
1.Omnimattes:動画内の影や砂埃も切出す事ができる最先端の人工知能(1/2)まとめ
・前景と背景の分離を定義するマット画像があると画像やビデオの編集操作が容易になる
・最近の人工知能は画像やビデオ内に自動でマットを作成できるが影や煙には対応できない
・オムニマットは影や煙など撮影シーン内の被写体に関する全てを含んだマットを作成可能
2.オムニマットとは?
以下、ai.googleblog.comより「Introducing Omnimattes: A New Approach to Matte Generation using Layered Neural Rendering」の意訳です。元記事は2021年8月31日、Forrester ColeさんとTali Dekelさんによる投稿です。
オムニ(omni)は「全ての」を意味する接頭辞です。画像データセットなどで、犬や猫などに共通して使われているラベルとしてcarnivore(肉食動物)を見た事がある方もいるかもしれませんが、omnivoreで「雑食動物」になります。ちなみに「草食動物」はherbivore。
omnivoreで検索すると出てきてomniな感じがしたアイキャッチ画像のクレジットはPhoto by Richard Sagredo on Unsplash
画像やビデオの編集操作は、多くの場合、正確なマット(mattes)に依存しています。
マットとは、前景と背景の分離を定義する画像です。
最近のコンピュータービジョン技術では、自然な画像やビデオ内に高品質なマットを作成でき、合成被写界深度の生成、画像の編集と合成、画像からの背景の削除などの実務的なアプリケーションが可能になります。
しかし、ながらこれには基本的な要素が1つ欠けています。影、反射、煙など、被写体が生成する可能性のあるさまざまな風景内の効果は、通常見落とされます。
CVPR 2021で発表された論文「Omnimatte:Associating Objects and their Effects in Video」では、レイヤードニューラルレンダリング(layered neural rendering)を活用してビデオをオムニマットと呼ばれるレイヤー群に分離するマット生成の新しいアプローチについて説明します。
このレイヤーには、被写体だけでなく、撮影シーン内の被写体に関連するすべての効果も含まれます。典型的な最先端のセグメンテーションモデルは、シーン内の被写体、たとえば人や犬のマスクを抽出する事ができますが、今回提案する方法では、地面にうつる影など、被写体に関連する細部も追加して分離、抽出できます。
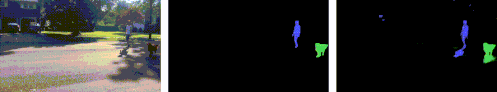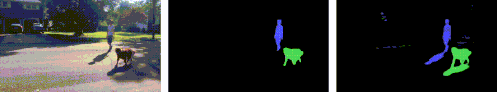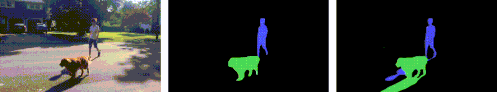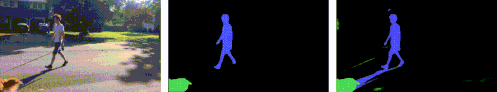
最先端のセグメンテーションネットワーク(MaskRCNNなど)は、入力ビデオを取得し(左)、人や動物用のもっともらしいマスク(中央)を生成しますが、付随する効果を見逃しています。私たちの手法では、被写体だけでなく影も含むマットを生成します。(右:青と緑で視覚化された人と犬の個々のチャネル)
また、セグメンテーションマスクとは異なり、オムニマット(Omnimattes)は、光の反射、水しぶき、タイヤから出る煙など、部分的に透明なソフト効果を捕捉できます。従来のマットと同様に、オムニマットは、広く利用可能な画像またはビデオ編集ツールを使用して操作できるRGBA画像であり、たとえば、砂煙のビデオの背景にテキストを挿入する事など、従来のマットが使用出来た場所ならどこにでも使用できます。

ビデオをレイヤーに分解して処理
オムニマットを生成するために、入力ビデオを一連のレイヤーに分割します。1つは動く被写体毎に、もう1つは静止した背景物体用に追加します。以下の例では、人物用に1つ、犬用に1つ、背景用に1つのレイヤーがあります。従来のアルファ チャンネルを使用して統合すると、これらのレイヤーは1つの入力ビデオとして再現できます。

ビデオの再現に加えて、レイヤーに分解時は各レイヤー用に付随する正しい効果を捕捉する必要があります。例えば、人物の影が犬のレイヤーに表示されてしまったら、統合されたレイヤーは入力ビデオを再現できても、人物と犬の間に追加の効果を挿入すると、明らかなエラーが発生します。
課題は、それぞれを対象とするレイヤーがその対象の効果のみを捕捉し、真のオムニマットを生成できる分解状態(decomposition)を見つけることです。
私たちの解決策は、以前に開発したレイヤード ニューラル レンダリング(layered neural rendering)手法を適用して畳み込みニューラルネットワーク(CNN:Convolutional Neural Network )をトレーニングし、被写体のセグメンテーションマスクと背景ノイズ画像をオムニマットにマッピングすることです。
CNNはその構造により、画像効果間の相関関係を学習する傾向があり、効果間の相関関係が強いほど、CNNは学習しやすくなります。たとえば、上のビデオでは、「人」と「人の影」、および「犬」と「犬の影」の間の空間的関係は、右から左に歩いても保たれています。「人」と「犬の影」、または「犬」と「人の影」の間の空間的関係は、もっと変化(したがって、相関は弱くなります)します。
CNNは最初に強い相関関係を学習するので、これが正しい分解の実現につながります。
3.Omnimattes:動画内の影や砂埃も切出す事ができる最先端の人工知能(1/2)関連リンク
1)ai.googleblog.com
Introducing Omnimattes: A New Approach to Matte Generation using Layered Neural Rendering
2)arxiv.org
Omnimatte: Associating Objects and Their Effects in Video
3)omnimatte.github.io
Omnimatte: Associating Objects and Their Effects in Video

