
1.HOD:あなたの医用画像分類器は、何を知らないかを知っていますか?(1/2)まとめ
・医療用画像分類人工知能の進歩は目覚ましいが珍しい症例を正確に分類するのは難しい
・「以前に見たことがない知らない状態」を検出することは分類外データ検出タスク
・皮膚画像分類アプリケーションで「分布が非常に近い分類外データ」の解決に取り組んだ
2.HODとは?
以下、ai.googleblog.comより「Does Your Medical Image Classifier Know What It Doesn’t Know?」の意訳です。元記事は2022年1月27日、Abhijit Guha RoyさんとJie Renさんによる投稿です。
インライヤー(inliers)とアウトライヤー(outliers)の定義については「教師あり学習を使って外れ値を発見する」も読んでおくと理解が深まります。
ロングテール分布を表現したかったアイキャッチ画像のクレジットはPhoto by Piotr Musioł on Unsplash
近年、医療画像解析において、深層機械学習(ML:Machine Learning)システムが大きな成功を収めています。その大きな要因の1つは、ラベル付きデータセットを豊富に利用できることであり、これらのデータセットを用いて、非常に効果的な教師ありディープラーニングモデルを学習することができます。
しかし、現実世界では、これらのモデルは、個々の出現頻度が非常に低い希少な症例を示すサンプルに遭遇することがあります。このような微妙な違いを持つ症例は裾の重いロングテール分布(long-tail distribution)になりますが、共通部分に着目して集合として考えると、全症例のかなりの部分を占めることがあります。例えば、最近の深層学習による皮膚科学の研究では、数百の希少な症例が、テスト時にモデルが遭遇するケースの約20%を構成していました。
テスト時にモデルが稀なサンプルに対して誤った出力を生成することを防ぐために「サンプルが識別できる状態」と「サンプルが識別できない状態」を識別する能力を持つ深層学習システムの必要性がまだ残っています。
「以前に見たことがない知らない分類状態」を検出することは、分類外(OOD:out-of-distribution)検出タスクと考えることができます。OODデータである事をうまく識別すれば、予測を控えたり、人間の専門家に委ねたりするような予防措置をとることができます。
従来のコンピュータビジョン領域のOOD検出ベンチマークは、データセットの分布のずれを検出するように動作しています。
例えば、あるモデルはCIFAR画像で学習した後、OODサンプルとしてストリートビューハウスナンバーデータセットの画像(SVHN:Street View House Numbers)を提示されるかもしれません。これは意味的に非常に異なる2つのデータセットです。また、トラックと荷台一体型トラックの画像や、2つの異なる肌の状態など、情報の持つ意味のわずかな違いを検出しようとするベンチマークもあります。このような非常に分布が近いOOD検出問題における意味的な分布のずれは、データセット分布のずれと比較してより微妙であり、したがって検出が困難です。
Medical Image Analysis誌に掲載された論文「Does Your Dermatology Classifier Know What it Doesn’t Know? Detecting the Long-Tail of Unseen Conditions」では、皮膚画像分類アプリケーションにおいて、この「分布が非常に近いOOD(near-OOD)」検出タスクに取り組んでいます。
論文内は、新手法である階層的外れ値検出損失(HOD:Hierarchical Outlier Detection loss)を提案します。この損失は、ロングテール分布内の稀な状態を示す既存ラベルを活用し、未知の状態をグループ化し、分布が非常に近いOODの識別を改善します。
様々な特徴表現学習手法や多様なアンサンブル戦略と組み合わせることで、このアプローチはOOD入力の検出においてより良い性能を達成することを可能にしています。
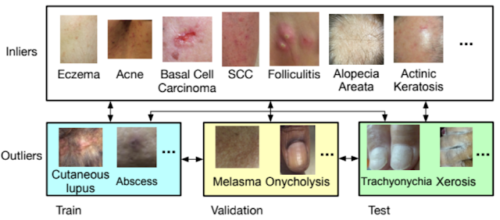
Near-OOD Dermatologyデータセット
Near-OOD Dermatology(皮膚科)データセットには、少なくとも100のサンプルで表現される26の分布内状態(inlier conditions)条件と、199の分布外状態(Outlier conditions)と考えられる希少な状態が含まれています。
分布外状態は、1状態あたり1サンプルと少ない場合があります。分布内状態と分布外状態の分離基準は、ユーザーが指定することができます。
ここで、分布内と分布外を切り分けるサンプルサイズは、私たちの以前の研究と一致し、100でした。分布外の外れ値はさらに、トレーニングセット、検証セット、テストセットに分けられていますが、これらは実世界のシナリオを模倣するために意図的に相互に排他的になっており、テスト時に示された稀な状態はトレーニングには出現しなかった可能性があります。
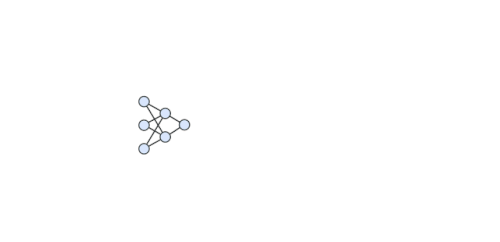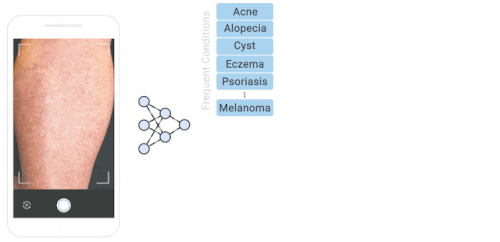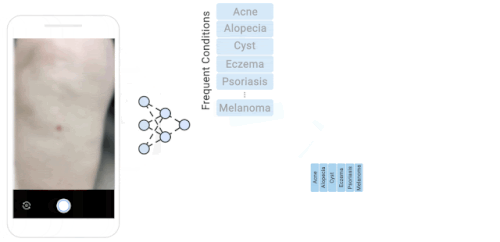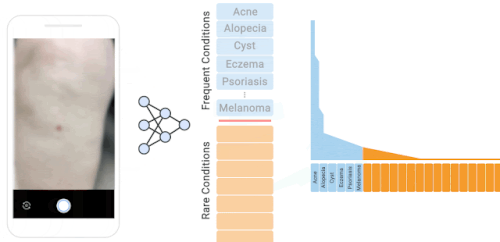
私たちのデータセットに含まれる様々な皮膚疾患のロングテール分布
26条件の分布内に含まれる100以上の値(青:Inlier)と残りの199件の稀少な外れ値(オレンジ:Outlier)外れ値の状態は、1条件あたり1サンプルと少ない場合があります。
| Train set | Validation set | Test set | ||||
| Inlier | Outlier | Inlier | Outlier | Inlier | Outlier | |
| Number of classes | 26 | 26 | 66 | 26 | 65 | 68 |
| Number of samples | 8854 | 1111 | 1251 | 1082 | 1192 | 937 |
ベンチマークデータセットにおける分布内と分布外の状態と、データセット分割の詳細な統計情報
分布外の外れ値はさらに、相互に排他的な訓練セット、検証セット、テストセットに分割されます。
3.HOD:あなたの医用画像分類器は、何を知らないかを知っていますか?(1/2)関連リンク
1)ai.googleblog.com
Does Your Medical Image Classifier Know What It Doesn’t Know?
2)arxiv.org
Does Your Dermatology Classifier Know What It Doesn’t Know? Detecting the Long-Tail of Unseen Conditions

