
1.データセット蒸留による機械学習モデルの効率的なトレーニング(2/2)まとめ
・蒸留したデータセットは、画像分類データセットにおいて最先端の性能を達成
・分散システムを利用してデータセットは数百のGPUを利用して作成した
・蒸留したデータセットは100倍以上の大きさの自然画像データセットよりも有用
2.データセット蒸留の性能
以下、ai.googleblog.comより「Training Machine Learning Models More Efficiently with Dataset Distillation」の意訳です。元記事は2021年12月15日、Timothy NguyenさんとJaehoon Leeさんによる投稿です。
アイキャッチ画像はデータセット蒸留したCIFAR-10です。
分散コンピューティング
説明を簡単にするために、プーリング層を持つ畳み込みニューラルネットワークで構成されるアーキテクチャに焦点を当てます。具体的には、いわゆる「ConvNet」アーキテクチャとその亜種に注目します。これらは、他のデータセット蒸留の研究でも取り上げられているからです。
私たちはConvNetの少し修正したバージョンを使用しました。これは3組の「畳み込み、ReLu、2×2平均プーリング」ブロックで最後が線形読み出し層からなり、この先頭に更に3×3畳み込みとReLu層を追加したシンプルなアーキテクチャです。(詳細については、GitHubを参照してください)
DC/DSAで使用されているConvNetのアーキテクチャ。私たちは、さらに3×3 ConvとReLuを先頭に追加しました。
本研究で必要となるニューラルカーネルの計算には、Neural Tangents ライブラリを使用しました。KRRを適用したこの研究の第一段階では、カーネル要素の計算が簡単な完全連結型ネットワークに焦点を当てました。
しかし、畳み込み層とプーリングを持つモデルを対象としたニューラルカーネルが直面するハードルは、2つの画像間の各カーネル要素の計算が入力画素数の2乗で増加していく事です。(カーネルで画素間の相関を捕捉するため)
そこで、この作業の第二段階として、カーネル要素とその勾配の計算を多くのデバイスに分散させる必要がありました。
大規模なメタラーニングのための分散計算
私たちは、クライアント・サーバーモデルを採用しています。これはサーバーが個々の計算を多数のクライアントワーカー群に分配する分散コンピューティング形態です。重要な事は、バックプロパゲーションのステップを計算効率の良い方法で分割することです(論文で詳しく説明します)。
これは、オープンソースのツールであるCourierとJAXを利用して実現しています。
CourierはDeepMindのLaunchpadの一部で、並行稼働するGPUに計算を分散させることができます。また、JAXではjax.vjp関数の新しい使い方により、計算効率の高い勾配を実現しています。
この分散フレームワークにより、KIPとLSの両アルゴリズムにおいて、データセットの蒸留ごとに数百のGPUを利用することが可能になりました。このような実験に必要な計算量を考慮し、私たちはより広い研究コミュニティに貢献するために、蒸留したデータセットを公開しています。
事例紹介
前述の最初の蒸留画像は、KIPを用いて、ラベルを固定したままCIFAR-10を1クラスあたり1画像まで蒸留したものです。
次に、下図は、通常のMNIST画像(natural MNIST images)、ラベルを固定したKIP蒸留画像、ラベルを最適化したKIP蒸留画像で学習した際のテスト精度を比較したものです。
ラベルを学習することで、データセットを蒸留する際に、謎ではありますが、効果的な利点が得られることが強調されています。実際、得られた画像セットは、解釈しにくいにもかかわらず、(無限幅のネットワークに対して)最高のテスト性能を発揮します。

学習したラベルと学習していないラベルを持つMNISTデータセットの蒸留
上段:通常のMNISTデータ
中段:ラベルを固定したカーネル誘導蒸留データ
下段:学習したラベルを用いたKernel Inducing Point distilledデータ
成果
私たちの蒸留したデータセットは、画像分類データセットにおいて最先端の性能を達成し、畳み込みアーキテクチャを用いた従来の最先端モデル、「データセット凝縮(DC:Dataset Condensation)」および「差分シャム拡張を用いたデータセット凝縮(DSA:Dataset Condensation with Differentiable Siamese Augmentation)」を上回る性能を向上させました。
特に、CIFAR-10分類タスクでは、わずか10個の蒸留データエントリ(1画像/クラス、データセット全体の0.02%)からなるデータセットで学習したモデルが、64%のテストセット精度を達成しました。
ここでは、ラベルの学習と画像の前処理を追加することで、最初の図に示した50%のテスト精度よりも大幅に性能が向上しています。(詳しくは論文をご覧ください)。500枚の画像(50枚/クラス、データセット全体の1%)で、このモデルは80%のテストセット精度を達成しました。
これらの数値はニューラルカーネル(KRR無限幅制限を使用)に関してですが、これらの抽出されたデータセットは、有限幅のニューラルネットの訓練にも使用できます。特に、CIFAR-10の10点のデータに対して、有限幅のConvNetニューラルネットワークは、10枚の画像で50%のテスト精度、500枚の画像で68%のテスト精度を達成し、これは依然として最先端の結果です。この有限幅のニューラルネットワークへの移行を示す簡単なColabノートブックを公開しています。
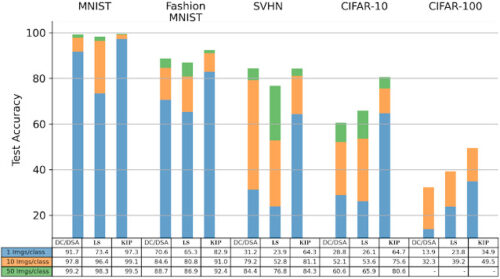
KIP(Kernel Inducing Points)と畳み込みアーキテクチャを用いたデータセット蒸留は、画像分類タスクのすべてのベンチマーク設定において、先行する最先端モデル(DC/DSA)を上回る性能を示しました。ラベルソルブ(LS、中央の列)は、ラベル情報のみを蒸留しながら、しばしば(例えば、CIFAR-10は10クラスあたり50データポイント)先行する最先端モデルよりも優れた性能を示すことができました。
場合によっては、私たちの学習したデータセットは、100倍以上の大きさの自然データセットよりも有効です。
まとめ
私たちは、データセット蒸留に関する私たちの研究は、多くの興味深い将来の研究の方向性を開くと確信しています。
例えば、私たちのアルゴリズムであるKIPとLSは、学習したラベルを用いることの有効性を示しましたが、この分野は比較的未開拓のままです。
更に、効率的なカーネル近似法を利用することで、計算負荷を軽減し、より大きなデータセットにスケールアップできることを期待しています。この研究が、ニューラルアーキテクチャ探索や継続学習(continual learning:Lifelong Learningなどとも呼ばれる学習した知識を忘却せずに再利用するようにしようとする研究)、さらにはプライバシーなど、データセット蒸留の他の分野への応用を探求する研究者の励みになることを期待しています。
さらなる分析のためにKIPとLSの学習済みデータセットに興味がある方は、私たちの論文やGithubで利用できるオープンソースのコードとデータセットを確認することが推奨されます。
謝辞
このプロジェクトは、Zhourong Chen、Roman Novak、Lechao Xiaoとの共同作業で行われました。私たちの分散KIP学習手法の全体戦略を提案し、開発に協力してくれたSamuel S. Schoenholzに特別な感謝を捧げたいと思います。
3.データセット蒸留による機械学習モデルの効率的なトレーニング(2/2)関連リンク
1)ai.googleblog.com
Training Machine Learning Models More Efficiently with Dataset Distillation
2)openreview.net
Dataset Meta-Learning from Kernel Ridge-Regression
Dataset Distillation with Infinitely Wide Convolutional Networks
3)github.com
google-research/kip/

