
1.深層強化学習研究の計算コストの削減(2/2)まとめ
・従来の制御環境ではRainbowの論文と異なり分散RLは単体では性能向上に貢献しなかった
・Rainbowに採用された各アルゴリズムの貢献度は適用環境ごとに異なる可能性がある
・計算量の少ない環境もアルゴリズムのパフォーマンスや動作を徹底的に分析するのに役立つ
2.少ない予算で強化学習を研究する方法
以下、ai.googleblog.comより「Reducing the Computational Cost of Deep Reinforcement Learning Research」の意訳です。元記事は2021年7月13日、Samuel Castroさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by David Brooke Martin on Unsplash
実際、Rainbowの論文で行われたALEを用いた実験結果とは対照的に、従来の制御環境では、分散RL(distributional RL)は別の部品と組み合わせた場合にのみ改善をもたらします。
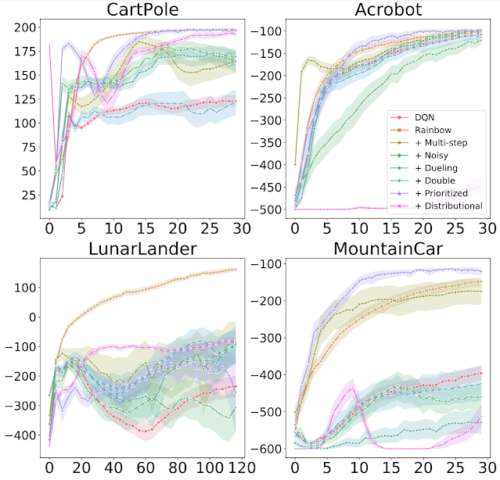
各図は、さまざまな部品をDQNに追加したときのトレーニングの進行状況を示しています。 x軸はトレーニングステップ、y軸はパフォーマンスです。(高いほど良いスコア)
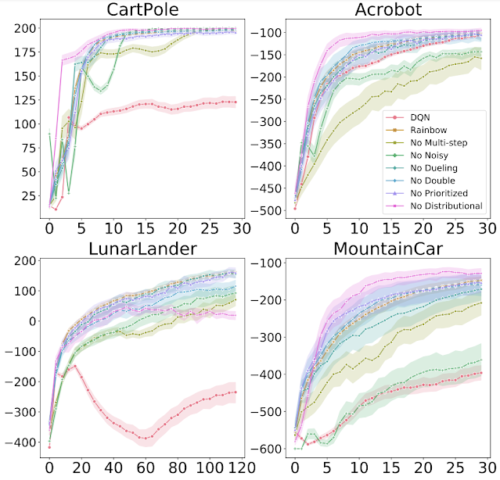
各図は、Rainbowからさまざまな部品を削除したときのトレーニングの進行状況を示しています。x軸はトレーニングステップ、y軸はパフォーマンスです。(高いほど良いスコア)
また、5つの小型化されたAtariゲームのセットで構成されるMinAtar環境でRainbow実験を再実行したところ、質的に類似した結果が見つかりました。
MinAtarゲームは、元のRainbowアルゴリズムが評価された通常のAtari 2600ゲームよりもトレーニングが約10倍高速に実行できますが、ゲームの変遷やエージェントへの画素ベースの入力など、いくつかの興味深い側面を共有しています。そのため、従来の制御環境と完全なAtari 2600ゲームの間の、やりがいのある中間レベルの環境を提供します。
まとめて見ると、結果は元のRainbowペーパーの結果と一致していることがわかります。
つまり、各アルゴリズムの有無から生じる影響は、環境ごとに異なる可能性があります。さまざまなアルゴリズムのトレードオフのバランスをとる単一のエージェントを考えると、私達のRainbowのバージョンは「全ての部品を組み合わせると全体的に優れたエージェントが生成される」という点で、元の論文バージョンと一致する可能性があります。
ただし、さまざまなアルゴリズムの有無のバリエーションには、より徹底的な調査に値する重要な詳細があります。
Rainbowを越えて
DQNが導入されたとき、それはHuber損失とRMSProp Optimizerを利用していました。研究者の努力のほとんどは他のアルゴリズム設計の決定に費やされているため、DQNに基づいて構築する場合、研究者はこれらと同じ選択肢を使用するのが一般的です。
これらの仮定を再評価するという精神で、低コストで小規模な従来の制御およびMinAtar環境でDQNが使用する損失関数とオプティマイザーを再検討しました。
近年、最も人気のあるオプティマイザーの選択肢であるAdamオプティマイザーを、より単純な損失関数である平均二乗誤差損失(MSE:Mean-Squared Error loss)と組み合わせて使用して、いくつかの初期実験を実行しました。
新しいアルゴリズムを開発するとき、オプティマイザーと損失関数の選択は見過ごされがちなので、すべての従来の制御環境とMinAtar環境で劇的な改善が見られたことに驚きました。
したがって、完全なALEセット(60 Atari 2600ゲーム)で2つのオプティマイザー(RMSPropとAdam)を2つの損失(HuberとMSE)と組み合わせるさまざまな方法を評価することにしました。私達はAdam + MSEはRMSProp + Huberよりも優れた組み合わせである事を発見しました。
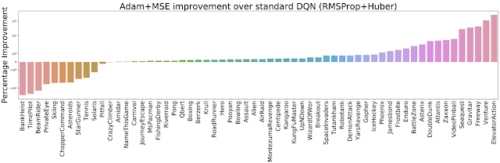
Adam + MSEがデフォルトのDQN設定(RMSProp + Huber)を超える改善を測定しました。高いほど良いスコアです。
さらに、さまざまなオプティマイザと損失の組み合わせを比較すると、RMSPropを使用すると、Huber損失のパフォーマンスがMSEよりも向上する傾向があることがわかります。(オレンジ色の実線と点線のギャップで示されています)。
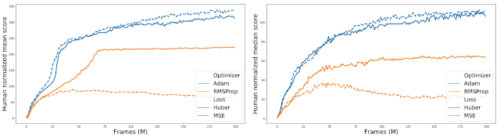
さまざまなオプティマイザーと損失の組み合わせの比較。60のAtari2600ゲームすべてにわたって集計された正規化されたスコアです
結論
限られた計算予算で、Rainbowの論文で見つかった発見を高レベルで再現し、新しく興味深い現象を発見することができました。
明白な事ですが、最初に何かを発見するよりも、何かを再調査する方がはるかに簡単です。しかし、この研究の意図は、中小規模の環境に関する実証研究の関連性と重要性について議論することでした。これらの計算量の少ない環境は、新しいアルゴリズムのパフォーマンス、動作、および複雑さをより重要かつ徹底的に分析するのに役立つと考えています。
大規模なベンチマークにそれほど重点を置かない事を求めているわけではありません。私たちは単に、研究者に調査の貴重なツールとして小規模な環境を検討するように促し、レビューアには小規模な環境に焦点を当てた実証的研究を却下しないように促しています。
そうすることによって、私たちが行う実験が地球環境へ与える影響を減らすことができます。それに加えて、私たちは、研究環境のより明確な全体像を把握できるようにし、多様でしばしば資金不足になるコミュニティに属する研究者の障壁を減らします。これは、私たちのコミュニティと科学の進歩をより強くするのに役立ちます。
謝辞
この論文の第一著者であるJohanに、これを見抜いた彼の努力と粘り強さに感謝します!
また、この研究について洞察に満ちたコメントを寄せてくれたMarlos C. Machado, Sara Hooker, Matthieu Geist, Nino Vieillard, Hado van Hasselt, Eleni TriantafillouそしてBrian Tannerに感謝します。
3.深層強化学習研究の計算コストの削減(2/2)関連リンク
1)ai.googleblog.com
Reducing the Computational Cost of Deep Reinforcement Learning Research
2)arxiv.org
Rainbow: Combining Improvements in Deep Reinforcement Learning
Revisiting Rainbow: Promoting more Insightful and Inclusive Deep Reinforcement Learning Research
3)github.com
kenjyoung / MinAtar

