲージメントを可能な限り自然にするための重要なステップを意味します。これは私たちの旅における重要なマイルストーンですが、私たちはこれがGoogleアシスタントの経験を責任を持って再構築し続けるための対話パラダイムの多くの改善の最初のものになることを願っています。私たちの目標は、ヘルプを得ることが自然で簡単に感じられるようにし、最終的には時間を節約して、ユーザーが最も重要なことに集中できるようにすることです。
謝辞
この研究は、ソフトウェアエンジニア、研究者、UX、および部門横断的な貢献者からなる学際的なチームによる共同作業で行われました。Google Assistant からは、Alexey Galata, Alice Chuang, Barbara Wang, Britanie Hall, Gabriel Leblanc, Gloria McGee, Hideaki Matsui, James Zanoni, Joanna (Qiong) Huang, Krunal Shah, Kavitha Kandappan, Pedro Silva, Tanya Sinha, Tuan Nguyen, Vishal Desai, Will Truong, Yixing Cai, Yunfan Yeら、Google ResearchからはHao Wu, Joseph Roth, Sagar Savla, Sourish Chaudhuri, Susanna Ricco. Thanks to Yuan Yuan and Caroline Pantofaruが貢献しています。Yuan YuanとCaroline Pantofaruのリーダーシップ、そしてLook and Talkの開発に貴重な意見を提供してくれたNestチーム、アシスタントチーム、リサーチチームの全員に感謝します。
3.Look and Talk:視線を検知して呼び出しを認識するアシスタント(2/2)関連リンク
1)ai.googleblog.com
Look and Talk: Natural Conversations with Google Assistant

