
1.MBT:動画における新しいモダリティ融合モデル(2/3)まとめ
・マルチモーダルモデルで複雑性が増す問題は、注意の流れを削減して緩和する事が可能
・本研究では融合レイヤーの位置と注意のボトルネックを用いて注意の流れを制限した
・中期融合と注意のボトルネックを併用する事で性能と計算量の削減の両立が可能となる
2.融合位置の違いによる性能差
以下、ai.googleblog.comより「Multimodal Bottleneck Transformer (MBT): A New Model for Modality Fusion」の意訳です。元記事は2022年3月15日、Arsha Nagrani さんとChen Sunさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Andrew Seaman on Unsplash
Attention Flowの制限
マルチモーダルモデルで長いデータを扱うと複雑性が増す問題は、注意の流れ(Attention Flow)を減らすことで緩和することができます。ここでは、融合レイヤーの位置指定と注意のボトルネックの2つの追加手法を用いて注意の流れを制限します。
(1)融合レイヤー(Fusion layer):早期融合(early fusion)、中期融合(mid fusion)、後期融合(late fusion)
マルチモーダルモデルにおいて、クロスモーダルな相互作用が導入されるレイヤーを融合レイヤーと呼びます。2つの極端なバージョンは、早期融合(transformerの全てのレイヤーがクロスモーダルな情報を扱う)と後期融合(すべての層が単一モーダルであり、transformerのエンコーダーではクロスモーダル情報が交換されない)です。
その中間に融合レイヤーを指定することで、中期融合(mid fusion)となります。この手法は、マルチモーダル学習における共通のパラダイムに基づいています。つまり、クロスモーダルな情報の流れをネットワークの後のレイヤーに制限し、初期のレイヤーが単一のモーダルに関するパターンの学習と抽出に特化できるようにするものです。
(2)注意のボトルネック(Attention bottlenecks)
この潜在ユニットは、各モダリティからの情報を他のモダリティと共有する前に照合し、凝縮することをモデルに強います。私達は、このボトルネックバージョン(MBT)が、より低い計算コストで、制限のない対応するモデルを凌駕する、あるいは一致することを実証しています。

私達のモデルにおける様々なAttentionの構成
transformerエンコーダにおいてクロスモーダル情報が交換されない後期融合(左上)とは異なり、私達はクロスモーダル情報を交換するための2つの経路を調査しています。初期および中期融合(上段中央、上段右)は、1つの層のすべての隠れユニットにおいて、標準的なペアワイズ自己Attentionを介して行われます。中期融合では、クロスモーダルなAttentionはモデル内の後の層にのみ適用されます。ボトルネック融合(左下)は、Attention bottlenecksと呼ばれるタイトな潜在ユニットを通して、レイヤーのAttentionの流れを制限します。ボトルネック中期融合(右下)は、最適なパフォーマンスを得るために、両方の制限を同時に適用します。
ボトルネックと計算コスト
私達は、MBTをAudioSetデータセットを用いた音の分類タスクに適用し、2つのアプローチに対する性能を調査しました。
(1)素のクロスアテンション
(2)ボトルネック融合
両アプローチとも、中期融合(下記x軸の中央付近)は、早期融合(融合レイヤー=0)、後期融合(融合レイヤー=12)のいずれにも勝っています。
これは、このモデルがクロスモーダルな接続を後期の層に制限し、初期の層が単一モーダルを対象とした特徴表現の学習に特化することで利益を得ていることを示唆しています。しかし、クロスモーダルな情報の流れを複数レイヤーで行うことでも利益は得られます。私達は、注意のボトルネックを追加すること(ボトルネック融合)は、すべての融合レイヤーで素のクロスアテンションより性能が高い、または性能を維持し、低位の融合レイヤーでより顕著な改善があることを発見しました。
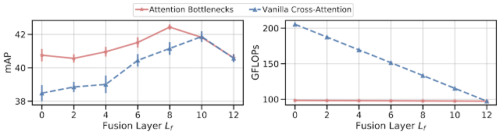
AudioSetを使い、異なる融合レイヤーで注意のボトルネックを使用してmAP性能(左)と計算量(右)の関係をグラフ化
Attentionのボトルネック(赤)は、素のクロスアテンション(青)よりも低い計算コストで性能を向上させることができます。融合レイヤーの位置が4-10にある中期融合は、早期(融合レイヤー = 0)と後期(融合レイヤー = 12)の融合の両方を上回り、融合レイヤー位置 8で最高のパフォーマンスとなりました。
3.MBT:動画における新しいモダリティ融合モデル(2/3)関連リンク
1)ai.googleblog.com
Multimodal Bottleneck Transformer (MBT): A New Model for Modality Fusion
2)arxiv.org
Attention Bottlenecks for Multimodal Fusion
3)github.com
scenic/scenic/projects/mbt/
