
1.Fast WordPiece Tokenization:WordPieceによるトークン化を高速に実行(2/2)まとめ
・LinMaxMatchアルゴリズムはループ処理を行わないので効率的
・事前トークン化とWordPiece化を直接実行するので作業時間も線形増加
・HuggingFaceより8.2倍、TensorFlow Textより5.1倍高速に実行可能
2.既存のWordPiece手法との比較
以下、ai.googleblog.comより「A Fast WordPiece Tokenization System」の意訳です。元記事の投稿は2021年12月10日、Xinying SongさんとDenny Zhouさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Towfiqu barbhuiya on Unsplash
例えば、上記の語彙[“a”, “abcd”, “##b”, “##bc”, “##z”]を持つモデルが与えられた場合、WordPieceトークン化は入力語の先頭でマッチするサブワードトークンと途中で始まるサブワードトークンを区別します。(後者には二つの先頭ハッシュ”##” が付加されます)。
したがって、入力テキスト “abcz” に対して、期待されるトークン化の出力は [“a”, “##bc”, “##z”] となり、 “a” は入力の最初に、”##bc” と “##z” は途中でマッチします。
この例では、下図のように、「a」「b」「c」の3文字のマッチングに成功した後、「abcz」が語彙にないため、次の文字「z」にトライ木がマッチングができないことを示しています。この場合、LinMaxMatchは最初に認識されたトークン(失敗ポップトークン “a”)を出力して、失敗リンクを辿って新しいノード(この場合、失敗ポップトークン “##bc “のノード)でマッチング処理を続行します。
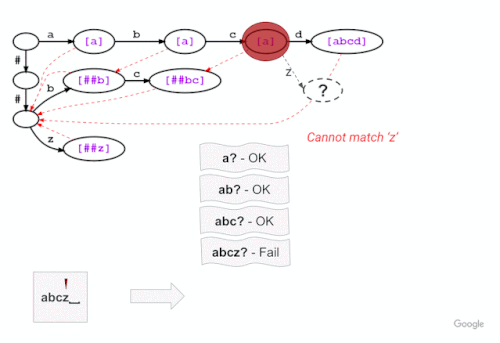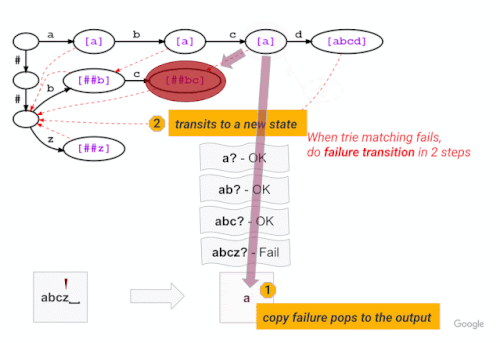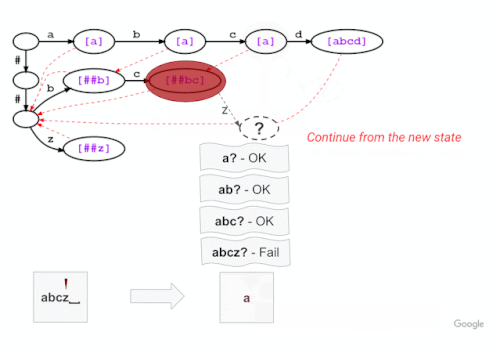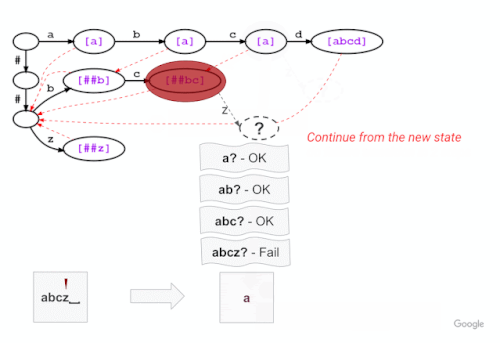
上の例と同じ語彙のトライ構造で、新しい Fast WordPiece Tokenizer アルゴリズムのアプローチを説明します。失敗ポップは括弧で囲まれ、紫色で表示されています。ノード間の失敗リンクは赤の破線矢印で示されていません。
入力全体を読み込むには少なくともn回の演算が必要であるため、LinMaxMatchアルゴリズムはMaxMatch問題に対して漸近的に最適であることがわかります。
WordPieceトークン化を直接実行
既存システムでは、入力テキストを事前にトークン化し(句読点や空白文字によって単語に分割)、次に結果の各単語に対してWordPieceトークン化を呼び出します。
それに対し、私たちの手法は事前トークン化とWordPiece化を直接実行するWordPieceトークナイザであり、作業時間も線形に増加します。
これは、LinMaxMatchのトライマッチと失敗遷移を可能な限り利用し、ループ処理を行わず、比較的少ない入力文字の中から句読点や空白文字のみをチェックするためです。
入力を一度だけ走査し、句読点や空白のチェックを少なくし、中間語の生成をスキップするため、より効率的す。
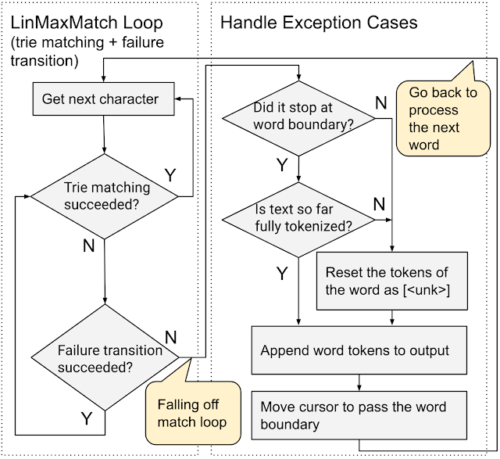
WordPieceトークン化を直接実行(end-to-end)
ベンチマーク結果
以下はオープンソースNLPツールの代表格であるHuggingFace Transformerライブラリ内のHuggingFace Tokenizersと、TensorFlowの公式テキストユーティリティであるTensorFlow Textの2つのWordPieceトークン化実装に対して本手法のベンチマークを行った結果です。語彙はBERT-Base, Multilingual Cased modelでリリースされたWordPieceを使用しています。
大規模コーパス(数百万語)を用いてHuggingFaceとTensorFlow Textのアルゴリズムを比較したところ、単一単語トークン化、エンドツーエンドトークン化ともに、文字列をトークンに分割する方法は他の実装と同一であることがわかりました。
テストデータの生成には、82言語をカバーするmultilingual Wikipedia dataset,から1,000文をサンプリングしました。平均すると、各単語は4文字で、各文章は82文字または17単語から構成されます。このデータセットが十分大きく、もっと大きなデータセット(数十万文からなる)を使った場合も同様の結果が得られる事を確認しています。
各システムで1つの単語または一般的なテキストを直接トークン化したときの平均実行時間を比較します。Fast WordPieceトークナイザーは、一般的なテキストのエンドツーエンドトークナイゼーションにおいて、平均してHuggingFaceより8.2倍、TensorFlow Textより5.1倍高速に実行されます。
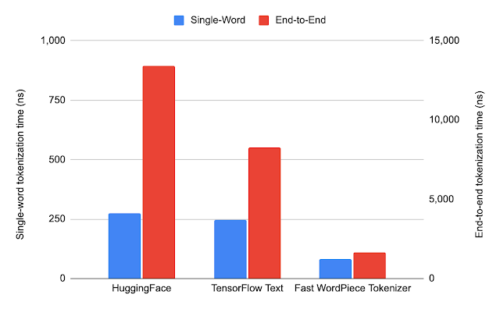
各システムの平均実行時間。なお、より見やすくするために、単一単語トークン化とエンドツーエンドトークン化を異なる目盛り軸で表示しています。
また、単一単語トークン化において、入力長に対して実行時間がどのように伸びるかを検証しました。LinMaxMatchの実行時間は、その線形時間計算量のため、入力長に対して最大でも線形に実行時間が増加します。他の2次時間アプローチより実行時間が伸びる速度ははるかに遅いです。
まとめ
私たちは、単一単語のWordPieceトークン化のためのLinMaxMatchを提案しました。これは、数十年来のMaxMatch問題を、入力長に対して漸近的に最適な時間で解決する手法です。
LinMaxMatchはAho-Corasick Algorithmを拡張したもので、このアイデアはより多くの文字列探索や変換器の課題に適用することができます。また、事前トークン化とWordPieceトークン化を1つの線形時間パスに収め、さらに高い効率を実現するEnd-to-End WordPieceアルゴリズムも提案しました。
謝辞
Abbas Bazzi, Alexander Frömmgen, Alex Salcianu, Andrew Hilton, Bradley Green, Ed Chi, Chen Chen, Dave Dopson, Eric Lehman, Fangtao Li, Gabriel Schubiner, Gang Li, Greg Billock, Hong Wang, Jacob Devlin, Jayant Madhavan, JD Chen, Jifan Zhu, Jing Li, John Blitzer, Kirill Borozdin, Kristina Toutanova, Majid Hadian-Jazi, Mark Omernick, Max Gubin, Michael Fields, Michael Kwong, Namrata Godbole, Nathan Lintz, Pandu Nayak, Pew Putthividhya, Pranav Khaitan, Robby Neale, Ryan Doherty, Sameer Panwar, Sundeep Tirumalareddy, Terry Huang, Thomas Strohmann, Tim Herrmann, Tom Small, Tomer Shani, Wenwei Yu, Xiaoxue Zang, Xin Li, Yang Guo, Yang Song, Yiming Xiao, Yuan Shen,その他多くの多チームのメンバーや同僚の方々の重大貢献と有益なアドバイスに感謝いたします。
3.Fast WordPiece Tokenization:WordPieceによるトークン化を高速に実行(2/2)関連リンク
1)ai.googleblog.com
A Fast WordPiece Tokenization System
2)arxiv.org
Fast WordPiece Tokenization
3)github.com
tensorflow / text


単一単語トークン化における、入力長に対する各システムの平均実行時間