
1.SeqSNR:ICU患者の臓器機能不全をマルチタスク学習を使って予測(2/2)まとめ
・ICU患者の治療後の状況を正確に予測する事は患者にとっても人員配置計画にとっても重要
・従来の機械学習は特定の有害事象だけを予測するシングルタスク学習が採用されていた
・臓器系間の相互依存性などの競合するリスクを考慮に入れたマルチタスクモデルを採用した
2.SeqSNRとは?
以下、ai.googleblog.comより「Multi-task Prediction of Organ Dysfunction in ICUs」の意訳です。元記事は2021年7月22日、Subhrajit RoyさんとDiana Mincuさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Obi Onyeador on Unsplash
調査結果
SeqSNRは、シングルタスクおよびナイーブマルチタスクと比較して、全体的な識別パフォーマンスをわずかに改善させる事が示されています。わずかではあっても、トレーニングラベルが少ない状況では、パフォーマンスの向上はより重要になります。
有病率はデータセット内で大きく異なるため(たとえば、患者の約38%が人工呼吸器をつけていましたが、CRRT透析を受けていた患者は約3%しか存在しません)、多くの精度指標は適切ではありません。
代わりに、適合率再現曲線の下部の領域面積(AU PRC:area under the precision recall curve)を報告します。この手法は、不均衡なデータが与えられた場合に、より信頼性が高くなります。さらに、ウィルコクソン符号順位検定(Wilcoxon Signed Rank Tests )を実行して、ST学習、共有ボトム(SB:shared-bottom)マルチタスク学習(つまり、ナイーブマルチタスク学習)、およびSeqSNRにペアワイズ比較を行い、固定テストセット全体で統計的に有意な結論を導き出しました。
3つのアーキテクチャ間のパフォーマンスの違いはわずかでしたが、SeqSNRは6つのタスクのうち4つでSTとSBの両方を上回りました。(p値は論文で報告されています)
ラベル効率
私達はマルチタスク学習は、ラベル付けが簡単な補助タスクを使用してメインタスクのパフォーマンスを向上させる事が出来るので、利用可能なデータの少ない状況で役立つ可能性があると仮定しました。
私達はメインタスクに使用したトレーニングラベルの一部のみを使用するタスクとして補助タスクを定義しましたが、補助タスクのためにデータセット全体も利用しました。後者が選択されたのは、電子カルテ(EHR:Electronic Health Records)で確実に情報が捕捉されており、時刻を計測する事が簡単だからです。
このような補助タスクの例は入院です。MIMIC-IIIでは、入院の開始と終了に正確なタイムスタンプが付けられます。その一方、人工呼吸装置装着の開始と終了には、タイムスタンプが確実に記録されているわけではありません。
そこで、専門家が定義した経験則に基づいて一連のルールを定義し、人工呼吸器関連の設定の複数の情報ソースと、人工呼吸装置の装着を記録するEHRデータセットの生理学的測定値を使用して人工呼吸装置を装着していた時間を決定しました。
新しい評価項目のためのルール開発には時間がかかり、データセットを専門家が手動レビューする作業も含まれていました。データセットに徹底的にラベルを付けることの難しさから、ラベル付けされたデータの1~10%のみでモデルのパフォーマンスをテストすることになり、その結果、モデルのパフォーマンスが低下しました。
「補助タスク」は、100%ラベル付けされており、メインタスク(1~10%ラベル付け)と一緒に使用してマルチタスクモデルを共同でトレーニングし、全体的なパフォーマンスを向上させることができるため、このシナリオで役立ちます。
トレーニングラベルの1%、5%、および10%を使用して、主要評価項目AKI、人工呼吸器、CRRT透析、および血管作用薬を選択しました。補助タスク(lab、vitals、死亡率、LoS)用のラベルの100%も共に使用しています。
主要評価項目のラベルの割合が減少すると、STとSeqSNRの両方のパフォーマンスが低下しましたが、SeqSNRはすべてのタスクとすべてのトレーニングデータ削減の割合でSTを上回り、すべてのケースで統計的に有意なパフォーマンスの向上が見られました。
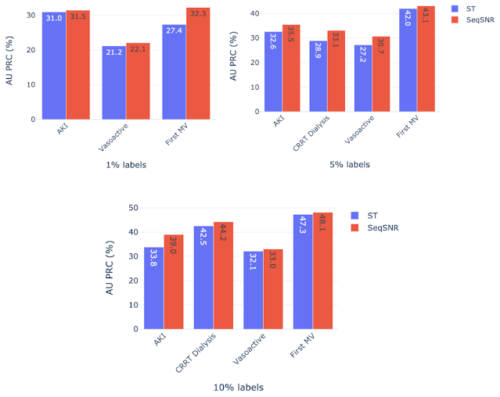
識別性能を示すラベル効率の結果
補助タスクは全てのトレーニングラベルにアクセスできますが、主要評価項目のトレーニングデータセットは1%、5%、および10%に削減されています。
これは、EHRデータセット内の評価項目にラベル注釈を付けることが困難であり、医師による評価が頻繁に必要になることを考えると、有用な発見です。多数の評価項目で使用する特徴(滞在期間や死亡率など)のラベル付けが簡単な場合は、異なる注釈(人工呼吸器など)のより難しい評価項目を手動でまとめる必要性を減らすことができます。
サブグループのパフォーマンス
使用されたMIMIC-IIIデータセットのバージョンには、性別と年齢のラベルが含まれていましたが、人種に関する情報は含まれておらず、民族に関する情報は限られていました。年齢と性別のサブグループ全体で、選択したすべてのモデルのパフォーマンスを計算しました。データセットに実例がほとんどないシナリオでは、MTLモデル(SBモデルとSeqSNRの両方)がSTよりも優れていることがよくあります。例外はありますが、平均して、すべてのモデルは年齢と性別のサブグループ間で比較的バランスが取れているようです。詳細なパフォーマンスの内訳については、論文の補足セクションを参照することをお勧めします。
次のステップ
本研究は、一連の標準的なEHR予測タスクに関するSeqSNRの概念実証です。今回の研究で使用したコードは、githubで公開されています。そして、うまくいけば、臨床的推論に触発されたEHRマルチタスクおよびその他のディープラーニングアーキテクチャのさらなる研究を刺激するでしょう。
将来的には、タスクのさまざまな組み合わせ、さまざまな期間、さまざまなデータセットでSeqSNRのパフォーマンスを評価することが重要になります。このプロジェクトの潜在的な成長のもう1つの領域は、追加の人口情報、人種、民族などを含むデータセットを含めることによってサブグループ分析を拡張することです
また、これらは方法論を紹介するために設計された試作モデルであり、これらのツールを本番環境に展開するには、より厳密な評価が必要であることも強調しておきます。
謝辞
本研究には、研究者、ソフトウェアエンジニア、臨床医、および部門の枠を超えた貢献者からなる学際的なチームによる共同作業が含まれていました。
共著者に感謝します:GoogleのEric Loreaux, Anne Mottram, Ivan Protsyuk, Natalie Harris, Sebastien Baur, Yuan Xue, Jessica Schrouff, Ali Connell, Alan Karthikesalingam, Martin Seneviratne。DeepmindのNenad Tomasev。ユニヴァーシティ・カレッジ・ロンドンのHugh Montgomery。
また、Google ResearchのZhe Zhao、Google HealthのKathryn Rough, Cian Hughes, Megumi Morigami そして Doris Wongの意見とレビューに感謝します。そして、研究コミュニティのためにこのオープンアクセスデータセットをまとめてくれているMIMICチームにも感謝します。
3.SeqSNR:ICU患者の臓器機能不全をマルチタスク学習を使って予測(2/2)関連リンク
1)ai.googleblog.com
Multi-task Prediction of Organ Dysfunction in ICUs
2)academic.oup.com
Multitask prediction of organ dysfunction in the intensive care unit using sequential subnetwork routing
3)github.com
google / ehr-predictions


MIMIC-IIIデータセットでのシングルタスク(ST)、共有ボトム(SB)、およびSeqSNRのパフォーマンスの比較