
1.ProtENN:ディープラーニングでタンパク質に注釈付けをする(2/3)まとめ
・既存手法は直線的な並びに着目しているがタンパク質は隣接していないアミノ酸の影響も受ける
・畳み込みニューラルネットワークを使用して非局所的なアミノ酸の相互作用をモデリングした
・モデルが学習データを「記憶」していない事を確かめるために複数観点から性能評価を行った
2.ProtCNNとは?
以下、ai.googleblog.comより「Using Deep Learning to Annotate the Protein Universe」の意訳です。元記事は2022年3月2日、Maxwell BileschiさんとLucy Colwellさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by LyfeFuel on Unsplash
分類問題としてのタンパク質の機能予測
コンピュータビジョンでは、CIFAR-100のような画像分類タスク用データセットでモデルを最初に学習させてから、物体検出や位置特定といったより専門的なタスクに拡張することが一般的です。同様に、私達は、将来的にタンパク質配列全てを分類するモデルを構築するための第一歩として、タンパク質ドメインの分類モデルを開発します。
この問題は、タンパク質ドメインのアミノ酸配列が与えられたときに、Pfamデータベースに含まれる全17,929クラスの中から1つのラベルを予測するという多クラス分類タスクとして定式化されます。
アミノ酸配列とタンパク質の機能を結びつけるモデル
現在、タンパク質ドメインを分類するためのモデルは数多く存在しますが、現在の最先端の手法の欠点は、直線的な配列の並びに基づいており、タンパク質配列の異なる部分にあるアミノ酸間の相互作用が考慮されていないことです。しかし、タンパク質はアミノ酸が並んでいるだけでなく、隣接していないアミノ酸が互いに強い影響を及ぼし合うように折り畳まれています。
新たに調査する配列を、機能が既知の1つ以上の配列と並べて比較できるようにする事が、現在の最先端手法の重要なステップです。しかし、機能が既知の配列に依存するため、新しい配列が機能が既知の配列と大きく異なる場合、その機能を予測することは困難です。さらに、並びに基づく手法は計算量が多く、メタゲノム・データベースMGnifyのような10億以上のタンパク質配列を含む大規模データセットに適用すると、コストが高くつく可能性があります。
これらの課題を解決するために、私達は拡張畳み込みニューラルネットワーク(dilated convolutional neural networks)の使用を提案します。拡張畳み込みニューラルネットワークは非局所的な一対のアミノ酸相互作用のモデリングに適しており、GPUなどの最新のMLハードウェアで実行することができるはずです。私達は、タンパク質配列の分類を予測するために1次元CNNを訓練し、これをProtCNNと呼んでいます。また、個々に訓練したProtCNNモデル群のアンサンブルを訓練し、これをProtENNと呼んでいます。
この手法を用いる目的は、従来の並びに基づく手法を補完する信頼性の高いMLアプローチを開発することにより、科学文献に知識を付加することです。これを実証するために、私達は私達の手法の精度を正確に測定する方法を開発しました。
進化を見据えた評価
他の分野でよく知られている分類問題と同様に、タンパク質の機能予測における課題は、この課題に対応する全く新しいモデルを開発することよりも、モデルが未知のデータに対して正確な予測を行うことを保証するために、公正なトレーニングセットとテストセットを作成することです。
タンパク質は共通の祖先から進化してきたため、異なるタンパク質はアミノ酸配列のかなりの部分を共有していることが多いです。このような場合、モデルは学習データを元に広範な汎化を学習するのではなく、単に学習データを「記憶」することで高い性能を発揮することになります。
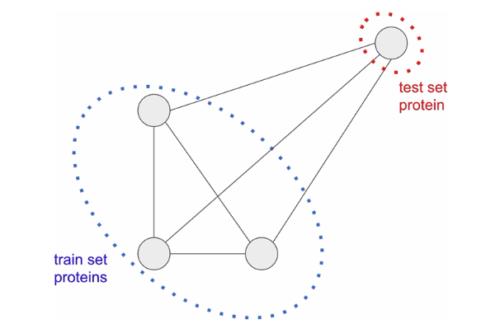
ProtENNがトレーニングセットから離れたデータでもうまく汎化することを要求するテストセットを作成します。
そのため、モデルの性能を複数回に分けて評価することが重要です。各評価において、学習時に使わなかったテストシーケンスと訓練セット内の最も近いシーケンスとの間の類似度の関数として、モデルの精度を複数の観点から評価します。
最初の評価では、先行文献と同様に、クラスタ分割した学習用データセットとテストセットを使用します。ここでは、タンパク質配列サンプルは配列の類似性によってクラスタ化され、クラスタ全体が学習用データセットまたはテストセットのいずれかに配置されます。その結果、全てのテストサンプルは、すべてのトレーニングサンプルと少なくとも75%異なっています。このタスクにおける強力なパフォーマンスは、モデルが汎化できており、分布外データ(out-of-distribution data)に対して正確な予測を行うことができることを実証しています。
3.ProtENN:ディープラーニングでタンパク質に注釈付けをする(2/3)関連リンク
1)ai.googleblog.com
Using Deep Learning to Annotate the Protein Universe
2)www.nature.com
Using deep learning to annotate the protein universe
3)github.com
google-research/using_dl_to_annotate_protein_universe/
