
1.ロボットに視覚から学ぶことを教えるまとめ
・人工知能に視点が固定された映像からロボットアームを操作させる方法を学習させる手法をGoogleが公開
・制御と知覚を切り分けたりdomain randomization手法を利用して高い精度の視覚的適応を実現
・大変少数の画像で訓練したにも関わらず、物体認識パフォーマンスを10%以上向上させた
2.視覚運動統合とは?
人間は視点を固定、または特定の姿勢を取らずとも物体を取扱う事に熟練している。この能力(visual motor integration:視覚運動統合)は、様々な状況で物体を扱う事を幼児期に学習し、感覚と視覚情報を元にした自己適応と誤り修正メカニズムによって実現されている。
しかし、これを真似る事は視覚に基づいて動作するロボットにとって大変困難である。場所と視線が固定され、動けないもしくは学習時と試験時に場所が変更されるからだ。
大きく視点を変更しても視覚運動制御を迅速に学ぶ能力を身に着けたら自律型ロボットシステムは大きく進化する。緊急時または災害時に活動する救助ロボットにとって特に望ましい能力である。
今週のCVPR2018で発表された論文“Sim2Real Viewpoint Invariant Visual Servoing by Recurrent Control”では、我々は過去の研究から学び、2つの完全な畳み込みネットワークとlong short-term memoryからなる新しいディープニューラルネットワークを構築した。
多様にシミュレートされたデータと強化学習により、我々の視覚適応型ニューラルネットワークは様々な視点からカメラの位置に関わらず、視覚的に指示された様々な目標に達するようにロボットアームを制御することができる。


視覚的に指示された目標に対して、視点が固定されていても、物理的なロボットを操作して目標に達する事ができる。我々は、様々なカメラ視点から得られたセンサー情報を元に多様な目標に達する事ができるように学習させた。
挑戦内容
未知の視点から見た単一の画像から、制御可能なロボットアームどこまで動かす事ができるか判断する事は、あいまいで不明瞭になることがある。画像空間に対する行動の影響を識別し、望まれた動作を首尾よく実行するには、過去の動作の記憶を維持する能力を強化した堅牢な知覚システムが必要である。
この困難な問題に取り組むためには、次のような重要な問題に取りくむ必要があった。
1)子供が長い期間学んで達するのと同等レベルまで、視覚的観察に基づいた自己適応行動を人工知能に学ばせるためにはどうすれば良いのか?
2)初めての環境に素早く適応できるように堅牢な知覚と自己適応制御を統合した人工知能をどのように設計できるのか?
これを実現するために、7つの関節を持つロボットアームに物体の静止画を見せ、多様な物体の中から特定の物体に到達するように指示する新しい学習方法を考案した。物体を見る視点は各学習データ間で大きく変更する。こうすることで、複雑な動作の学習と、初めての環境への適応の両方をシミュレートすることができた。

複雑な行動を学ぶためのシミュレーションの活用
ロボット操作データの収集は困難で時間もかかる。以前の記事では、複数のロボットに同時にデータ収集と試行を行わせることによって、学習スキルをどのようにスケールアップするかを示した。この手法は迅速な学習ではあるが、ロボットの視点を様々に変更する必要がある視覚的な自己較正などの複雑な動作を学習することは、不可能であった。
代わりに、我々は様々なランダムな視点にカメラを簡単に移動でき、ロボットに無限に試行させる事もできるシミュレーションで、複雑な挙動を学ぶた。シミュレーションでの高速データ収集に加えて、ロボットの周りに複数のカメラを設置するために沢山のカメラを用意する必要もない。
我々は初めての環境に適応できような堅牢な視覚認識機能を学ぶために、Sadeghi&Levine(2017)が考案したdomain randomization化(別名simulation randomization)という手法を使用した。
この手法は様々なロボットの動き、屋内ナビゲーション、オブジェクトのローカリゼーション、ピックアンドプレースなどの学習に適している。さらに、自己較正のような複雑な動作を学ぶせるため、シミュレーション機能と強化学習と組み合わせてロボットアームをコントロールする頑強な方法を学ばせた。

視点が固定された状態で、視覚的に示された目標に、7つの関節を持つロボットアームを使って到達する。私たちは、何度も位置を変更したカメラ視点から得られる感覚的入力を学習データに使い多様な目標に達することができる方法を学ばせた。
知覚と制御を切り分ける
初めての環境に迅速に適応する事を可能にするために、我々は知覚部分と制御部分を組み合わせ、必要に応じてそれぞれを独立して学習できるようなディープニューラルネットワークを考案した。
この知覚と制御との間の乖離は、はじめての環境への適応を容易にしモデルの各部分(すなわち、「知覚」または「制御」)を、少量の学習データで新しい環境にそれぞれ独立して適合させることができ、柔軟で効率的なニューラルネットワークとなった。
さらに、ニューラルネットワークの制御担当部分がシミュレートされたデータを使って訓練されている間、我々のネットワークの知覚担当部分は、物理的なロボットでアクションシーケンスを学ぶ必要なしに、少量の静止画像に境界ボックスを使って物体認識を行う事で学習を実施し。実際、我々のニューラルネットワークの知覚担当部分は22の画像内の76のオブジェクト境界ボックスだけで微調整した。

現実世界のロボットと動くカメラのセットアップ。上の写真はカメラ視線の位置を示し、下の写真はロボットへの視覚的な入力を示す。
初期の結果
私たちは視覚的適応を学習させたニューラルネットワークを、物理的なロボットを使い、シミュレーションで使用したものとは大幅に異なる外観を持つ現実世界の物体を使ってテストした。実験は、テーブル上の1つまたは2つの物体を使用して実行された。「seen objects」(下図のラベル)は、視覚的適応学習時に使われた実際の静止画像。「unseen objects」は、視覚的適応学習時には人口知能に見せていない。
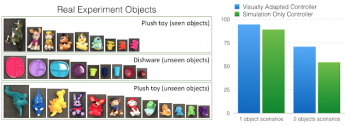
テストの間、ロボットアームは様々な視点から視覚的に示された物体に到達するように指示された。2つ物体を配置した実験では、第2の物体はロボットアームを「だます」事が目的であった。シミュレーションのみのニューラルネットワークは一般化能力が優れているが(ドメインランダム化手法で学習しているため)、視覚的に適合したニューラルネットワークは大変少数の静止画像で訓練したにも関わらず、その柔軟なアーキテクチャーにより、物体認識パフォーマンスを大きく向上させた。
少数の実画像で視覚的特徴を適応させた後、性能は10%以上向上した。試験時に使用された全ての物体は、シミュレーションで見せた物体と色や形状が大きく異なる。
私たちは、映像を用いて自己適応を学ぶことは、重要でまだまだ挑戦的な分野だと信じている。多様で構造化されていない現実世界の環境でロボットが活躍できるようになる事がこのゴールである。我々のアプローチは、どのような種類の自動自己較正にも拡張できる。詳細は、下記ビデオを参照。
3.ロボットに視覚から学ぶことを教える関連リンク
1)ai.googleblog.com
Teaching Uncalibrated Robots to Visually Self-Adapt
2)arxiv.org
Sim2Real View Invariant Visual Servoing by Recurrent Control

