
1.ディープなネットワークもワイドなネットワークも同じ事を学習しているのか?(2/2)まとめ
・深淵広大なネットワークには非常に類似した特徴表現を持つ連続したレイヤーが出現する
・これはブロック構造と呼ばれデータセットサイズに対するモデルサイズに関係がある
・ブロック構造有モデルの特徴表現は固有となるがブロック構造無しモデルは類似性を持つ
2.ブロック構造とは?
以下、ai.googleblog.comより「Do Wide and Deep Networks Learn the Same Things?」の意訳です。元記事の投稿は2021年5月4日、Thao Nguyenさんによる投稿です。
アイキャッチ画像のクレジットPhoto by Shot by Cerqueira on Unsplash
ブロック構造の出現
より深いまたはより広いネットワークの特徴表現ヒートマップで際立っているのは、非常に類似した特徴表現を持つ連続したレイヤーの大規模なセットの出現です。これは、ヒートマップに黄色の正方形(つまり、CKAスコアが高い領域)として表示されます。
この現象は、ブロック構造と呼ばれ、基盤となるレイヤーが、ネットワークの特徴表現を期待通りに段階的に改良する際に効率的でない可能性があることを示しています。実際、タスクのパフォーマンスがブロック構造内で停滞するため、最終的なパフォーマンスに影響を与えることなく、いくつかの基礎となるレイヤーを刈り込みできる事が示されています。
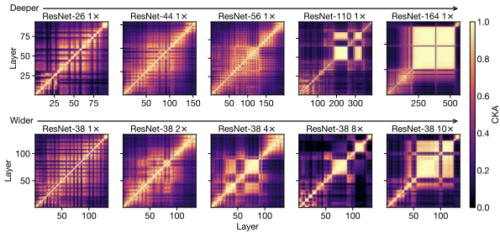
ブロック構造(非常に類似した特徴表現を持つ大きくて連続したレイヤーのセット)は、幅または深さが増すにつれて出現します。
各ヒートマップパネルは、単一のニューラルネットワーク内のレイヤーのすべてのペア間のCKAの類似性を示しています。
そのサイズと位置はトレーニングの実行ごとに異なる可能性がありますが、ブロック構造は、より大きなモデルで一貫して発生する確実性の高い現象です。
追加の実験で、ブロック構造が「モデルの絶対サイズ」よりも「トレーニングデータセットのサイズに対するモデルのサイズ」に関係がある事を示します。トレーニングデータセットのサイズを小さくすると、浅くて狭いネットワークにもブロック構造が表示され始めます。
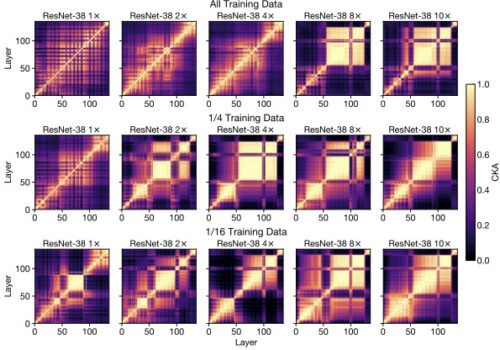
ネットワーク幅を増やし(各段で右方向)、データセットサイズを減らす(各列を下方向)と、(特定のタスクに関する)相対的なモデル容量が効果的に膨らむため、ブロック構造が小さなモデルにも表示され始めます。
更なる分析を通じて、ブロック構造が、その基礎となる特徴表現の主要な主成分を保存および伝播することから生じることを実証することもできます。詳細については、私達の論文を参照してください。
モデル間での特徴表現の比較
更に進んで、様々なランダム初期化と様々なアーキテクチャのモデル全体の特徴表現に対する深さと幅の影響を調査し、ブロック構造の存在有無が大きな違いをもたらすことを発見しました。
アーキテクチャが異なるにもかかわらず、ブロック構造のないワイドモデルとディープモデルは互いの特徴表現に類似性を示し、対応するレイヤーはモデル内でほぼ同じように比例する深度になります。ただし、ブロック構造が存在する場合、その特徴表現は各モデルに固有です。これは、全体的なパフォーマンスが類似しているにもかかわらず、ブロック構造を持つ各ワイドモデルまたはディープモデルが、入力から出力への一意のマッピングを取得することを示しています。

小さいモデル(ResNet-38 1xなど)の場合、異なる初期化でのCKA(非対角線上の要素)は、単一モデル内のCKA(対角線上の要素)に非常に似ています。対照的に、より広く深いモデル(ResNet-38 10x, ResNet-164 1xなど)のブロック構造内の特徴表現は、トレーニングの実行間で違いが大きく異なります。
ワイドモデルとディープモデルのエラー分析
ワイドモデルとディープモデルの学習済み特徴表現の属性を調査した後、次に、それらが出力予測の多様性にどのように影響するかを理解しようとしました。様々なアーキテクチャのネットワークの母集団をトレーニングし、各アーキテクチャ構成がエラーを起こす傾向があるテストセットのサンプルを特定します。
CIFAR-10データセットとImageNetデータセットの両方で、同じ平均精度を持つワイドモデルとディープモデルは、サンプルレベルの予測で統計的に有意な差を示しています。同じ観察がImageNetのクラスレベルのエラーにも当てはまり、幅広いモデルは風景(scenes)に対応するクラスを識別する際に小さな優位性を示し、深いネットワークは消費財(consumer goods)で比較的正確です。
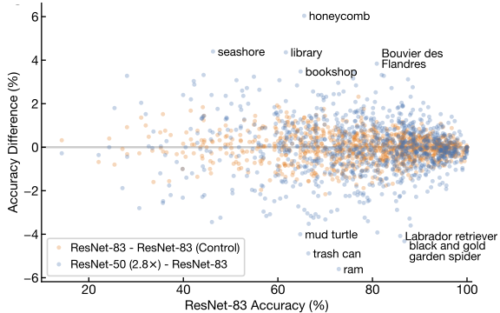
幅(y軸)または深さ(x軸)が増加したモデル間のImageNetのクラス毎の違い。
オレンジ色の点は、ResNet-83(1x)の50の異なるランダム初期化の2つのセット間の違いを反映しています。
結論
内部特徴表現に対する深さと幅の影響を研究する際に、ブロック構造現象を明らかにし、モデル容量との関係を示しました。また、ワイドモデルとディープモデルがクラスレベルとサンプルレベルで体系的な出力の違いを示すことも示しました。これらの結果の詳細と追加の洞察については、論文を確認してください。
トレーニング中にブロック構造がどのように発生するか、現象が画像分類以外の領域で発生するかどうか、内部特徴表現に関するこれらの洞察がモデルの効率と一般化にどのように役立つかなど、これらの調査結果が示唆する多くの興味深い未解決の質問に興奮しています。
謝辞
これはMaithra RaghuとSimon Kornblithとの共同作業です。特徴表現ヒートマップを視覚化してくれたTom Smallに感謝します
3.ディープなネットワークもワイドなネットワークも同じ事を学習しているのか?(2/2)関連リンク
1)ai.googleblog.com
Do Wide and Deep Networks Learn the Same Things?

