
1.HuBERT:話言葉を音声から直接学習する自己教師あり特徴表現学習(1/2)まとめ
・他の人の話を聞いたり交流するだけで音声をよりよく認識して学習するAIは大きな目標
・実現には単語だけでなく話者の個性、感情、割り込みなど、多くを分析する必要がある
・BERTのようなマスク言語モデルの学習手法を音声データに適用しHuBERTを開発
2.HuBERTとは?
以下、ai.facebook.comより「HuBERT: Self-supervised representation learning for speech recognition, generation, and compression」の意訳です。元記事は2021年6月15日、Abdelrahman Mohamedさん、Wei-Ning Hsuさん、Kushal Lakhotiaさんによる投稿です。
HuBERTの命名は後半部分はBERTからだと思いますが、おそらくラテン語のフーベルトゥス(Hubertus)を意識していると思います。Hubertusは、フーベルト、ヒューバートなどの男性名の由来元でもありますが、キリスト教の聖人であり、ハンター、数学者、機械工、眼鏡技師、金属労働者、精密機器メーカー、などの守護聖人として知られています。
アイキャッチ画像はフーベルトゥスが鹿の角の間に十字を見出して天啓を授かったとの言い伝えを描いた絵でArtveeより「The Vision Of St. Hubert(1916)」 作者はEgon Schieleさんです。
この研究は何ですか?
多くのAI研究にとっての北極星(訳注:北極星(North Star)は昔から正しい方角を知るための目印とされてきたので、あらゆる人が参照している唯一の指標の意です)は、赤ちゃんが母国語を学ぶのと同じように、他の人の話を聞いたり交流したりしているだけで、音声をよりよく認識して理解して継続的に学習していく事です。
これを実現するためには、誰かが話す単語を分析するだけでなく、それらの単語がどのように配信されるかから、話者の個性、感情、ためらい、何かの割り込みなど、他の多くの手がかりも分析する必要があります。
さらに、人間のように状況を完全に理解するには、AIシステムは、音声信号に重なるノイズ(笑い声、咳、舌づつみ、乗り物などの背景音、鳥のさえずりなど)を区別して解釈する必要があります。
これらのタイプの豊富な語彙および非語彙情報を音声でモデル化するために、自己教師あり音声特徴表現を学習する新しいアプローチであるHuBERTをリリースします。HuBERTは、音声認識、生成、および圧縮のための音声特徴表現学習の最先端手法に匹敵するか、それを上回ります。
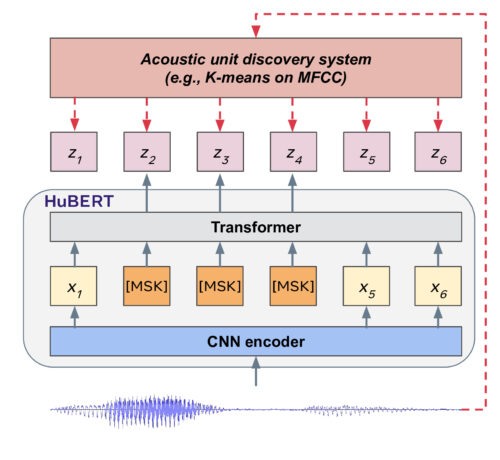
これを行うために、私たちのモデルはオフラインのk-meansクラスタリングステップを使用し、マスクされたオーディオセグメントの適切なクラスタを予測することによって音声入力の構造を学習します。HuBERTは、クラスタリングと予測のステップを交互に行うことで、学習した離散表現を段階的に改善します。
HuBERTのシンプルさと安定性は、自然言語処理と音声研究者が学習した離散表現をより広く採用するのに役立ちます。
さらに、HuBERTが学習したプレゼンテーションの品質により、さまざまな下流工程の音声アプリケーションへの展開が容易になります。
HuBERTはどのように動作するのですか?
HuBERTは、Facebook AIの自己教師あり視覚学習であるDeepClusterから発想を得ています。連続する音声データの一部をマスクしてその予測をします。例えれば、GoogleのBERT(Bidirectional Encoder Representations from Transformers)の学習手法を音声データに適用したものです。
HuBERTは、オフラインクラスタリング手順を使用して、マスク言語モデルの事前トレーニング用にノイズの多いラベルを生成します。具体的には、HuBERTは、一部がマスクされた連続する音声データの特徴表現を使用して、事前に決定されたクラスタ割り当てを予測します。予測された損失はマスクされた領域にのみ適用されます。マスクされた入力のターゲットを正しく推測するために、モデルはマスクされていない入力の適切な高レベルな特徴表現を学習する必要があります。
HuBERTは、連続する音声入力から音響モデルと言語モデルの両方を学習します。まず、モデルは、マスクされていないオーディオ入力を意味のある連続潜在特徴表現にエンコードする必要があります。これは、古典的な音響モデリングの問題に対応します。
第二に、予測誤差を減らすために、モデルは学習された特徴表現間が離れていても時間的関係を捕捉する必要があります。
本研究の動機となる重要な洞察の1つは、k-meansマッピングの一貫性の重要性です。これは音声入力を個別のターゲットに変換する際の正確さだけでなく、モデルが入力データの連続構造のモデリングに集中できるようにします。
例えば、初期のクラスタリング反復作業で/k/と/g/の発音が区別できない場合、両方の発音を含む単一のスーパークラスターができます。予測損失は、他の子音と母音がこのスーパークラスタと連携して単語を形成する方法をモデル化する特徴表現を学習します。
その結果、次のクラスタリングの反復は、新しく学習された特徴表現を使用して、より良いクラスターを作成します。私たちの実験は、クラスタリングと予測のステップを交互に行うことにより、特徴表現が徐々に改善されることを示しています。
3.HuBERT:話言葉を音声から直接学習する自己教師あり特徴表現学習(1/2)関連リンク
1)ai.facebook.com
HuBERT: Self-supervised representation learning for speech recognition, generation, and compression
2)arxiv.org
HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units
3)github.com
fairseq/examples/hubert/

