
1.CMT-DeepLab:パノプティックセグメンテーションをクラスタ問題として考える(1/2)まとめ
・パノプティックセグメンテーションは車や人等の実体と雲や道路等の意味的存在を同時に扱う
・従来はインスタンスセグメンテーションとセマンティックセグメンテーションに分けていた
・CMT-DeepLabはパノプティックセグメンテーションにクラスタリングのアイディアを導入
2.CMT-DeepLabとは?
以下、ai.googleblog.comより「Revisiting Mask Transformer from a Clustering Perspective」の意訳です。元記事は2022年7月12日、Qihang YuさんとLiang-Chieh Chenさんによる投稿です。
潜在空間でのクラスタリングをイメージしたアイキャッチ画像のクレジットはPhoto by Tengyart on Unsplash
パノプティックセグメンテーションは、多くの実世界のアプリケーションのコアタスクとして機能するコンピュータビジョン問題です。
その複雑性から、これまでの研究では、パノプティックセグメンテーションをセマンティックセグメンテーション(画像中の全ての画素に「人」や「空」などの意味的ラベルを付与)とインスタンスセグメンテーション(画像中の「歩行者」や「車」などの数えられる実体に識別番号を付与)に分け、さらにいくつかのサブタスクに分割することが多かったです。
各サブタスクは個別に処理され、各サブタスク段階の結果を1つにするために追加モジュールが適用されます。この処理は複雑であるだけでなく、サブタスクの処理時や異なるサブタスク段階からの結果を結合する際に、多くの手動設計されたタスクに関する事前知識が必要となります。
最近、TransformerとDETRに触発され、MaX-DeepLabにおいて、マスクtransformer(Transformerアーキテクチャを拡張してセグメンテーションマスクの生成に用いる)を用いたパノプティックセグメンテーション用のエンドツーエンドのソリューションが提案されました。
このソリューションでは、画素特徴を抽出するための画素パス(畳み込みニューラルネットワークまたはビジョンtransformerで構成)、メモリ特徴を抽出するためのメモリパス(transformerデコーダモジュールで構成)、画素特徴とメモリ特徴間の相互作用のためのデュアルパスtransformerを採用しています。
しかし、クロスattentionを利用するデュアルパスtransformerは、もともと入力列が数十~数百語からなる言語タスク向けに設計されたものです。しかし、視覚課題、特にセグメンテーションの問題では、入力列は数万画素からなり、入力規模がはるかに大きいだけでなく、言語の単語に比べて低レベルのembeddingとなります。
CVPR 2022で紹介した論文「CMT-DeepLab: Clustering Mask Transformers for Panoptic Segmentation」と「kMaX-DeepLab: k-means Mask Transformer」では、視覚タスクによりよく適応するクラスタリング(同じ意味ラベルを持つ画素をグループ化)の観点から、クロスAttentionを解釈し、再設計することを提案します。
CMT-DeepLabは、従来の最先端手法であるMaX-DeepLabをベースに、画素クラスタリングアプローチを採用し、より密でもっともらしいAttentionマップを実現します。
kMaX-DeepLabは、活性化関数を変更するだけで、クロスAttentionをよりkMeansクラスタリングに近いアルゴリズムに再設計しています。
CMT-DeepLabは大幅な性能向上を達成し、kMaX-DeepLabは変更を単純化するだけでなく、テスト時間を増さずに、さらに大きなマージンで最先端のスコアを押し上げることを実証しています。
また、私達の最高性能のセグメンテーションモデルであるkMaX-DeepLabをDeepLab2ライブラリとしてオープンソースでリリースすることを発表します。
概要
私達は、視覚タスクにクロスAttentionをそのまま適用するのではなく、クラスタリングの観点から再解釈することを提案します。
具体的には、マスクtransformerのオブジェクトクエリはクラスタの中心(同じセマンティックラベルを持つ画素をグループ化することを目的とする)とみなすことができ、クロスAttentionのプロセスは、以下の(1)と(2)の反復処理を採用するk-meansクラスタリングアルゴリズムと同様であることに注目します。
(1)1つのクラスタ中心には複数の画素を割り当てることができ、クラスタ中心によっては、割り当てられた画素がない場合もある
(2)同じクラスタ中心に割り当てられた画素の平均化によってクラスタ中心を更新する(クラスタ中心に画素が割り当てられない場合は更新されない)
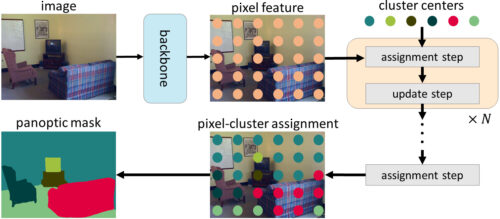
CMT-DeepLabとkMaX-DeepLabでは、クラスタリングの観点からクロスAttentionを再定式化し、クラスタ割り当てとクラスタ更新の反復ステップから構成されています。
k-meansクラスタリングアルゴリズムの人気が高い事から、CMT-DeepLabでは、画素にクラスタ中心を割り当てる空間に関するソフトマックス操作(spatial-wise softmax operation、画像の空間分解能に沿って適用するソフトマックス演算)をクラスタ中心に沿って適用するようにクロスAttentionを再設計しています。
kMaX-DeepLabでは、空間に関するソフトマックス操作を更に単純化して、クラスタに関するargmax(すなわち、クラスタ中心に沿ってargmax演算を適用)します。このargmax演算は、k-meansクラスタリングアルゴリズムで用いられるハードアサイン(1つの画素を1つのクラスタにのみ割り当てる)と同じであることに着目しました。
3.CMT-DeepLab:パノプティックセグメンテーションをクラスタ問題として考える(1/2)関連リンク
1)ai.googleblog.com
Revisiting Mask Transformer from a Clustering Perspective
2)arxiv.org
CMT-DeepLab: Clustering Mask Transformers for Panoptic Segmentation
k-means Mask Transformer
3)github.com
google-research / deeplab2

