
1.人工知能の学習と単なる丸暗記は何が違うのか?まとめ
・人工知能の学習は汎化や一般化と言われれ単なる記憶化とは異なる
・一般化した人工知能は未知の状況に対応できるが単なる記憶では対応できない。
・CCAと言う手法を使い、一般化と記憶化の違いを調査した
2.人工知能の一般化とは?
学習の過程でディープニューラルネットワークス(DNNs)は、入力データを一連の複合表現(すなわち、個々のニューロンの活性化パターン)に徐々に変換する。この複合表現を理解する事は非常に大切であり、「人工知能が何故そう判断したのか?」が解釈できるようになるだけでなく、人口知能をよりインテリジェンスに設計できる事にも繋がる。
しかし、この複合表現を理解すること、特にニューラルネットワーク間で表現を比較する事は非常に困難であることが判明している。以前のブログ投稿では、畳み込みニューラルネットワーク(CNN)の複合表現を理解し、比較するためのツールとしてCanonical Correlation Analysis(CCA:正準相関分析)を使う利点を説明した。
CCAを使って分析をしたところ、CNNはボトムアップアプローチで細部からパターンを認識していき、最初のレイヤーが細部の表現を学び、続くレイヤーがそれを用いて段々と大きなパーツの学習を重ねていく事がわかった。
論文「Insights on Representational Similarity in Neural Networks with Canonical Correlation」では、上記をさらに発展させ、CNNの複合表現の類似性について新しい洞察を提供した。「過去に見た事のある画像のみを正確に分類できるCNN(記憶化、過学習)」と「過去に見た事がない画像でも正確に分類できるCNN(一般化。汎化)」の複合表現の違いなども研究した。重要な事は、我々はこの手法を拡張し、リカレントニューラルネットワーク(RNN)の動作原理についても見識を得る事ができた事である。
CNNは画像分類に良く用いられるニューラルネットワークだが、RNNは時系列データなど、連続しているデータを扱う事が得意で特に言語翻訳に良く用いられるモデルである。RNNは連続したデータを扱うため、過去の複合表現が現在の複合表現に影響を及ぼすと言う新しい課題があった。しかし、RNNを比較する困難さは、CNNを比較する困難さと似た部分があるのでCNNで用いた手法の多くを応用できる。これにより、CCAはその有用な不変性を用いて、CNNに加えRNNの複合表現を学習する理想的なツールになった。
GoogleはCCAを用いてニューラルネットワークを解析するために使用したプログラムをGithubに公開した。我々はこのコードが研究コミュニティがニューラルネットワークの動作原理をよりよく理解するのを助ける事を希望している。
3.一般化と記憶化の違い
機械学習が役に立つためには、学習データになかった今までに見た事がないデータに対しても正確に予測や分類ができるような「一般化」が必要である。
一般化されたニューラルネットワークとそうでないネットワークを区別する要因を理解する事は不可欠であり、これは一般化のパフォーマンスを向上させる新しい方法に繋がる可能性がある。
複合表現の類似性を用いて一般化を予測できるか調べるために、我々は2種類のCNNを研究した。
1)一般化(Generalizing)ネットワーク
CNNは、変更されていない正確なラベルでデータを訓練し、見た事がないデータを予測できるように一般化するように学習させる。
2)記憶化(Memorizing)ネットワーク
CNNは、重複や誤りを混入させ無作為化したラベルでデータセットを訓練させる。ニューラルネットワークは、入力データに法則を見出す事ができないので訓練データを丸暗記しなければならず記憶化に繋がる
我々は2種類のネットワークを複数サンプルで訓練させた。各サンプルはネットワークの初期の重みと訓練データの順序のみが異なる。そして、CCAを使った新手法(詳細は論文参照)を用いて各サンプルと一般化ネットワークと記憶化ネットワークを比較した。
我々は、異なる一般化ネットワークのグループが、記憶化ネットワークのグループよりも、より似通った表現(特に後の方のレイヤーで)に一貫して収束していることを見出した。
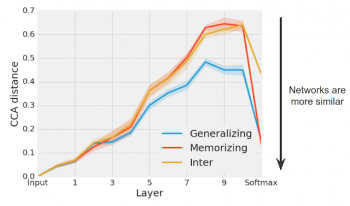
一般化ネットワークのグループ(青)は、記憶化ネットワークのグループ(赤)よりも類似性が高くなる。
CCA距離は、一般化グループ、記憶化グループ、及び記憶化と一般化のペアのグループ間で計算された。ネットワークの最終的な予測を示すソフトマックスでは、各グループのネットワークが同様の予測をするので、一般化および記憶化ネットワークの各グループのCCA距離は大幅に減少する。
恐らく最も驚くべきことに、後方の隠れ層では、記憶化ネットワーク同士の任意のペアの表現距離は、記憶化ネットワークと一般化ネットワークのペアの表現距離(上記のプロットにおける「黄色のInter」)とほぼ同じであった。全く異なるラベルのデータを用いて訓練したにも関わらず、ほぼ同じになったのだ。
直観的には、この結果は、トレーニングデータを記憶する多くの異なる方法(CCA距離がより大きくなる)がある一方で、一般化可能な解を学習する方法が少ないことを示唆している。
今後の作業では、この洞察をネットワークの標準化に利用してより一般化可能なソリューションを学ぶことができるかどうかを検討する予定である。
4.リカレントニューラルネットワークの学習の動作原理の理解
現在は、画像データを訓練したCNNにのみCCAを適用している。しかし、CCAは、学習の過程でも、シーケンスの過程でも、RNNにおける表現上の類似性を計算するために適用することができる。
RNNにCCAを適用し、我々は最初にRNNが以前のCNNの研究で見たのと同じボトムアップ方式による学習を行っているのか調査した。これをテストするために、RNNの各レイヤーでの表現とトレーニング終了時の最終表現との間のCCA距離を測定した。 CNNと同様に、RNNも早期レイヤーから順に収束しており、ボトムアップパターンで収束していることがわかった。

我々の論文のさらなる知見は、より広いネットワーク(例えば、各層でより多くのニューロンを有するネットワーク)が狭いネットワークよりも似たような解決策に収束することを示している。
その他にも、同じ構造であるが学習率が異なる学習済みネットワークは、同様の性能で別個のクラスタに収束するが、内部表現は非常に異なっている事もわかった。
我々はまた、時間の経過とともにRNN表現に影響を与える様々な要因についていくつかの初期の洞察を提供しながら、訓練の間だけではなく、単一シーケンスの過程でRNNの動作原理を解明するためにCCAを適用する予定である。
5.結論
これらの知見は、DNNの機能、一般化、および収束に関する洞察を提供するために、分析ツールおよびDNNの内部表現の比較手法を強化した。しかし、未来の研究では、CNNとRNNの両方のネットワークで表現のどの部分が保存されているか、またこれらの洞察をDNNのパフォーマンスを向上させるために使用できるかどうかを見極めることを望んでいる。
私達はCCAが他のニューラルネットワークについて教えてくれる事を調べるために、論文に使用されたコードを試してみることを他のニューラルネットワーカーに勧めます!
6.人工知能の学習と単なる丸暗記は何が違うのか?関連リンク
1)ai.googleblog.com
How Can Neural Network Similarity Help Us Understand Training and Generalization?
2)CCA入門(正準相関分析入門)
www.jstage.jst.go.jp
3)arxiv.org
Insights on Representational Similarity in Neural Networks with Canonical Correlation
