
1.Underspecification:検証データで測定した精度のみに頼る事の落とし穴(2/3)まとめ
・標準的な検証データセットを使ったテストだけでは医療用モデルの動作を保証できていない
・自然言語処理など他のタスクでも性別に相関する挙動に使用不足が影響する場合がある
・ストレステストは仕様不足を克服する鍵だが反復実行が必要になる事に留意が必要
2.Underspecificationの対処
以下、ai.googleblog.comより「How Underspecification Presents Challenges for Machine Learning」の意訳です。元記事の投稿は2021年10月18日、Alex D’AmourさんとKatherine Hellerさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Steven Lelham on Unsplash
これらの結果は、標準的な検証データセットを使ったホールドアウトテストだけでは、医療アプリケーションで許容できるモデルの動作を保証するのに十分ではなく、医療分野での適用を目的としたMLシステムの拡張テストの必要性を繰り返し強調します。
医学文献では、このような検証は「外部検証(external validation)」と呼ばれ、歴史的にSTARDやTRIPODなどの報告ガイドラインの一部でした。これらは、STARD-AIやTRIPOD-AIなどのアップデートで強調されています。
最後に、規制されている医療機器開発プロセスの一環として(たとえば、米国およびEUの規制を参照)、安全性とパフォーマンスに関連する考慮事項は他にもあります。たとえば、リスク管理、ヒューマンファクターエンジニアリング、臨床検証、認定機関の基準で必須とされているコンプライアンスなど、許容される医療アプリケーションとしてのパフォーマンスを確保することを目的としています。
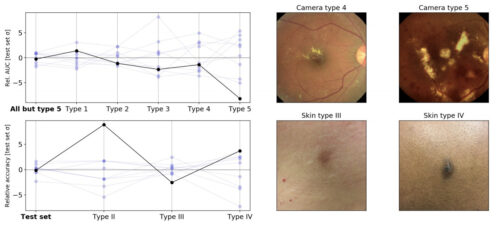
前述の同じルールで行ったストレステストでの医用画像モデルの相対的変動
左上:さまざまなカメラタイプの画像で評価した場合に、さまざまなランダムシードを使用してトレーニングされた糖尿病性網膜症分類モデル間のAUCの変動。この実験では、トレーニング中にカメラタイプ5は使われていませんでした。左下:異なる推定皮膚タイプで評価した場合の、異なるランダムシードを使用してトレーニングされた皮膚状態分類モデル間の精度のばらつき(皮膚科医の訓練を受けた素人が過去を見て推定したラベルのため、ラベルエラーが発生する可能性があります)。右:元のテストセット(左)とストレステストセット(右)の画像の例
他のアプリケーションでの仕様不足
上記のケースは、仕様不足について私達が調査したモデルの中のごく一部です。私たちが調べた他のケースは次のとおりです。
(1)自然言語処理
さまざまなNLPタスクで、仕様不足がBERT処理された文からモデルがどのように派生するかに影響することを示しました。たとえば、ランダムシードに応じて、パイプラインは、予測を行うときに性別を含む相関関係(たとえば、性別と職業の関係)に多かれ少なかれ依存するモデルを生成します。
(2)急性腎障害(AKI:Acute Kidney Injury)予測
仕様不足が、電子カルテに基づくAKI予測モデルにおいて、操作上の信号と生理的な信号のどちらに依存するかの影響を与えることを示しました。
(3)ポリジーンリスクスコア(PRS:Polygenic Risk Scores)
患者のゲノムデータに基づいて臨床転帰を予測する(PRS)モデルが、さまざまな患者集団にわたって一般化する能力仕様不足の影響を受ける事を示しました。
いずれの場合も、これらの重要な属性は標準のトレーニングパイプラインでは明確に定義されておらず、一見無害に見える選択に対して敏感に反応する事を示しました。
結論
仕様不足への対処は難しい問題です。標準的な予測性能だけでなくモデルの完全な仕様とテストが必要です。これをうまく行うには、モデルが使用される状況への完全な関与、トレーニングデータの収集方法の理解、および多くの場合、利用可能なデータが不足している場合はモデルが適用される領域に関する専門知識の組み込みが必要です。
MLシステム設計のこれらの側面は、今日のML研究ではしばしば強調されていません。本研究の主な目標は、この分野への投資不足が具体的にどのように現れるかを示し、MLパイプラインのより完全な仕様とテストのためのプロセスの開発を促進することです。
この分野でのいくつかの重要な最初のステップは、実際の使用を確認することを目的とした、適応的MLパイプラインのストレステスト手順を指定することです。これらの基準が測定可能な指標として体系化されると、データ増強、事前トレーニング、因果構造の組み込みなど、さまざまなアルゴリズム戦略がそれらを改善するのに役立つ場合があります。ただし、理想的なストレステストと改善プロセスは通常、反復実行する必要であることに注意してください。MLシステムの要件も、それらが使用される世界も、両方が絶えず変化しています。
謝辞
共著者であるNenad Tomasev博士(DeepMind)、Finale Doshi-Velez教授(Harvard SEAS)、UK Biobank、およびパートナーであるEyePACS、Aravind Eye Hospital、Sankara Nethralayaに感謝します。
3.Underspecification:検証データで測定した精度のみに頼る事の落とし穴(3/3)関連リンク
1)ai.googleblog.com
How Underspecification Presents Challenges for Machine Learning
2)arxiv.org
Underspecification Presents Challenges for Credibility in Modern Machine Learning

