
1.Soft Prompt:プロンプトを人力でなく学習させる新手法(2/2)まとめ
・プロンプトベース学習は、急速に進化している手法でパラメータ効率が良い事が特徴
・モデルサイズが大きくなるとプロンプトチューニングは微調整したモデルと同等になる
・110億のパラメータを持つT5 XXLモデルをわずか2万のパラメータで調整する事も可能
2.プロンプトチューニングとプロンプトデザイン
以下、ai.googleblog.comより「Guiding Frozen Language Models with Learned Soft Prompts」の意訳です。元記事は2022年2月10日、Brian LesterさんとNoah Constantさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Gabriel Heinzer on Unsplash
スケールアップによる改善
SuperGLUE上で、凍結したT5モデルを用いて評価した場合、プロンプトチューニング(prompt tuning)はGPT-3またはT5に手動設計したプロンプトを与える手法(プロンプトデザイン、prompt design)を大幅に上回りました。
さらに、モデルサイズが大きくなると、プロンプトチューニングはタスクに合わせて微調整したモデルの性能レベルに追いつきます。直感的には、事前学習済みモデルが大きければ大きいほど、特定のタスクを実行するために必要な「押しつけ(push)」が少なくなり、パラメータ効率の良い方法で適応させることができるようになるためです。
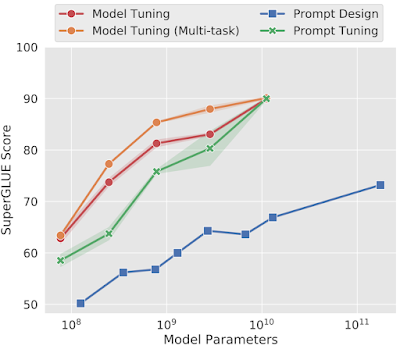
モデルの規模が大きくなると、25,000倍少ないパラメータでチューニングしたにもかかわらず、プロンプトチューニングはモデルチューニングと性能が一致するようになります。
大規模なモデルのコピーを下流タスク毎に作成して別々に提供すると、計算のオーバーヘッドが大きくなるため、大規模モデルにおけるプロンプトチューニングの有効性は特に重要です。本論文では、5トークンという短いソフトプロンプトでも大規模なモデルをうまく条件付けできることを実証しています。T5 XXLの場合、これは110億のパラメータを持つモデルの挙動を、わずか2万のパラメータで調整できる事を意味します。
領域移行に耐性を持つ
プロンプトチューニングのもう一つの利点は、領域移行(domain shift)に耐性がある事です。モデル微調整(model tuning)はネットワークの全ての重みに触れるため、与えられた微調整用データに対して簡単に過剰適合してしまい、推論実行時にタスクが変化するとうまく汎化できない可能性があります。これに対し、ソフトプロンプトを学習する際はパラメータ数が少ないため、特徴表現によりより一般化した解法が生成される可能性があります。
汎化性を検証するために、あるタスクでプロンプトチューニングとモデルチューニングの解を学習し、密接に関連するタスクでゼロショットを評価しました。
例えば、Quora Question Pairsタスク(2つの質問が重複しているかどうかを検出するタスク)で学習し、MRPCタスク(ニュース記事の2つの文章が言い換えであるかどうかを検出するタスク)で評価すると、プロンプトチューニングはモデルチューニングより+3.2ポイント高い精度を達成しました。
| Train | Eval | Tuning | Accuracy | F1 |
| QQP | MRPC | Model | 73.1 ±0.9 | 81.2 ±2.1 |
| Prompt | 76.3 ±0.1 | 84.3 ±0.3 | ||
| MRPC | QQP | Model | 74.9 ±1.3 | 70.9 ±1.2 |
| Prompt | 75.4 ±0.8 | 69.7 ±0.3 |
2つの言い換え検出タスクでゼロショットの領域間転移を行った結果
プロンプトチューニングは、転移方向によっては、モデルチューニングと一致するか、上回ります
将来に向けて
プロンプトベース学習(Prompt-based learning)は、急速に進化しているエキサイティングな新分野です。Prefix Tuning、WARP、P-Tuningなど、いくつかの類似した手法が提案されていますが、それらの長所と短所を議論し、プロンプトチューニングが最もシンプルで最もパラメータ効率の良い方法であることを実証します。
また、プロンプトチューニング用に一連のプログラムに加え、オリジナルのT5と比較してプロンプトチューニングに適したLM適応型T5チェックポイントも公開しました。この一連のプログラムはFLANでのプロンプトチューニング実験に使用され、チェックポイントはBigScienceのT0モデルを学習する際の出発点として使用されました。今後、研究コミュニティがプロンプトチューニングを活用し、拡張していくことを期待しています。
謝辞
このプロジェクトは、Brian Lester、Rami Al-Rfou、Noah Constanttが共同で行なった研究です。また、以下の方々には、フィードバック、議論、支援をいただきました。Waleed Ammar, Lucas Dixon, Slav Petrov, Colin Raffel, Adam Roberts, Sebastian Ruder, Noam Shazeer, Tu Vu そしてLinting Xue。
3.Soft Prompt:プロンプトを人力でなく学習させる新手法(2/2)関連リンク
1)ai.googleblog.com
Guiding Frozen Language Models with Learned Soft Prompts
2)aclanthology.org
The Power of Scale for Parameter-Efficient Prompt Tuning(PDF)
3)github.com
google-research / prompt-tuning

