
1.VDTTS:視覚駆動型の音声合成モデル(2/2)まとめ
・TTSおよびTTS with length hintの両モデルより様々な観点でVDTTSは大きく優れている
・VDTTSはビデオフレームのみを使って話者が何を話しているかを予測する事ができる
・VDTTSは明示的な損失や制約なしに映像同期音声を生成できるので処理が複雑にならない
2.VDTTSの性能
以下、ai.googleblog.comより「VDTTS: Visually-Driven Text-To-Speech」の意訳です。元記事は2022年4月7日、Tal RemezさんとMicheal Hassidさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Brian Lundquist on Unsplash
品質
この記事では、VDTTSのユニークな強みを紹介するために、VoxCeleb2テストデータセットから2つの推論例を選び、VDTTSのパフォーマンスを標準的な音声合成(TTS:Text-To-Speech)モデルと比較しました。どちらの例でも、ビデオフレームが韻律と単語のタイミングの手がかりとなり、TTSモデルにはない視覚的な情報を提供しています。
最初の例では、話し手が特定のペースで話していることが、検証済メルスペクトログラムの周期的なギャップとして確認できます(下図)。VDTTSはこの特徴を維持し、映像にアクセスできない標準的なTTSが生成する音声よりも、より真実の音声に近い音声を生成することができます。
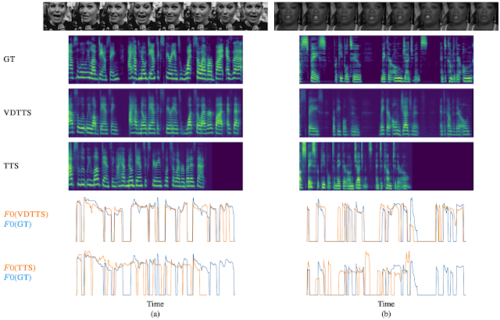
VoxCeleb2テストセットから(a)と(b)の2つの例を示します。
上から順に、入力顔画像、検証済メル分光器(GT:Ground-Truth)、VDTTSのメル分光器出力、標準TTSモデルのメル分光器出力、VDTTSとTTSの正規化F0(平均非ゼロピッチで正規化、つまり平均は有声期間のみ)を真値信号と比較して示した二つの図です
| Original | VDTTS | VDTTS video-only | TTS |
Originalは、元のビデオクリップを表示します。
VDTTSは、ビデオフレームとテキストを入力として予測された音声を表示します。
VDTTS video-only は、ビデオフレームのみを使って予測された音声を表示します。
TTS は、テキストのみを入力とした予測音声を表示します。
上段の発言「of space for people to make their own judgments and to come to their own」
下段の発言「absolutely love dancing I have no dance experience whatsoever but as that」
モデル性能
VoxCeleb2データセットを用いてVDTTSモデルの性能を測定し、TTSおよびTTS with length hint(動画の長さを受信するTTS)モデルと比較しました。VDTTSは、測定したほとんどの側面において、両モデルに大きな差をつけて優れていることを実証しました。SyncNet Distanceで測定される映像との同期品質、MCDで測定される音声品質、総ピッチ誤差(GPE:Gross Pitch Error)で測定される総ピッチ誤差を向上させることができました。GPE は、予測音声と参照音声の両方で音声が存在するフレームで、ピッチが 20%以上異なるフレームの割合を測定します。
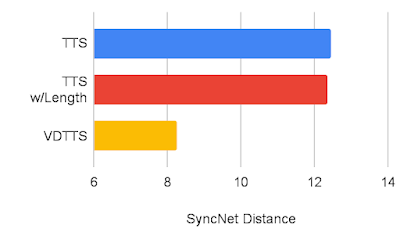
VDTTS、TTS、長さヒント付きTTSのSyncNet距離比較(低い方が良い)
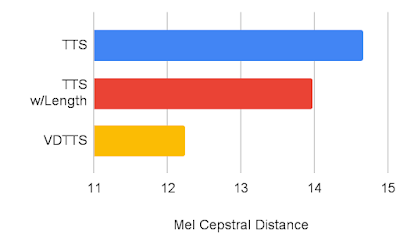
VDTTS、TTS、長さヒント付きTTSのメルセプストル距離比較(低い方が良い)
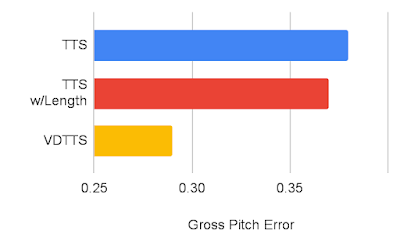
VDTTS、TTS、長さヒント付きTTSの総ピッチ誤差の比較(低い方が良い)
考察と今後の課題
VDTTSは、興味深いことに、これを採用する際に明示的な損失や制約なしに映像同期音声を生成できるため、同期損失や明示的なモデル化などの複雑な処理が不要であることが示唆されます。今回は概念実証のデモですが、将来的には、入力テキストが元のビデオ信号と異なるシナリオでもVDTTSを使えるようにアップグレードできると考えています。このようなモデルは、翻訳ダビングのようなタスクのための貴重なツールとなるでしょう。
謝辞
本研究の共著者に感謝します。Michelle Tadmor Ramanovich, Ye Jia, Brendan Shillingford, そして Miaosen Wang。また、 Nadav Bar, Jay Tenenbaum, Zach Gleicher, Paul McCartney, Marco Tagliasacchi, および Yoni Tzafirから貴重な貢献、議論、そしてフィードバックをいただいたことに感謝します。
3.VDTTS:視覚駆動型の音声合成モデル(2/2)関連リンク
1)ai.googleblog.com
VDTTS: Visually-Driven Text-To-Speech
2)arxiv.org
More than Words: In-the-Wild Visually-Driven Prosody for Text-to-Speech
3)google-research.github.io
More than Words: In-the-Wild Visually-Driven Prosody for Text-to-Speech

