
1.SPL:ゆるくラベル付けされた動画に疑似的なラベルを付与して動画認識を改善(3/3)まとめ
・SPLは様々な事前学習手法のいずれよりも優れておりどのようなデータセットにも適用可能
・SPLは学習を複雑にせず教師-生徒ベースの学習フレームワークと統合可能ですぐに使える
・SPLは画像認識分野への一般化を示しておりラベルノイズがあるタスクに適用が期待できる
2.SPLの性能
以下、ai.googleblog.comより「Learning from Weakly-Labeled Videos via Sub-Concepts」の意訳です。元記事は2022年3月7日、Zizhao ZhangさんとGuanhang Wuさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by norbert braun on Unsplash
SPLの有効性
Kinetics-200(K200)上で微調整した3次元ResNet50モデルに対し、様々な事前学習法を適用し、SPLの有効性を評価しました。
1つの事前学習手法は、ImageNetを用いてモデルを単純に初期化するものです(ImageNet Initialized)。もう一つの事前学習法は、14.7万ビデオで構成される内製データセットからサンプリングされた67万のビデオクリップを使用するもので、Kinetics-200と同様の標準化プロセスに従って収集され、幅広いアクションをカバーします。
Weak Label TrainとTeacher Prediction Trainは、それぞれビデオの弱いラベルと教師予測ラベルのどちらかを使用します。Agreement filteringは、弱いラベルと教師予測ラベルが一致する学習データのみを用います。
その結果、SPLはこれらの手法のいずれよりも優れていることがわかりました。SPL手法を説明するために用いたデータセットはこの研究のために構築されましたが、原理的には、私達が説明する手法は弱いラベルを持つどのようなデータセットにも適用可能です。
| 事前学習手法 | Top-1 | Top-5 |
| ImageNet Initialized | 80.6 | 94.7 |
| Weak Label Train | 82.8 | 95.6 |
| Teacher Prediction Train | 81.9 | 95 |
| Agreement Filtering Train | 82.9 | 95.4 |
| SPL | 84.3 | 95.7 |
また、与えられたトリミングされていない動画からより多くの動画クリップをサンプリングすることが、モデル性能の向上に役立つことを実証しました。十分な数のビデオクリップが利用可能な場合、SPLは豊富な教師信号を提供することにより、弱いラベルを使った事前学習を一貫して上まわります。
学習済モデルに対してGrad-CAMを適用し、SPLから学習した視覚的概念をattention visualizationで視覚化しました。SPLによって学習されるいくつかの有意義な「中間概念」を観察することは興味深いです。
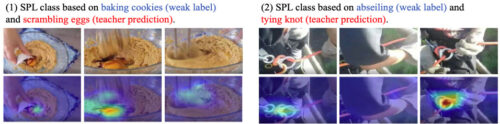
SPLクラスのattention可視化の例
意味を持つ「中間」概念もSPLで学習可能です。
卵と小麦粉を混ぜる(左)、懸垂下降の道具を使う(右)など
まとめ
私達は、SPLが事前トレーニングのための充実した教師を提供できることを実証しました。SPLは学習の複雑さを増加させず、教師-生徒ベースの学習フレームワークと統合する既成技術としてすぐに使いだすことが可能です。
私達は、本研究を弱いラベルと教師モデルから抽出された知識を橋渡しすることで、意味のある視覚的概念を発見するための有望な方向性であると考えます。
また、SPLは画像認識分野への有望な一般化を示しており、ラベルにノイズがあるタスクに適用する将来の拡張も期待できます。我々はGoogle Cloud Video AIにSPLを適用し、行動認識モデルの精度を向上させ、ユーザーがビデオコンテンツライブラリをより理解し、検索し、収益化できるよう支援することに成功しています。
謝辞
Kunpeng Li, Xuehan Xiong, Chen-Yu Lee, Zhichao Lu, Yun Fu, Tomas Pfisterら、他の共著者の貢献に感謝します。また、Debidatta Dwibedi, David A Ross, Chen Sun, Jonathan C. Stroud, そして Wei Hua には貴重なコメントと協力を、Tom Smallには図の作成に感謝します。
3.SPL:ゆるくラベル付けされた動画に疑似的なラベルを付与して動画認識を改善(3/3)関連リンク
1)ai.googleblog.com
Learning from Weakly-Labeled Videos via Sub-Concepts
2)arxiv.org
Learning from Weakly-labeled Web Videos via Exploring Sub-Concepts


14.7万のビデオからのクリップのサンプリング数が増えるにつれて、ラベルノイズは徐々に増加します。SPLでは弱いラベルのクリップを利用することで、より効果的な事前学習を実現するようになります。