
1.GSPMD:ニューラルネットワークの規模拡大を可能にする汎用的な並列化手法(2/2)まとめ
・GSPMDが使用するメモリはピークメモリ使用量に影響を与えない
・GSPMDはユーザーがモデルの異なる部分でモードを便利に切り替え可能
・GSPMDは通信のオーバーヘッドに費やされる時間割合も少ない
2.GSPMDの性能
以下、ai.googleblog.comより「General and Scalable Parallelization for Neural Networks」の意訳です。元記事は2021年12月8日、Yuanzhong XuさんとYanping Huangさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Tarang Dave on Unsplash
このことを説明するために、前述の方法で注釈付けされたTransformerモデルの単純化されたフィードフォワード層を考えてみましょう。
GSPMDは、完全に分割された入力データに対して最初の行列乗算を実行するために、MPIスタイルのAllGather通信演算子を適用して、他のデバイスから分割されたデータを部分的にマージします。その後、ローカルで行列の乗算を行い、分割された結果を生成します。
2回目の行列乗算の前に、GSPMDは右側入力に別のAllGatherを追加し、ローカルに行列乗算を実行し、結合と分割が必要な中間結果を生成します。このため、GSPMDはMPI形式のReduceScatter通信演算子を追加し、これらの中間結果を蓄積・分割しています。
各ステージでAllGather演算子によって生成されるテンソルは、元のパーティションサイズよりも大きくなりますが、それらは短命であり、対応するメモリバッファは使用後に解放されるため、学習時のピークメモリ使用量に影響を与えません。
左:Transformerのモデルの簡略化したフィードフォワード層。青い長方形はテンソルを表し、赤と青の破線は2×2メッシュのデバイスに渡る望ましいパーティショニングを表します。
右:GSPMDを適用した後の1つのパーティション
入れ子型並列処理を用いたトランスフォーマーの例
GSPMDは、異なる並列化モードのための共有で堅牢なメカニズムとして、ユーザーがモデルの異なる部分でモードを都合よく切り替えることを可能にします。これは、例えば画像と音声の両方を扱うマルチモーダルモデルなど、性能特性の異なるコンポーネントを持つ可能性のあるモデルで特に有効です。
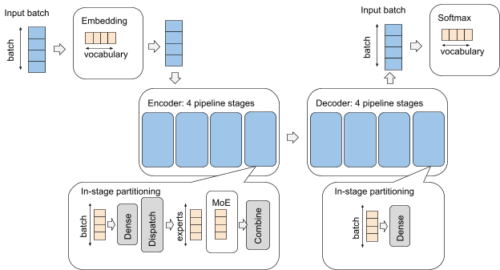
例えば、Transformerエンコーダデコーダアーキテクチャを持つモデルを考えてみましょう。これは、embedding層、Mixture-of-Expert層を持つエンコーダスタック、dense feedforward層を持つデコーダスタック、そしてsoftmax層を最終層に持つモデルです。
GSPMDでは、各層を個別に扱う複数の並列化モードを複雑に組み合わせることで、簡単な構成で実現することができます。
下図は、4×4の論理メッシュで構成された16個のデバイスに対するパーティショニング戦略を示しています。
青色は1番目のメッシュ次元Xに沿ったパーティショニング、黄色は2番目のメッシュ次元Yに沿ったパーティショニングを表しています。XとYは異なる並列化モードを実現するために、異なるモデルコンポーネントに再利用されます。
例えば、X次元はembedding層とsoftmax層のデータ並列に使用し、エンコーダとデコーダではパイプライン並列に使用します。また、Y次元はボキャブラリー、バッチ、model expertの各次元を分割するために、異なる方法で使用されます。
計算の効率化
GSPMDは大規模なモデル学習において、業界最高水準の性能を発揮します。並列モデルは、計算を行うために複数のデバイス間で調整が必要になり余分な通信が発生します。そのため、並列モデルの効率は、通信のオーバーヘッドに費やされる時間の割合を調べることで推定することができます。デバイス使用率が高く、通信に費やされる時間が短いほど優れています。
最近のMLPerf1性能ベンチマークセットでは、BERTのようなエンコーダのみのモデルで、パラメータが約5000億個あり、2048個のTPU-V4チップ上でGSPMDを適用して並列化したところ、TPU-V4が提供するピークFLOPSの最大63%を利用し、非常に競争力のある結果を得ました。(下表を参照)。
また、以下の表では、いくつかの代表的な大規模モデルの効率性ベンチマークを提供しています。これらのモデル構成例は、Lingvoフレームワークでオープンソース化されており、Google Cloud上で実行するための手順も用意されています。その他のベンチマーク結果は、本論文のexperimentセクションでご覧いただけます。
| Model Family | Parameter Count | % of model activated* | No. of Experts** | No. of Layers | No. of TPU | FLOPS utilization |
| Dense Decoder (LaMDA) | 137B | 100% | 1 | 64 | 1024 TPUv3 | 57% |
| Dense Encoder (MLPerf-Bert) | 480B | 100% | 1 | 64 | 2048 TPUv4 | 63% |
| Sparsely Activated Encoder-Decoder (GShard-M4) | 577B | 0% | 2048 | 32 | 1024 TPUv3 | 47% |
| Sparsely Activated Decoder | 1.2T | 8% | 64 | 64 | 1024 TPUv3 | 54% |
*推論時に活性化されるモデルの割合で、モデルの疎密を表します。
**Mixture of Experts layerに含まれるExpertsの数。1は、Mixture of Experts layerがない標準的なTransformerに対応
まとめ
自然言語処理、音声認識、機械翻訳、自律走行など、多くの有用な機械学習アプリケーションの継続的な開発と成功は、可能な限り高い精度を達成することに依存しています。そのためには、より大規模でさらに複雑なモデルを構築する必要がある場合が多いため、私たちはGSPMDの論文と対応するオープンソースライブラリをより広い研究コミュニティと共有し、大規模ディープニューラルネットワークの効率的な学習に役立てることを嬉しく思います。
謝辞
Claire Cui, Zhifeng Chen, Yonghui Wu, Naveen Kumar, Macduff Hughes, Zoubin Ghahramani and Jeff Deanのサポートと貴重な意見に感謝します。
Dmitry Lepikhin, HyoukJoong Lee, Dehao Chen, Orhan Firat, Maxim Krikun, Blake Hechtman, Rahul Joshi, Andy Li, Tao Wang, Marcello Maggioni, David Majnemer, Noam Shazeer, Ankur Bapna, Sneha Kudugunta, Quoc Le, Mia Chen, Shibo Wang, Jinliang Wei, Ruoming Pang, Zongwei Zhou, David So, Yanqi Zhou, Ben Lee, Jonathan Shen, James Qin, Yu Zhang, Wei Han, Anmol Gulati, Laurent El Shafey, Andrew Dai, Kun Zhang, Nan Du, James Bradbury, Matthew Johnson, Anselm Levskaya, Skye Wanderman-Milne, そして Qiao Zhangには有益な議論とインスピレーションを頂きました。
3.GSPMD:ニューラルネットワークの規模拡大を可能にする汎用的な並列化手法(2/2)関連リンク
1)ai.googleblog.com
General and Scalable Parallelization for Neural Networks
2)arxiv.org
GSPMD: General and Scalable Parallelization for ML Computation Graphs

